https://blog.csdn.net/zgy621101/article/details/79298777
https://blog.csdn.net/qiyuanxiong/article/details/77943578
简单的校验办法如下: ff d9 结尾就可以认为图片是完整的

|
1 2 |
#tail -c 2 IMG_2806.jpg|od -tx1 -An|xargs printf '%s%s' ffd9 |
DevOps
https://blog.csdn.net/zgy621101/article/details/79298777
https://blog.csdn.net/qiyuanxiong/article/details/77943578
简单的校验办法如下: ff d9 结尾就可以认为图片是完整的
|
1 2 |
#tail -c 2 IMG_2806.jpg|od -tx1 -An|xargs printf '%s%s' ffd9 |
问题:
|
1 2 |
# curl https://github.com curl: (35) SSL connect error |
分析:
tcpdump 抓包、wireshark分析:
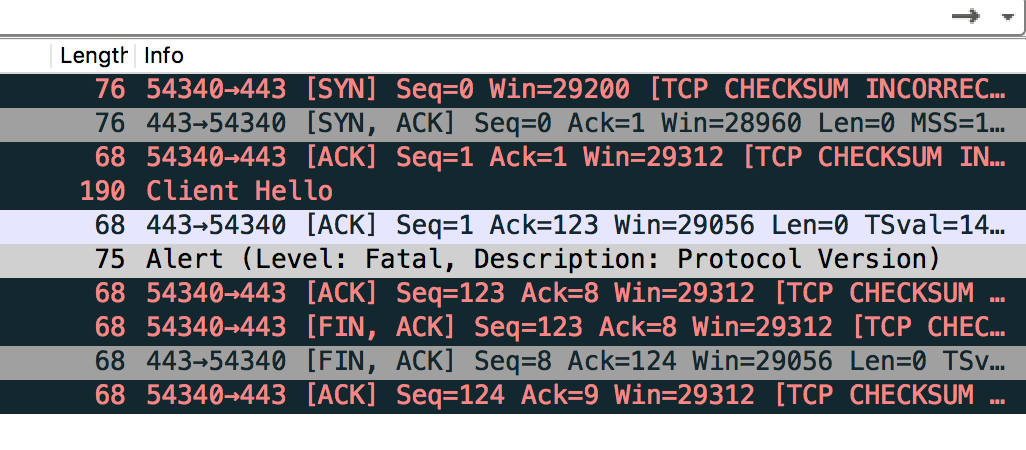
基本是由于ssl版本导致的:
