 7,153
7,153 新装了个 openstack-dashboar 12.0.3 ,切换主题到material总是不成功,直接设置cookie:
theme=material
就可以了
openstack-dashboar 12.0.3似乎没有汉化包
新装了个 openstack-dashboar 12.0.3 ,切换主题到material总是不成功,直接设置cookie:
theme=material
就可以了
openstack-dashboar 12.0.3似乎没有汉化包
错误信息:
查看卷列表时,dashboard提示: 无法获取连接信息 ; 英文提示应该是: Unable to retrieve attachment information.
查看日志:
发现一个卷是挂在某个实例上的,但是实例早被删掉了,所以“无法获取连接信息”;
实例ID: a95f316f-aeb7-40ce-8887-9145499518fc
卷ID: 7f75f270-17a9-4694-aff3-70c950f9c9b5
解决办法:
直接从cinder数据库中修改该卷的相关信息,然后删掉,相关表:
volume_attachment
volumes
sql 语句:
|
1 |
update volume_attachment set attach_status='detached' where instance_uuid='a95f316f-aeb7-40ce-8887-9145499518fc'\G |
|
1 |
update volumes set status='available', attach_status='detached' where id='7f75f270-17a9-4694-aff3-70c950f9c9b5'\G |
相关代码:
/usr/share/openstack-dashboard/openstack_dashboard/dashboards/project/volumes/tables.py 598 行
列出所有安全组:
|
1 |
openstack security group list |
列出所有名叫default的安全组的ID:
|
1 |
openstack security group list -fjson|jq -r '.[]|select(.Name == "default")|.ID' |
列出指定安全组下的所有规则: (–long 显示每条规则的方向,默认不显示方向)
|
1 |
openstack security group rule list --long bc462cd9-1957-4a33-ac22-d3941e5113b5 |
可以通过–ingress –egress 只显示指定方向上的规则; 通过 –protocol 显示指定协议相关的规则
实际应用:
检查是否所有的“default” 安全组都设置了允许所有tcp、udp都可以主动外出的规则:
|
1 2 3 4 5 |
