https://www.cnblogs.com/wuhuiyuan/p/linux-filesystem-inodes.html
ext*文件系统的inode数量是预先定义好的,但是xfs的不是,xfs文件系统比较能很好地平衡inode和磁盘空间的使用
DevOps
https://www.cnblogs.com/wuhuiyuan/p/linux-filesystem-inodes.html
ext*文件系统的inode数量是预先定义好的,但是xfs的不是,xfs文件系统比较能很好地平衡inode和磁盘空间的使用
带宽计算公式为:带宽=时钟频率*总线位数/8
对于网线来讲,总线位数等于1,而且公式里的带宽单位显然是byte/s
时延 包括好多方面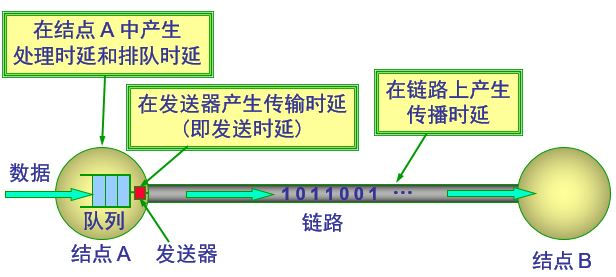
仅从链路上的传输时延来讲,仅仅和信号在介质上的传播速度有关系,和带宽没有关心
为什么给人的感觉是带宽越大,延迟越小呢?我觉得,更大的带宽可以在大数据量时降低排队时延,进而降低总体时延;如果设备没有任何负载,从结点A发送到结点B一个数据包的时延应该和A、B之间的带宽没有一毛钱关系。
又是什么影响带宽的呢?
我觉得带宽是由频率决定的,单位时间内,产生的波峰和波谷越多,就意味着信息量越大,也就是带宽越大
带宽和延迟之间的关系:
当数据量很小时,延迟基本会稳定在某个值左右。随着数据量的变大,延迟也会变大;就好比从北京开车去广州,高速上车越多,花费的时间也就越多,尽管还没达到最大吞吐量,延迟已经很厉害了。 当然,如果你走土路,可能和车多少关系也不大,这个就是介质问题。
所以,高带宽和低延迟需求要分开考虑,尽量使用不同的网络。
参考: http://m.blog.csdn.net/u013830021/article/details/73648091
缘起:
20T的1亿个小文件存放在xfs的文件系统中会存在inode被用光(但是存储空间还有很大空闲)的问题吗?
测试:
df -i 可以看到可用、已用inode数量,一般来讲,mkfs的时候,会划分 x% 的空间存放inode的,可用inode数量是按照文件个数计算的,不是按照占用空间计算的,如:

500GB的磁盘,格式化为xfs后,可以使用的inode数量约 2.6亿; 那么1GB的磁盘格式化为xfs后,可用inode数量为 2.6亿/500 ~= 50万吗?测试如下:
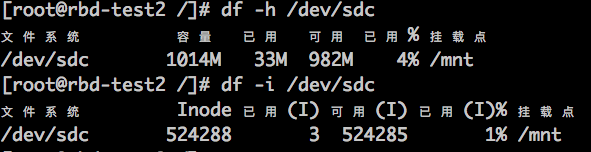
确实,1GB默认可以存放约52万个文件,注意: 目录也是占用inode的,而且也不可能把所有文件都放在一个目录的,所以真正计算inode的话,还需要把目录的数量算上; 按照每个目录100个文件计算的话,50万个文件就需要5k个目录(可以忽略不计了);其实不全对,5k个目录放在一个父目录下也不科学,为了保证每个目录最多100个的话,还要分到50个父目录里面,额.. 也没有多少目录
按照上面的公式计算: 20T/1G*50w ~= 1000亿 个文件, 不少了
当然,如果还不够的话,格式化的时候可以指定更大的inode数量
计算:
10亿个文件,打散到N个目录中,每个目录的子目录(文件)数量不超过100个,需要多少级子目录?
100x > 10亿 ,x最少值为 x>=5 ,就是说 5层目录就够了
其实,xfs是个比较只能的文件系统,没有固定大小的inode区域,随着磁盘的使用,inode的总数量也在变化,基本不会出现inode已用光,但是存储空间很空闲很多的情况
http://m.docin.com/touch_new/preview_new.do?id=1551793152
ipsan 需要把传输的数据封到IP数据包中, fcsan 不需要封包,直接将scsi扔给光模块即可;话说封包是消耗client的CPU的(但是你真的在乎这点儿CPU吗?你真的很在意这点儿计算增加的延迟吗?访问磁盘的延迟远比这个大的多)
ipsan和fcsan只有在大访问量时才能明显感觉到差异
IP网络和fc网络的传输延迟不一样,能有多大差异?