client想使用TLS 1.0 , server说,不行,太低
解决办法:
|
1 |
curl --tlsv1.2 https://github.com |
每次都带上个选项多不方便,使用 .curlrc ; linux上的程序一般都这个套路,在用户目录下写个配置文件:
|
1 2 |
# cat ~/.curlrc --tlsv1.2 |
配置文件格式就是直接写curl的命令行选项,简单粗暴高效。
有些curl -v 就能看到握手的ssl版本号
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ curl -v https://github.com * Rebuilt URL to: https://github.com/ * Trying 172.16.20.14... * Connected to github.com (172.16.20.14) port 443 (#0) * TLS 1.2 connection using TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 * Server certificate: github.com * Server certificate: DigiCert SHA2 Extended Validation Server CA * Server certificate: DigiCert High Assurance EV Root CA > GET / HTTP/1.1 > Host: github.com > User-Agent: curl/7.49.1 > Accept: */* |
删除前:
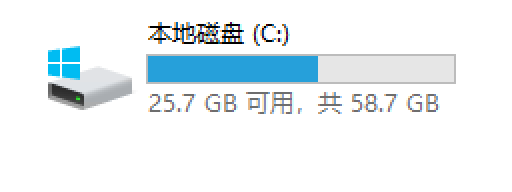

其中windows.old 有 5G+
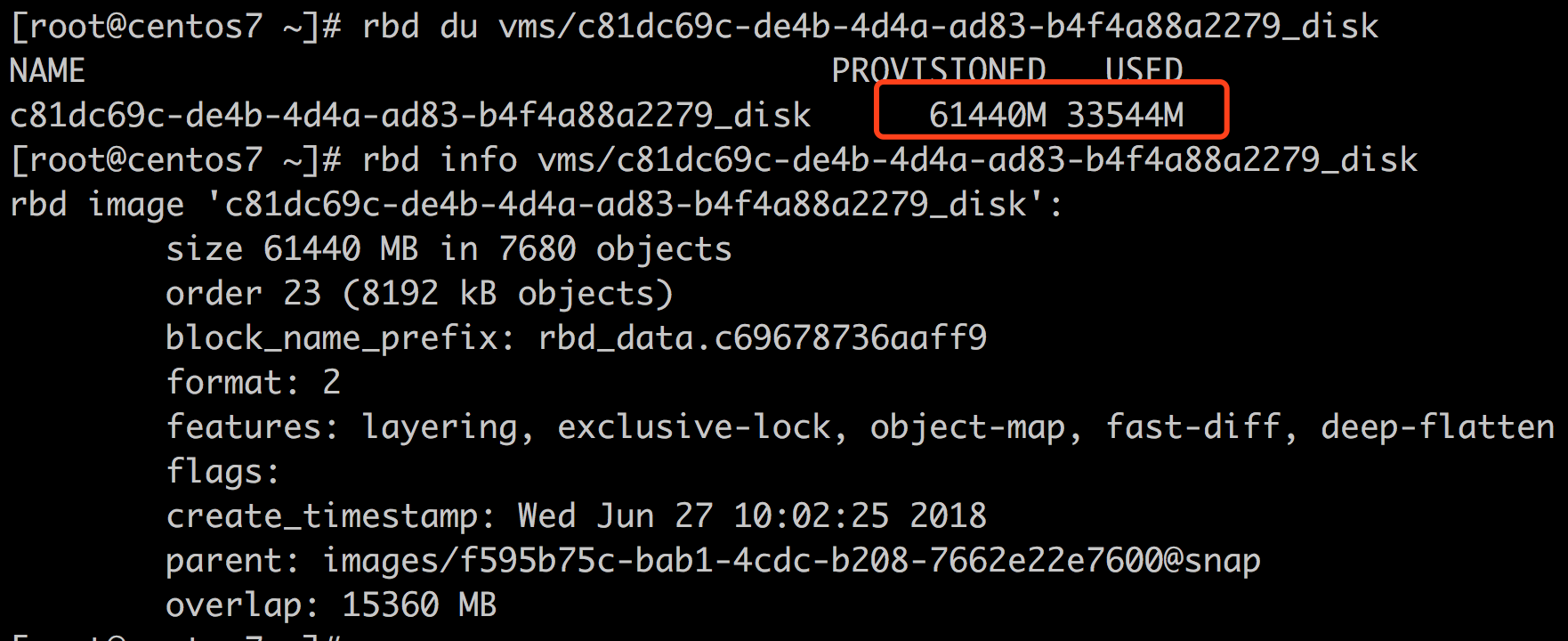
rbd 信息:
使用磁盘清理看看能清理多少:
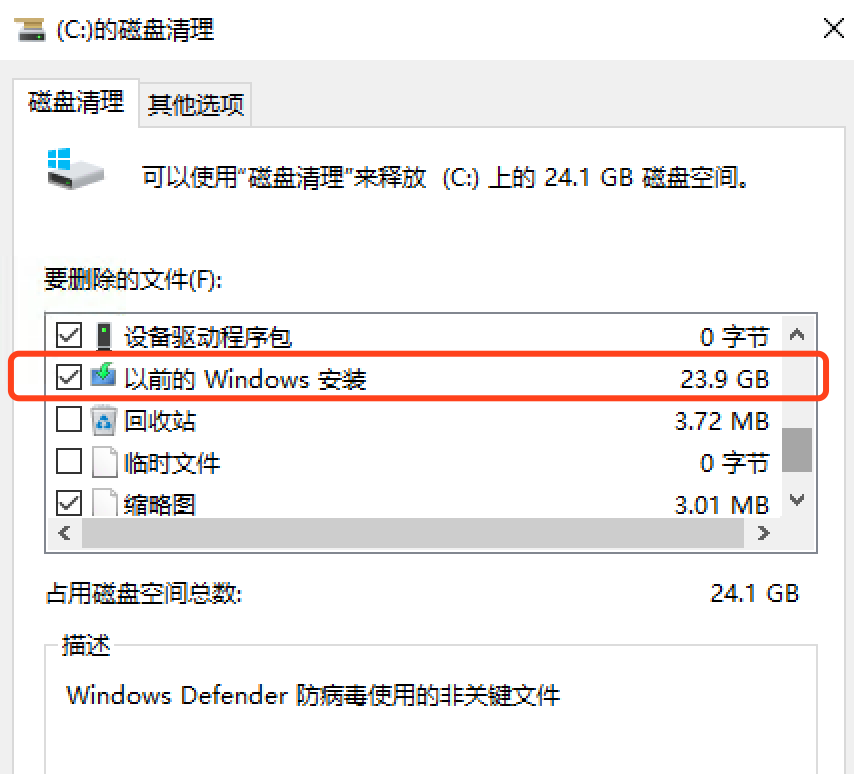
可以清理掉24GB,实在惊讶,预计清理后,大小在10GB左右,还算可以接受吧
删除后:


没有想预期那样释放掉24GB,而是释放了大约20GB空间,不过确实windows.old 不见了;
rbd info:
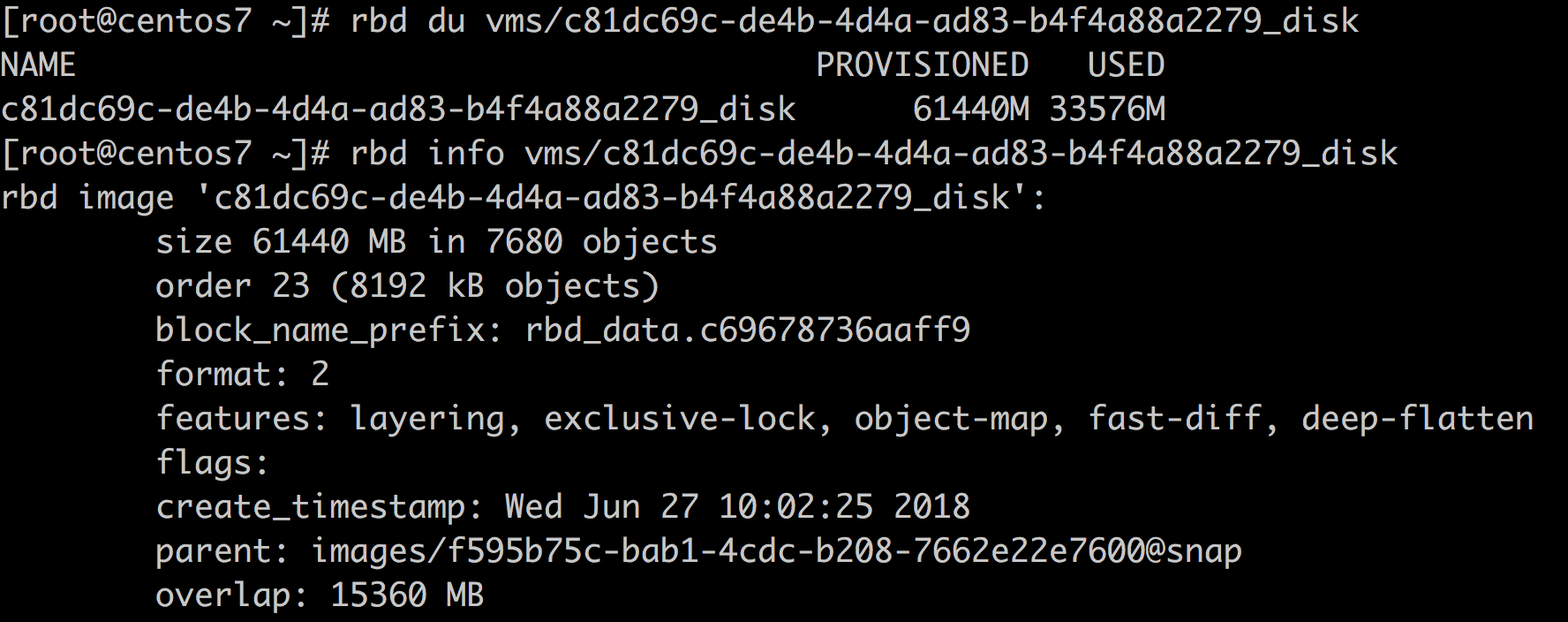
从rbd上来看基本没有任何变化,因为没有fstrim,那么,如何对ntfs进行fstrim呢?或许有必要先进行一遍碎片整理(其实碎片整理的效果一点儿也不明显)
那么依据这个rbd做一个镜像的话,会占用多大的空间呢?会是60GB呢?还是和现在一样呢?还是和文件系统大小一样呢?