openstack security group list -fjson|jq -r '.[]|select(.Name == "default")|.ID'| while read id; do echo $id; openstack security group rule list --long $id -f json |jq -r '.[]|select((.["IP Protocol"] == "tcp" or .["IP Protocol"] == "udp") and .["IP Range"] == "0.0.0.0/0" and .["Direction"] == "egress" and .["Port Range"] == "1:65535" and .["Ethertype"] == "IPv4") |.["IP Protocol"]' echo done |
结果输出:
|
1 2 3 |
1bfd33d7-6278-4718-9680-fd6f3328561d tcp udp |
如果输出了tcp和udp就意味着是正确的
添加安全组规则:
允许所有tcp主动外出访问:
|
1 |
openstack security group rule create --protocol tcp --remote-ip 0.0.0.0/0 --dst-port "1:65535" --egress --ethertype IPv4 --description "allow all tcp active request" eb9dd2e8-129d-4135-bee8-f92744f5fbdd |
如下图: 虚拟机管理器和计算主机中显示的主机的名字不同,为什么呢?
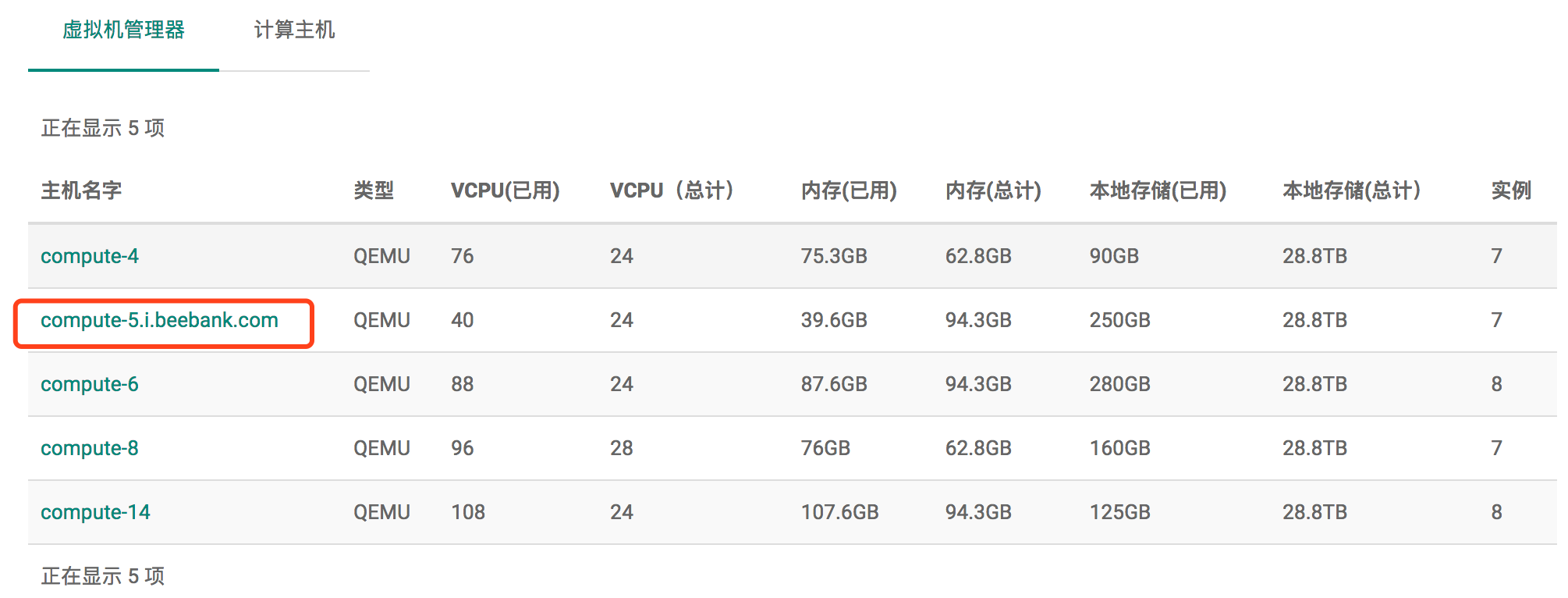
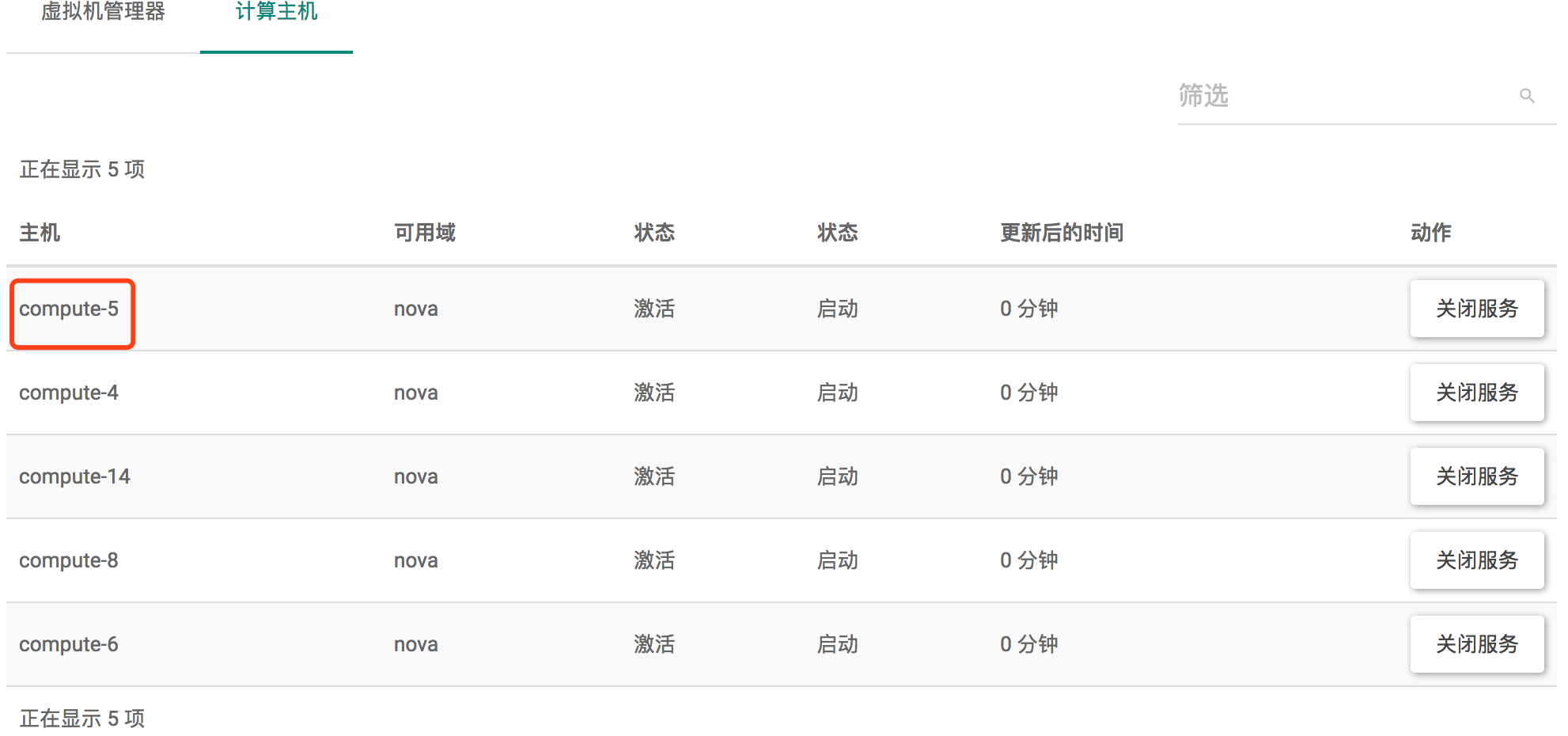
说明:
虚拟机管理器说的是hypervisor,具体来讲就是libvirtd
主机说的是虚拟机管理器所在的宿主机,就是我们所谓的计算节点
二者的信息都是记录在nova.compute_nodes 表中的,二者都没有唯一约束;
当然,host是不会重复的;特殊情况下hypervisor_hostname 重复是有可能的; 从dashboard来看,节点资源是hypervisor的,而不是host的。
而且也可以存在一个host上有多个虚拟机管理器的情况,一个nova-compute接到任务后,可以通过不同的虚拟机管理器来创建虚拟机
分析:
不同计算节点上使用相同hypervisor_hostname时,hypervisor将拥有了多个机器的资源,那么虚拟机调度时参考hypervisor_hostname的资源的话,虚拟机分配的任务最终会被分配到哪个host上呢?毕竟不同host上都有nova-compute进程的; 另,上报资源时使用的是node的uuid还是host还是hypervisor_hostname?
node的uuid又是如何生成的呢?
hypervisor_hostname 是如何获取到的呢?hypervisor_hostname是不是第一次注册的时候写入后来就不再修改了呢?