http://m.blog.csdn.net/xysoul/article/details/42975159
ipsan 不见得比fcsan 差多少吧?
ipsan 是: 物理层 -〉以太网数据链路层 -〉 ip -〉 scsi
fcsan是: 物理层(光纤) -〉fc协议 -〉 scsi
由于我的rbd image中都是一个相同的基础镜像,里面的文件系统都一样,相同的xfs文件系统格式,相同的文件系统id;所以,就算可以rbd map多个,也不能同时mount多个,因为文件系统id一样啊。
问题是,我已经umount了rbd image1,再去mount rbd image2,为啥还是提示:
|
1 |
XFS (nbd1p1): Filesystem has duplicate UUID 0356e691-d6fb-4f8b-a905-4230dbe62a32 - can't mount |
原因: 虽然umount了,但是相关的xfs后台进程并没有退出,所以,可以进一步unmap掉那个不需要的设备,xfs进程就会退出:

对于使用linux-bridge来实现网络虚拟化的情况:
如果需要使用vlan来作为provider,则,配置基本如下:
/etc/neutron/plugins/ml2/linuxbridge_agent.ini
|
1 2 |
[linux_bridge] physical_interface_mappings = provider:eth0 |
/etc/neutron/plugin.ini
|
1 2 |
[ml2_type_vlan] network_vlan_ranges =provider:3000:3001 |
注意: network_vlan_ranges 是需要配置的, 这样在重启neutron服务的时候,会在neutron数据库中创建:
|
1 2 3 4 5 6 7 |
# mysql -uroot -pxxxx neutron -e 'select * from ml2_vlan_allocations;' +------------------+---------+-----------+ | physical_network | vlan_id | allocated | +------------------+---------+-----------+ | provider | 3000 | 0 | | provider | 3001 | 0 | +------------------+---------+-----------+ |
network_vlan_ranges 配置从注释来看,似乎可以不写vlan范围,其实不行,因为需要在表中创建条目,如果指定range大小会1000,则会一次产生1000个数据库记录;
另外,当我们从配置文件中把 provider 删除(或重命名)时,数据库中的条目并不被删除,而且会导致neutron服务启动失败,这时候,可以手动删除上述条目
当我们在provider上创建一个vlan id为3000的vlan provider时,会自动创建eth0.3000, 假如compute节点上部署openstack-controller(确切说,应该是neutron)虚拟机,由于该虚拟机也需要类似eth0.3000的接口,然而,宿主机只有一个网卡的情况下,如果虚拟机桥接的也是eth0的话,宿主机上创建了eth0.3000后,虚拟机将不再能收到vlan3000的流量了(被截流了),所以就比较麻烦,所以,建议neutron虚拟机不要部署在计算节点上;也或者还有其它的不愉快。
当然,如果确实没有其它的机器安装neutron虚拟机呢?其实办法还是有的:

openstack 中配置给provider的物理网卡使用veth1 就行, 这样的话,vm-neutron也能看到vlan3000的数据包了
问: openstack 中配置给provider的物理网卡使用veth0 行不?
根据veth对儿实现原理,veth0接收到的数据如果不是从veth1来的,肯定发送给veth1,否则发送给br0;假如,配置为veth0,则vm的数据发送给veth0.3000后,经过veth0会被发送给veth1,而不是br0,这不是我们想要的
参考: https://www.cnblogs.com/xieshengsen/p/6215168.html
在kernel启动参数中添加: console=ttyS0
这岂不是要重启?