fstrim: https://blog.csdn.net/liumangxiong/article/details/50502367
搭建openstack时,配置好rbd后,我们并没有在virsh pool-list 时看到一个存储池,但是如果我们要配置一个存储池也是可以的:
编写配置文件: rbd-volumes.xml
|
1 2 3 4 5 6 7 8 9 10 |
<pool type='rbd'> <name>rbd-volumes</name> <source> <host name='10.88.12.4' port='6789'/> <name>volumes</name> <auth username='cinder' type='ceph'> <secret uuid='9dd5c6f0-ffc2-476b-b89c-071998ad8462'/> </auth> </source> </pool> |
其中rbd-volumes是我们给这个存储池起的一个名字,随便你;
10.88.12.4 是ceph monitor节点地址
volumes 是rbd所在的ceph中的pool
auth里面有用户名cinder和预先定义好的秘钥(秘钥通过secret-define来定义)
然后执行:
|
1 |
virsh pool-define rbd-volumes.xml |
然后就会自动生成文件 /etc/libvirt/storage/rbd-volumes.xml:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
<pool type='rbd'> <name>rbd-volumes</name> <uuid>09ec5b59-509d-40b9-9c8a-e03e8de60b1d</uuid> <capacity unit='bytes'>0</capacity> <allocation unit='bytes'>0</allocation> <available