主机资源是记录在 nova_api.resource_providers 表中的:
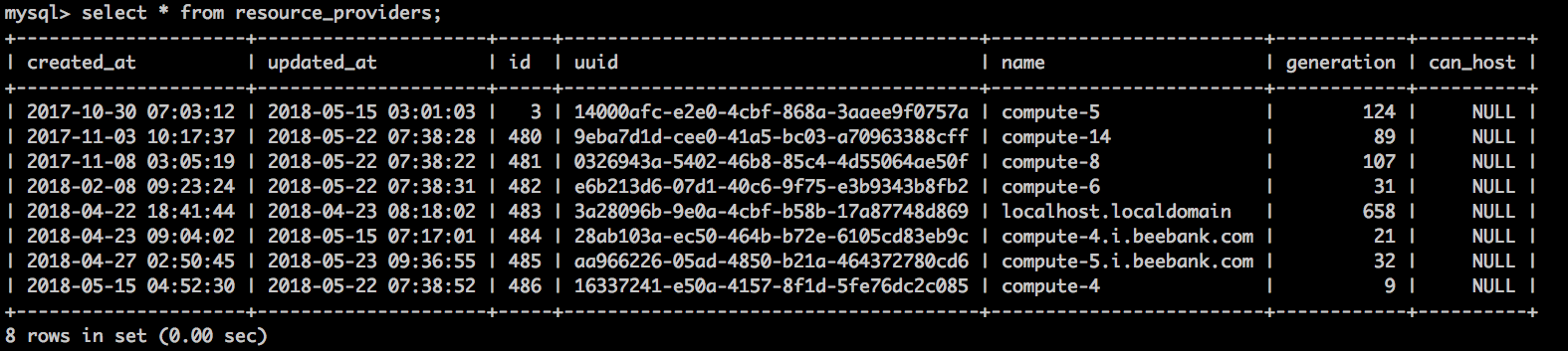
当然,只有nova.compute_nodes 表中记录的uuid才是有效的resource_providers,才会被dashboard显示
为什么node节点的hostname已经修改了,虚拟机管理器中显示的还是以前的名字?
nova-compute.log 中会有错误信息:
|
1 |
2018-05-07 14:53:44.561 3257 ERROR nova.virt.libvirt.host [req-4cf04c1b-8b6f-4ce9-8832-185720825fbc - - - - -] Hostname has changed from compute-5.i.beebank.com to compute-5. A restart is required to take effect. |
问题: 谁和谁不一致?重启谁?
解决办法:
比较: hostname 和virsh hostname的结果:

二者是不同的,前者的信息是从libvirtd中获取到的,也就是说,libvirtd中显示的主机名和当前的主机名不一致,需要重启libvirtd, 相关逻辑:
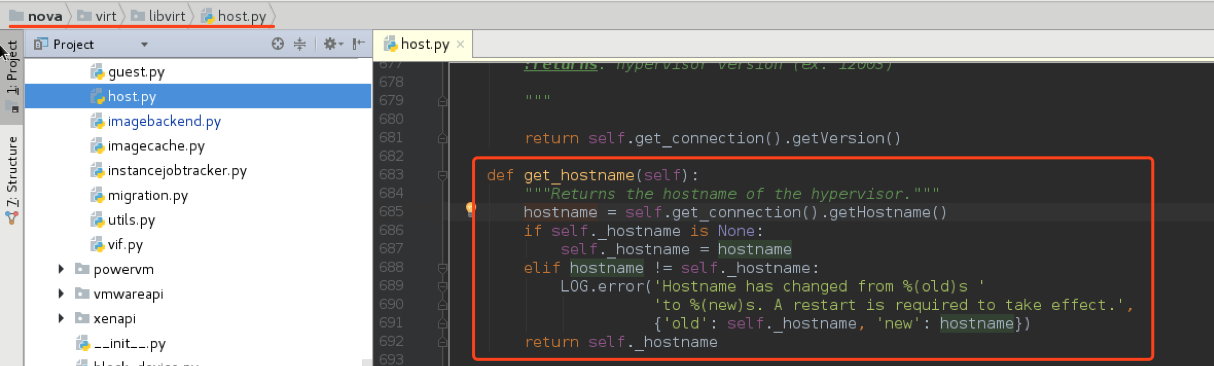
问题:
总结:
注意:
本人使用的owncloud版本号: 8.2.8
第一步:
使用admin账号在“管理”部分开启外部存储配置:

第二步:
在任意账号(也可以是管理员账号)配置外部存储:

注意:
问题:
|
1 |
openstack --os-project-name openstack-test object delete test . |
owncloud + openstack 对象存储的好处:
|
1 2 |
yum install davfs2 -y mount -t davfs http://pan.i.beebank.com/remote.php/webdav/sa-software/rpm-sources /data2/rpmbuild-sources |
参考:
gnocchi-api 访问基本在10s +, why ?
