使用db2look导出的sql文件根据当前环境不同生成的文件编码也不同;
原因1:
如果LANG=zh_CN.UTF-8 ; db2set db2codepage=gbk ; 则会导致文件的第一部分包含utf-8 编码的汉字:
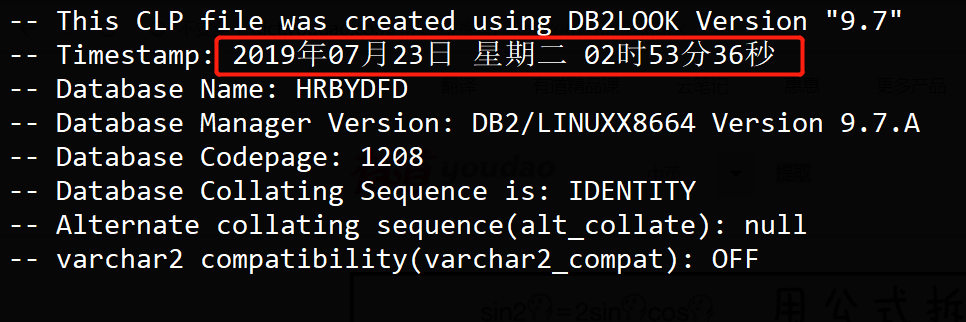
而文件的sql部分中的汉字则是gbk的;
那么,该文件的编码就不能被正确识别; 所以,较好的做法是,使用db2look时,设置 LANG=C, 这样的话Timestamp部分就不会显示中文了; 而sql中的汉字编码跟随db2set 中的db2codepage,建议设置为数据库的字符集和编码,一方面可以避免字符集的转换,另一方面,不通字符集之间不见得就是能转换的,转换失败的话就转成 问好(?) 了。另外,导出的文件在自己的终端打开时,可能和终端的字符集编码不一致导致查看时乱码,这个并不紧要,如果终端的LANG设置正确的话,通常vim会自动将文件的编码转码为终端的编码(vim通过LANG来检测终端的编码)的。
原因2:写入数据库的编码确实就是不同的,下图正常显示的是utf-8 编码的,不正常显示的是写入的gbk编码当做utf-8 解释了; 但是,这种错误不易被发现,因为执行的时候会被认为是合法的utf-8的(确实真的合法)
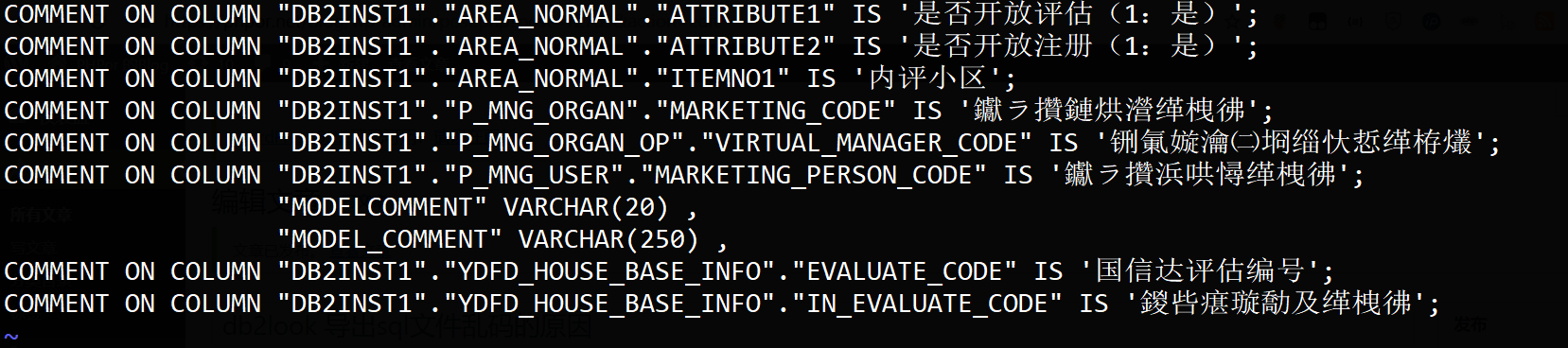
真实的将,该截图是vim查看后截图的,vim根据当前环境将文件原本的GBK自动转码为utf8显示的,乱码部分是原本的GBK文件中的utf8字符又往utf8转了一次所致
如果使用vim查看总是看到满屏的乱码,可能就是识别错编码了,比如:识别成了utf-16; ,因为所有的文件都可以认为是有效的utf-16的。