unit='bytes'>0</available> <source> <host name='10.88.12.4' port='6789'/> <name>volumes</name> <auth type='ceph' username='cinder'> <secret uuid='9dd5c6f0-ffc2-476b-b89c-071998ad8462'/> </auth> </source> </pool> |
然后通过virsh pool-list 可以查看到定义好的存储池:
|
1 |
virsh pool-list |
然后启动池子:
|
1 |
virsh pool-start rbd-volumes |
就可以列出来存储池中的rbd了;(我这里的volumes就是上面提到的rbd-volumes)
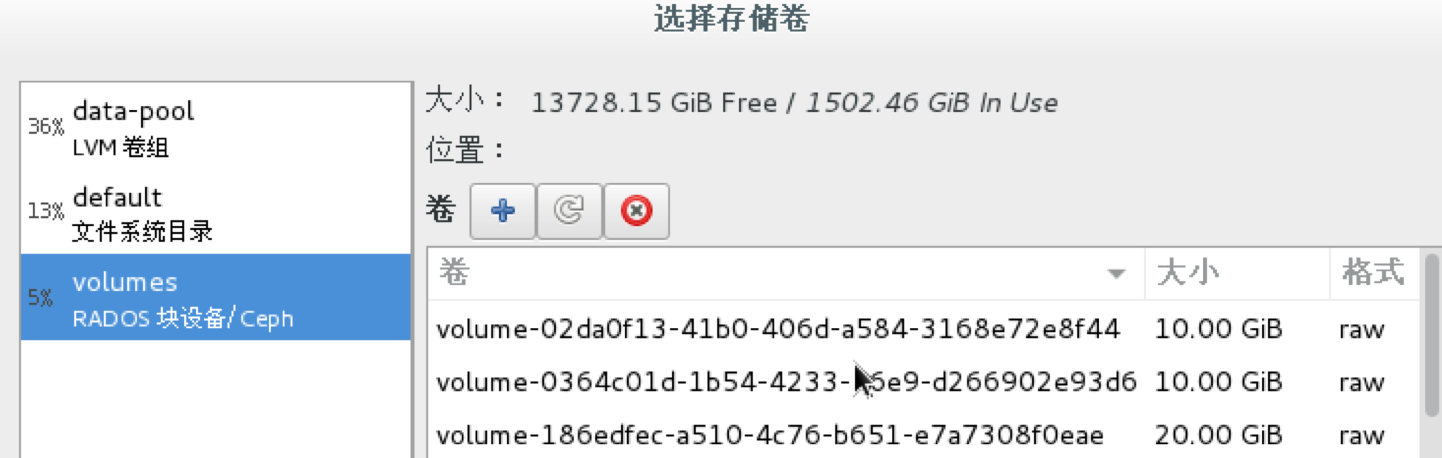
然后就可以使用这里的rbd来启动虚拟机了呗?不过又遇到问题,通过virt-manage来使用这里的rbd创建机器时报错:
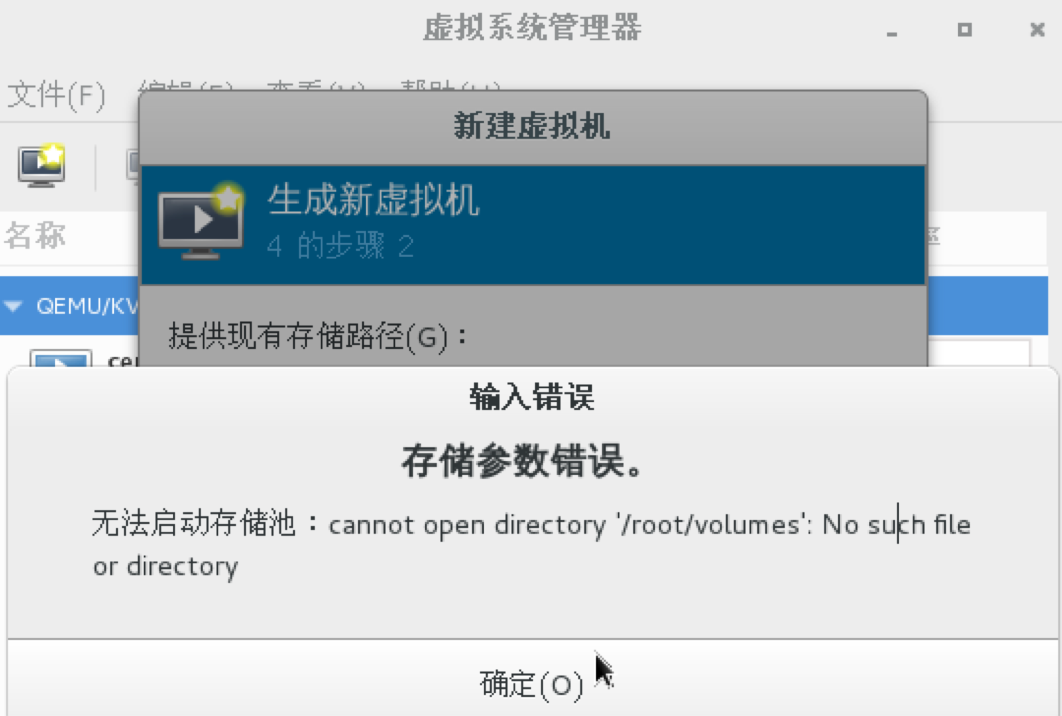
话说这个和/root/volumes 有毛关系?
google 之,别人也有遇到: https://bugzilla.redhat.com/show_bug.cgi?id=1074169#c14
问题似乎出现在virt-manager 上,问题版本: 1.4.1 ; 换个新的试试:
https://github.com/virt-manager/virt-manager
更新到 1.5.0 依然存在这个问题,稍后再研究; 最新的版本构建起来麻烦一些,依赖python3的东西,我的安装源中有些找不到
相关fix: https://github.com/tonich-sh/virt-manager/commit/ce939a04099431ea273fa53850ab8a6db363a112
下面的dockerd占用了5G的内存+2.6G的swap,管理几个容器需要这么多的资源吗?一定是哪里有bug?