gnocchi-api 使用了 wsgiref , wsgiref 使用了 :
/usr/bin/gnocchi-api:
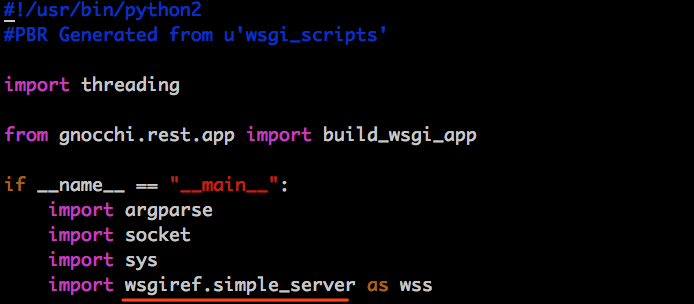
|
1 |
server = wss.make_server(args.host, args.port, build_wsgi_app()) |
/usr/lib64/python2.7/wsgiref/simple_server.py :

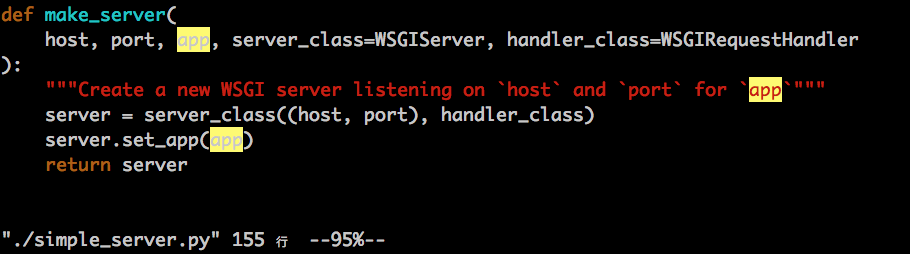

(这里提到了个REMOTE_HOST的环境变量,含义就是“REMOTE_ADDR 对应的域名”, 而 address_string() 的命名也是ip地址对应的域名的意思,因为绝大部分的ip地址是反解不到域名的,所以,这个逻辑基本可以注释掉,不过,直接修改人家的代码不大好)
然而上面的 WSGIRequestHandler 基本上会执行到get_environ() , 进而执行到 BaseHTTPServer.py 中的 self.address_string() ,如下:

address_string() 函数又调用了 /usr/lib64/python2.7/socket.py 中的 getfqdn(), 如下:
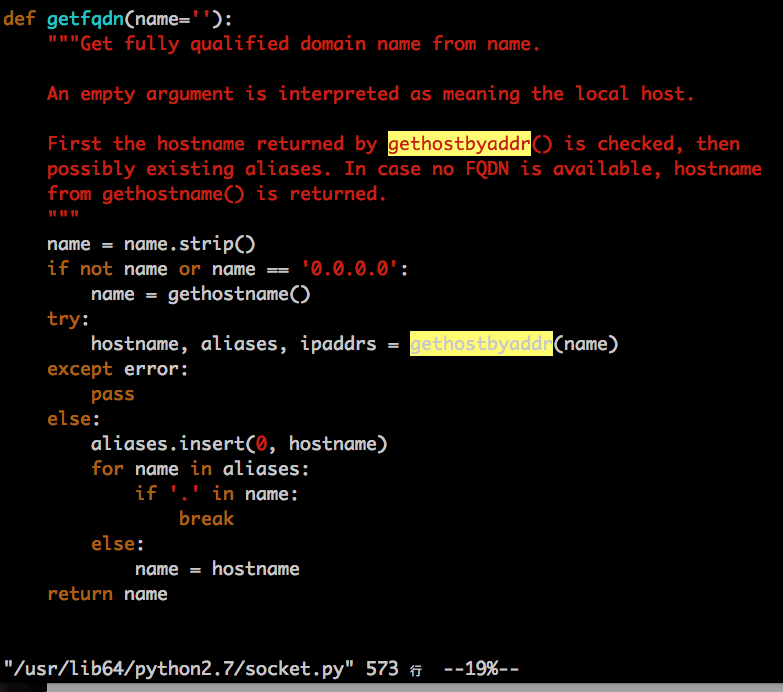
然后就肯定会执行到gethostbtaddr() 了,该函数的具体实现又是什么逻辑呢? socket.py import了 _socket 模块中的所有函数,而gethostbyaddr()正是_socket 模块实现的,_socket 模块的实现见: /usr/lib64/python2.7/lib-dynload/_socketmodule.so , 可见,这是一个c实现的so文件,稍后再看:
测试发现,该函数当遇到IP地址时,肯定会做一次反向地址解析,反向地址解析不是所有dns都能支持的很好的,有些能快速返回,有些却不能(具体原因,稍后再查),比如: 公网地址的反向地址解析可以很快返回,私网地址的反向地址解析就很慢
解决办法:
办法一: 在 dns 上给自己的IP地址添加反向地址解析,这样反向地址解析就可以很快; 给每个IP地址都添加反向地址解析的话,比较麻烦,最好能有一个更好的办法,让某一类IP地址能直接返回错误,或返回一个自定义的域名; 这个办法的优点是: 不需要修改程序 ; 如果搞不定dns,那就修改程序吧
办法二: 修改/usr/lib64/python2.7/BaseHTTPServer.py ,在 address_string() 中直接返回host,而不进行socket.getfqdn(host) 的调用
办法三: 修改 /usr/lib64/python2.7/socket.py 中的 getfqdn() 函数,对于ip地址的情况,不再调用 gethostbyaddr()
办法四: 其实,不是特别有信心的话,不要修改的太底层,没准儿影响到别的程序的; 更好的办法是:
在 /usr/bin/gnocchi-api 中wss.make_server(…) 时,提供了三个参数,还有两个参数是可以定制的,我们可以自己在 /usr/bin/gnocchi-api 中实现一个 MyWSGIRequestHandler ,继承自./simple_server.py 中的WSGIRequestHandler , 然后覆盖其中的address_string() 方法即可
按照办法四 修改后的 /usr/bin/gnocchi-api 如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
#!/usr/bin/python2 #PBR Generated from u'wsgi_scripts' import threading from gnocchi.rest.app import build_wsgi_app from wsgiref.simple_server import WSGIRequestHandler class GnocchiWSGIRequestHandler(WSGIRequestHandler): def address_string(self): return self.client_address[0] if __name__ == "__main__": import argparse import socket import sys import wsgiref.simple_server as wss my_ip = socket.gethostbyname(socket.gethostname()) parser = argparse.ArgumentParser( description=build_wsgi_app.__doc__, formatter_class=argparse.ArgumentDefaultsHelpFormatter, usage='%(prog)s [-h] [--port PORT] [--host IP] -- [passed options]') parser.add_argument('--port', '-p', type=int, default=8041, help='TCP port to listen on') parser.add_argument('--host', '-b', default='', help='IP to bind the server to') parser.add_argument('args', nargs=argparse.REMAINDER, metavar='-- [passed options]', help="'--' is the separator of the arguments used " "to start the WSGI server and the arguments passed " "to the WSGI application.") args = parser.parse_args() if args.args: if args.args[0] == '--': args.args.pop(0) else: parser.error("unrecognized arguments: %s" % ' '.join(args.args)) sys.argv[1:] = args.args server = wss.make_server(args.host, args.port, build_wsgi_app(), handler_class = GnocchiWSGIRequestHandler) print("*" * 80) print("STARTING test server gnocchi.rest.app.build_wsgi_app") url = "http://%s:%d/" % (server.server_name, server.server_port) print("Available at %s" % url) print("DANGER! For testing only, do not use in production") print("*" * 80) sys.stdout.flush() server.serve_forever() else: application = None app_lock = threading.Lock() with app_lock: if application is None: application = build_wsgi_app() |
测试发现,访问确实快多了,不再感觉到延迟了
场景,用docker做开发用的虚拟机,每个docker都有一个可以公开访问的IP地址。
由于docker和宿主机共享内核,一不小心可能会把整个宿主机搞挂,而且,docker热迁移也是个难题,所以,尽管openstack马上可以支持docker,我也不想让docker直接部署在计算节点;我的思路是,将docker部署在openstack管理的kvm虚拟机上,这样还能通过热迁移kvm的方式将容器迁移到别的计算节点。
注意事项:
现象:
openstack中创建的vpc网络中,虚拟机不能dhcp到IP地址,抓包分析如下:
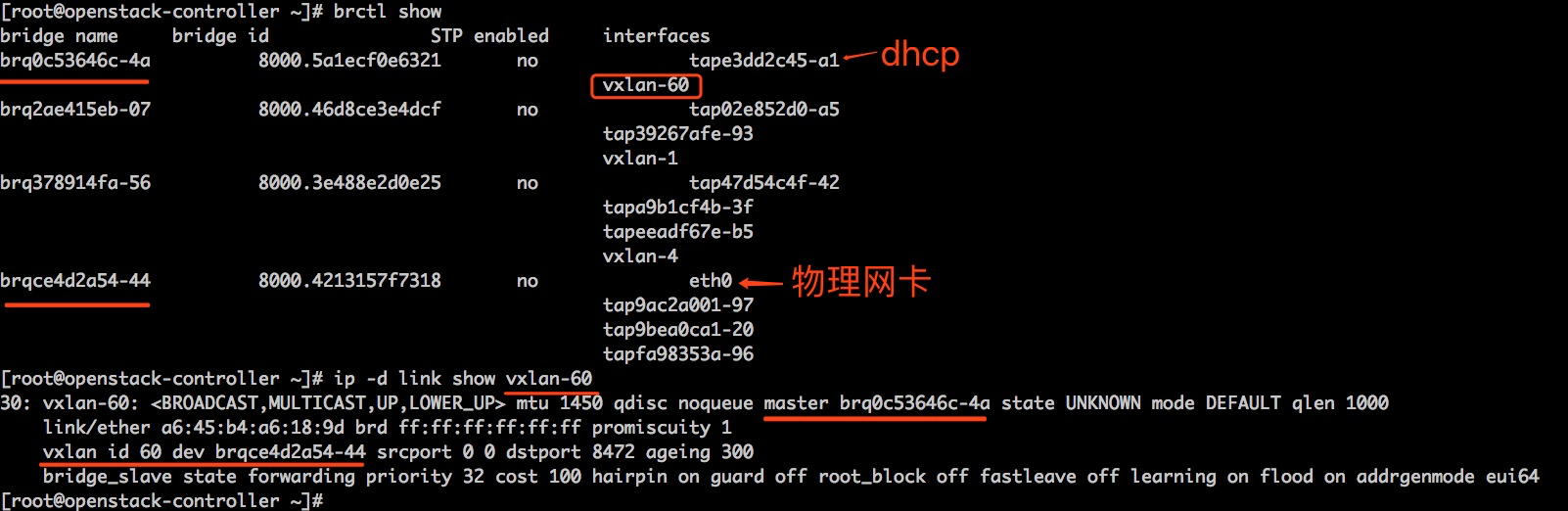
这是openstack控制节点的网络相关信息,问题是: vxlan-60中一个虚机想要通过dhcp获取IP地址,现在dhcp的数据包可以通过eth0到达brqce4d2a54-44,抓包可以验证 :
|
1 |
tcpdump -i brqce4d2a54-44 udp and port 8472 #可以看到数据包 |
但是vxlan-60上却抓不到dhcp数据包:
|
1 |
tcpdump -i vxlan-60 -nn #看不到数据包 |
我觉得,到达了 brqce4d2a54-44 的vxlan数据包,如果vxlan id是60就直接转给vxlan-60 就是了,还可能被哪里的规则给拦截?问题都定位了这地步了,应该问题就出现在openstack-controller身上吧?不应该和其它机器有关系吧?(我不断祭出bridge fdb、brctl、ip等工具,浪费了有半天的时间)
后来,在我都试图想重启openstack-controller的时候,我决定分别在两个compute上创建两个机器,如果两个机器之间能够通信,则说明openstack-controller 的问题,否则,就不是openstack-controller的问题; 测试发现,两个机器不能通信,我才把重点放在了compute节点;
compute节点网络架构:

话说,这个网络和官方指导架构或者书本上指导的架构都不一样; 正常来讲,把bond0 添加到 /etc/neutron/plugins/ml2/linuxbridge_agent.ini 中就可以了,也不会出现今天的问题,因为最初是这样的,我测试vpc功能都是OK的;
加入我把bond0给了neutron,则neutron会将bond0的IP转移给brqce4d2a54-44 , 由于机器有限,我需要在这些compute节点上起ceph node,ceph node也通过虚拟机提供存储服务(如上图的vnet0),如果让vnet0桥接到brqce4d2a54-44 上,总感觉不大好,于是,便有了上述的网络架构;
既然 /etc/neutron/plugins/ml2/linuxbridge_agent.ini 里面配置成了veth_neutron ,那么 /etc/neutron/plugins/ml2/linuxbridge_agent.ini 里面的 local_ip 也应该修改为 veth_neutron 的IP,不是吗?(当然不是,错就错在这儿了),于是我就这么改了
因为vxlan-60 的 dev 是brqce4d2a54-44 ,数据只有先到达brqce4d2a54-44 才可能进入vxlan-60 ;
我发现,进入的vxlan数据包首先是要走到bond0的,然后走到br0,我期望能通过veth_br0 到 veth_neutron , 再到 brqce4d2a54-44 ,然后再到vxlan-60, 然而,实际情况是,vxlan数据包根本不进入veth_br0; 我猜测,很可能内核已经在分析vxlan数据包了,该给谁给谁,没人要就丢掉呗; 然而,vxlan-60是base在brqce4d2a54-44 上的,没有base在br0上; 如果让vxlan-60 base在br0上是不是就可以了呢?