图中的java和mysql也都是不怎么使用的,所以占用很多的swap; 真正用的时候就会很慢。
|
1 2 |
# uname -a Linux VM-2-10-12 3.10.0-514.6.1.el7.x86_64 #1 SMP Wed Jan 18 13:06:36 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux |
|
1 2 |
# docker -v Docker version 1.12.5, build 047e51b/1.12.5 |
centos6.8
启动进程: /sbin/init (因为启动这个可以直接利用 init-scripts 配置自动启动的进程,比如: mysqld等)
docker stop $name
现象: 卡死了,进不去了
/sbin/init进程不退出,由init进程启动的子进程也处于defunct状态; 很可能是上级的某进程存在bug; 逐级上朔,找到shim进程,该进程kill 默认信号是不死的,看来可能有问题,直接kill -9 ; 然后,容器就干净地退出了
缘起:
为什么我执行ceph health时都是HEALTH_OK,但是搭建了Prometheus+grafana: (参考:https://www.2cto.com/net/201801/712794.html ),看到的状态却是HEALTH_WARN,why?
分析:
我们使用的ceph_exporter: github.com/digitalocean/ceph_exporter ; 参考源码发现,这里使用json格式获取的health,而且参考的是overall_status ; 自己在命令行看看:
|
1 2 |
# ceph health -f json {"checks":{},"status":"HEALTH_OK","overall_status":"HEALTH_WARN"} |
果不其然,overall_status 为 HEALTH_WARN
办法一:
参考status,不参考overall_status;
缺点:
办法二:
查明为什么overall_status 为HEALTH_WARN , 应该确实存在问题
我的ceph版本: ceph version 12.2.1 (3e7492b9ada8bdc9a5cd0feafd42fbca27f9c38e) luminous (stable)
在 luminous 之前,ceph 输出的都是 overall_status , luminous开始,就开始使用status了,但是,为了兼容以前的版本,还是输出了overall_status了,不过,为了让使用者意识到 overall_status 不建议使用了,所以,就强制将 overall_status 设置为了 HEALTH_WARN; 有时候,这个逻辑显得不太友好,于是,从12.2.2 开始添加了一个选项:
|
1 |
mon_health_preluminous_compat_warning |
可以通过设置该选项,来禁止这个警告。
但是,我使用的是12.2.1 ,咋办? 要么修改exporter,要么干脆升级ceph
比较稳妥的做法是,在一个测试的机器上,启动一个12.2.5版本的ceph-mon,设置:
|
1 |
mon_health_preluminous_compat_warning=false |
然后,ceph.conf中指定连接该ceph-mon,测试效果如下:
|
1 2 |
# ceph health -f json {"checks":{},"status":"HEALTH_OK"} |
没有了overall_status; 如此的话,ceph_exporter 就是要overall_status的话,还真就得修改ceph_exporter了, fork 后修改之:
https://github.com/phpor/ceph_exporter
参考:
https://github.com/ceph/ceph/pull/17930
http://lists.ceph.com/pipermail/ceph-users-ceph.com/2017-September/021031.html
排序一般使用sort命令,但是,sort命令是基于行的:
|
1 |
echo a c b d|sort |
这个是不会输出 : a b c d 的
可以这样:
|
1 |
echo a c b d | xargs -n 1 |sort |
也或者:
|
1 |
echo a c b d |while read w; do echo $w done | sort |
总之,把空白换成换行
https://google.github.io/styleguide/shell.xml
建议的bash风格,不可不学