关于vxlan-60 base在哪个设备是通过/etc/neutron/plugins/ml2/linuxbridge_agent.ini 里面的local_ip 来决定的,和 physical_interface_mappings 是不必相同的。
修改后,重启 neutron-linuxbridge-agent.service , 重新创建vpc, 问题解决。
为什么vxlan的目的IP是brqce4d2a54-44, 而实际却不能真正落到brqce4d2a54-44 上?
vxlan 也能在单台机器上演示:
网络拓扑:
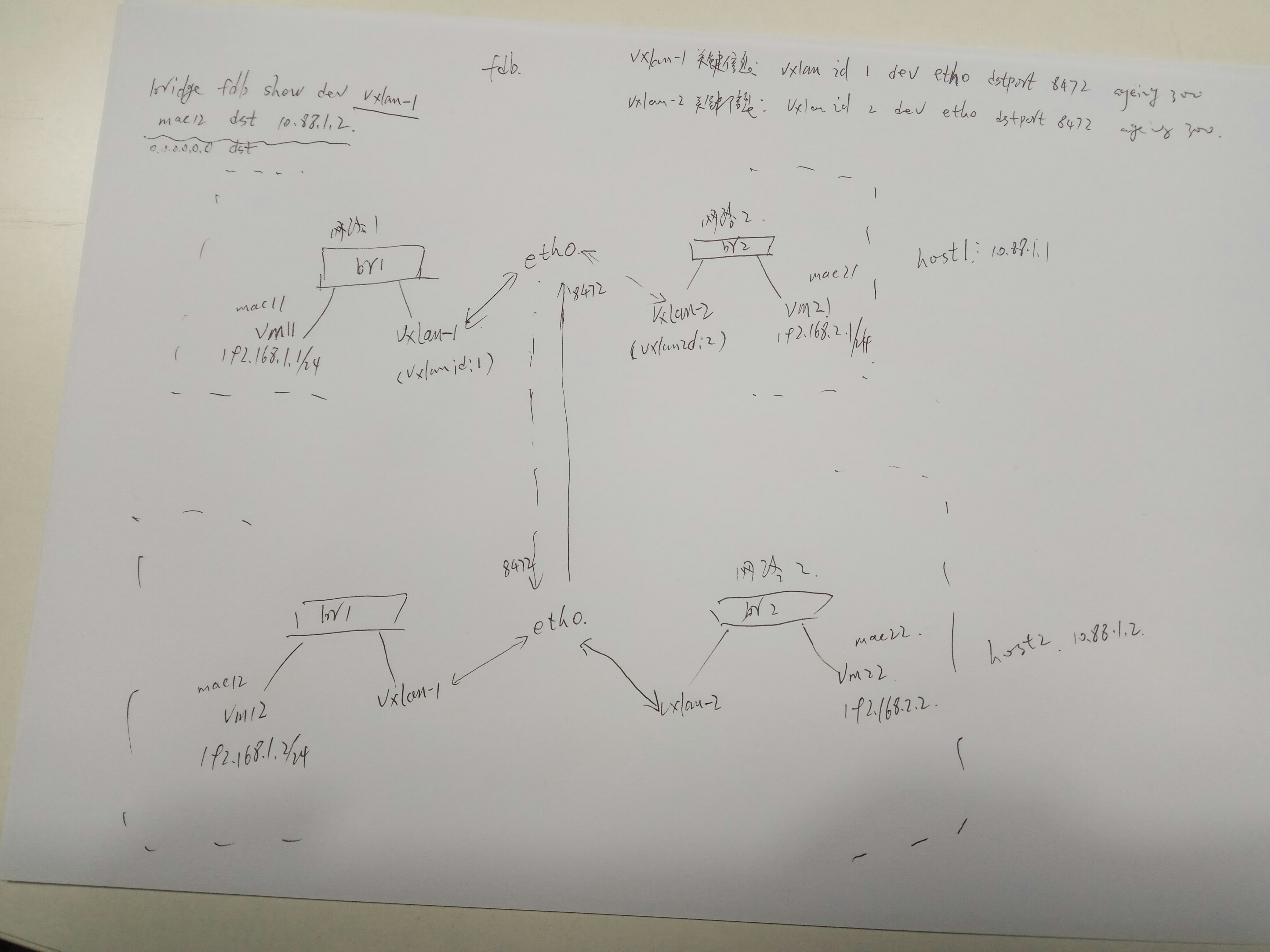
执行命令:
|
1 2 |
ip netns add 192.168.1.1 ip netns add 192.168.1.2 |
|
1 2 3 4 |
ip link add veth10 type veth peer name veth01 # 启动 ip link set dev veth10 up ip link set dev veth01 up |
|
1 2 |
ip link set dev veth01 netns 192.168.1.1 ip link set dev veth10 netns 192.168.1.2 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
ip netns exec 192.168.1.1 bash #配置IP ip a add dev veth01 192.168.1.1/24 #添加网桥 brctl addbr br01 ip link set br01 up #添加一个设备对,一端配置IP,代表一个虚拟机,一端添加到网桥 ip link add veth-vm type veth peer name vm01 ip link set dev veth-vm up ip link set dev vm01 up brctl addif br01 veth-vm ip a add dev vm01 172.16.10.1/24 #添加一个vxlan ip link add vxlan01 type vxlan id 10 dev veth01 ip link set dev vxlan01 up #将vxlan添加到交换机br01上 brctl addif br01 vxlan01 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
ip netns exec 192.168.1.2 bash #配置IP ip a add dev veth10 192.168.1.2/24 #添加网桥 brctl addbr br01 ip link set br01 up #添加一个设备对,一端配置IP,代表一个虚拟机,一端添加到网桥 ip link add veth-vm type veth peer name vm02 ip link set dev veth-vm up ip link set dev vm02 up brctl addif br01 veth-vm ip a add dev vm02 172.16.10.2/24 #添加一个vxlan ip link add vxlan01 type vxlan id 10 dev veth01 ip link set dev vxlan01 up #将vxlan添加到交换机br01上 brctl addif br01 vxlan01 |
|
1 2 3 4 5 6 7 8 9 |
ip netns exec 192.168.1.1 bash bridge fdb add ee:b4:c4:3f:b3:2b dev vxlan01 dst 192.168.1.2 bridge fdb add 00:00:00:00:00:00 dev vxlan01 dst 192.168.1.2 ip netns exec 192.168.1.2 bash bridge fdb add fe:ea:f2:aa:1f:fc dev vxlan01 dst 192.168.1.1 bridge fdb add 00:00:00:00:00:00 dev vxlan01 dst 192.168.1.1 #如果需要广播到多个主机,则需要使用bridge fdb append ,如: #bridge fdb append 00:00:00:00:00:00 dev vxlan01 dst 192.168.1.3 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ip netns exec 192.168.1.1 bash # ping 172.16.10.2 PING 172.16.10.2 (172.16.10.2) 56(84) bytes of data. 64 bytes from 172.16.10.2: icmp_seq=1 ttl=64 time=0.236 ms ... CTRL+D ip netns exec 192.168.1.2 bash # ping 172.16.10.1 PING 172.16.10.2 (172.16.10.1) 56(84) bytes of data. 64 bytes from 172.16.10.1: icmp_seq=1 ttl=64 time=0.236 ms ... |
参考: http://tech.mytrix.me/2017/04/vxlan-overlay-in-linux-bridge/
网络初始化:
/usr/lib/python2.7/site-packages/cloudinit/stages.py:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
def apply_network_config(self, bring_up): netcfg, src = self._find_networking_config() if netcfg is None: LOG.info("network config is disabled by %s", src) return try: LOG.debug("applying net config names for %s" % netcfg) self.distro.apply_network_config_names(netcfg) except Exception as e: LOG.warn("Failed to rename devices: %s", e) if (self.datasource is not NULL_DATA_SOURCE and not self.is_new_instance()): LOG.debug("not a new instance. network config is not applied.") return LOG.info("Applying network configuration from %s bringup=%s: %s", src, bring_up, netcfg) try: return self.distro.apply_network_config(netcfg, bring_up=bring_up) except NotImplementedError: LOG.warn("distro '%s' does not implement apply_network_config. " "networking may not be configured properly." % self.distro) return |
分析:
/usr/lib/python2.7/site-packages/cloudinit/stages.py:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
def _find_networking_config(self): disable_file = os.path.join( self.paths.get_cpath('data'), 'upgraded-network') if os.path.exists(disable_file): return (None, disable_file) cmdline_cfg = ('cmdline', cmdline.read_kernel_cmdline_config()) dscfg = ('ds', None) if self.datasource and hasattr(self.datasource, 'network_config'): dscfg = ('ds', self.datasource.network_config) sys_cfg = ('system_cfg', self.cfg.get('network')) for loc, ncfg in (cmdline_cfg, sys_cfg, dscfg): if net.is_disabled_cfg(ncfg): LOG.debug("network config disabled by %s", loc) return (None, loc) if ncfg: return (ncfg, loc) return (net.generate_fallback_config(), "fallback") |
分析:
先尝试从三个不同的地方获取网络配置(注意,这里是有优先级的):cmdline、system_cfg、datasource中的network_config; 只要其中一个地方明确禁用网络或存在配置则返回;
如果没有找到任何配置,则进入预定义的配置逻辑net/__init__.py: net.generate_fallback_config() :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
def generate_fallback_config(): """Determine which attached net dev is most likely to have a connection and generate network state to run dhcp on that interface""" # get list of interfaces that could have connections invalid_interfaces = set(['lo']) potential_interfaces = set(get_devicelist()) potential_interfaces = potential_interfaces.difference(invalid_interfaces) # sort into interfaces with carrier, interfaces which could have carrier, # and ignore interfaces that are definitely disconnected connected = [] possibly_connected = [] for interface in potential_interfaces: if interface.startswith("veth"): continue if os.path.exists(sys_dev_path(interface, "bridge")): # skip any bridges continue carrier = read_sys_net_int(interface, 'carrier') if carrier: connected.append(interface) continue # check if nic is dormant or down, as this may make a nick appear to # not have a carrier even though it could acquire one when brought # online by dhclient dormant = read_sys_net_int(interface, 'dormant') if dormant: possibly_connected.append(interface) continue operstate = read_sys_net_safe(interface, 'operstate') if operstate in ['dormant', 'down', 'lowerlayerdown', 'unknown']: possibly_connected.append(interface) continue # don't bother with interfaces that might not be connected if there are # some that definitely are if connected: potential_interfaces = connected else: potential_interfaces = possibly_connected # if eth0 exists use it above anything else, otherwise get the interface # that we can read 'first' (using the sorted defintion of first). names = list(sorted(potential_interfaces)) if DEFAULT_PRIMARY_INTERFACE in names: names.remove(DEFAULT_PRIMARY_INTERFACE) names.insert(0, DEFAULT_PRIMARY_INTERFACE) target_name = None target_mac = None for name in names: mac = read_sys_net_safe(name, 'address') if mac: target_name = name target_mac = mac break if target_mac and target_name: nconf = {'config': [], 'version': 1} nconf['config'].append( {'type': 'physical', 'name': target_name, 'mac_address': target_mac, 'subnets': [{'type': 'dhcp'}]}) return nconf else: # can't read any interfaces addresses (or there are none); give up return None |
分析:

|
1 2 3 4 5 6 7 8 |
def read_sys_net_int(iface, field): val = read_sys_net_safe(iface, field) if val is False: return None try: return int(val) except TypeError: return None |
简单说就是: cat /sys/class/net/{$name}/carrier 如果结果是整数,则是插着线呢,否则就没插线,如下:

注意:
插着线的意思是,线的两端都是加了电的网络设备,即: 数据链路层是UP的;
有些网络设备的该文件是不能cat的,如:

|
1 2 3 4 5 6 |
if target_mac and target_name: nconf = {'config': [], 'version': 1} nconf['config'].append( {'type': 'physical', 'name': target_name, 'mac_address': target_mac, 'subnets': [{'type': 'dhcp'}]}) return nconf |
总结:
分析可知,如果不对网络进行特殊配置的话,cloud-init只能帮我们配置一个网卡; 一般来讲,大部分需求已经满足了。
我们如果看 cloud-init ( /var/log/cloud-init.log )的日志的话,会发现,在多个网卡的时候,虽然其他网卡的信息也被read了,但是最终却没有得到和eth0相同的待遇,现在也就真相大白了
堆栈:
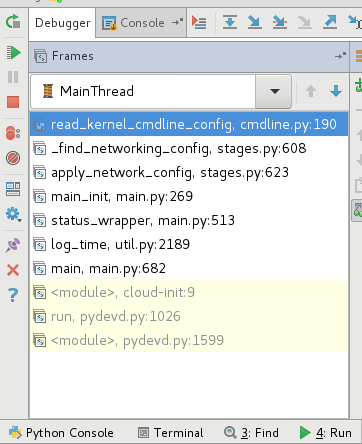
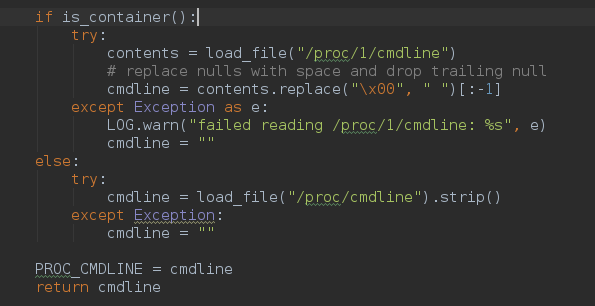
关于cmdline的获取方法: (util.py)
|
1 |
BOOT_IMAGE=/boot/vmlinuz-4.10.10-1.el7.elrepo.x86_64 root=UUID=0356e691-d6fb-4f8b-a905-4230dbe62a32 ro console=tty0 console=ttyS0,115200n8 crashkernel=auto console=ttyS0,115200 LANG=en_US.UTF-8 |