也不用,centos7下,只需要启动一个服务就行:
|
1 |
systemctl start getty@ttyS0 |
为了下次能自动启动,可以enable一下:
|
1 |
systemctl enable getty@ttyS0 |
注意: 最好确保 ttyS0已经加入了 /etc/securetty :
|
1 |
echo ttyS0 >> /etc/securetty |
然后就可以virsh console $domain 了
其实对应domain的console在宿主机是有一个tty的,如下方式查看:
|
1 |
virsh ttyconsole $domain |
如:
|
1 2 |
# virsh ttyconsole ceph-8 /dev/pts/2 |
比较有趣的玩法是:
为什么virsh console没有配置的时候,virt-manager依然能看到虚拟机的界面呢?virt-manager走的是vnc(或spice)方式,而且是宿主机里面提供的,和虚拟机里面是否有vnc(spice)没有关系。
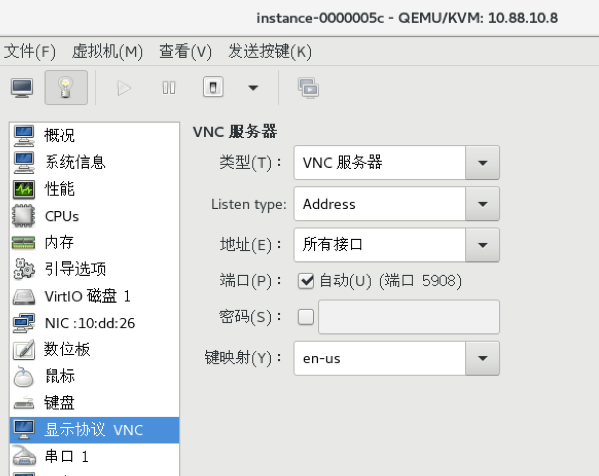
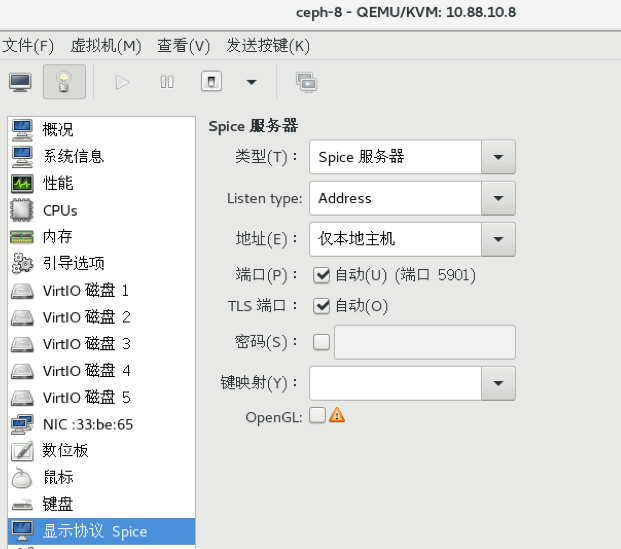
通过ps也能查看:
|
1 |
ps aux|grep -E "\-(vnc|spice) [^ ]*" |
默认情况下,虚拟机的vnc(或spice)会listen 127.0.0.1 上的端口,远程通过virt-manager访问的时候,如果使用ssh协议的话,会通过如下方式将vnc(或spice)端口重定向到本地:
|
1 |
ssh libvirtd-host sh -c 'nc -q 2>&1 | grep "requires an argument" >/dev/null;if [ $? -eq 0 ] ; then CMD="nc -q 0 127.0.0.1 5901";else CMD="nc 127.0.0.1 5901";fi;eval "$CMD";' |
然后在这个打开的流上进行vnc(或spice)协议,这个可就不想tty那么好模拟了
那么,kvm如何就能启动一个vnc,使得能够访问虚拟机呢?模拟硬件的tty?
表象:
kvm虚拟机vm的nic使用virio驱动,在vm流量大的时候,vm就直接断网了; 我们原本有多台vm的,但是其中几台已经多次出现断网的情况,重启vm就好使了;我以为这个vm有问题,后来其他的vm也出现类似问题,我才察觉,其实是这台vm的流量通常更高,出现问题的概率大而已。
虚拟机信息:
|
1 2 |
# uname -a Linux ceph-5 4.4.61-1.el7.elrepo.x86_64 #1 SMP Wed Apr 12 11:53:28 EDT 2017 x86_64 x86_64 x86_64 GNU/Linux |
宿主机信息:
|
1 2 |
# uname -a Linux compute-5 4.10.10-1.el7.elrepo.x86_64 #1 SMP Wed Apr 12 13:38:46 EDT 2017 x86_64 x86_64 x86_64 GNU/Linux |
我的问题和 https://bugs.launchpad.net/ubuntu/+source/qemu-kvm/+bug/997978 基本是一样的
重新attach网络接口:
|
1 2 3 4 |
# virsh domiflist instance-000000c4 接口 类型 源 型号 MAC ------------------------------------------------------- tapf4bddb27-1d bridge brqce4d2a54-44 virtio fa:16:3e:5e:93:29 |
|
1 |
# virsh detach-interface --mac fa:16:3e:5e:93:29 instance-000000c4 bridge |
|
1 |
# attach-interface --mac fa:16:3e:5e:93:29 --domain instance-000000c4 --type bridge --model virtio --live --source brqce4d2a54-44 --target tapf4bddb27-1d |
|
1 |
# ifup eth0 |
参考:
https://bugs.launchpad.net/ubuntu/+source/qemu-kvm/+bug/1050934
https://bugs.launchpad.net/ubuntu/+source/qemu-kvm/+bug/997978
场景,用docker做开发用的虚拟机,每个docker都有一个可以公开访问的IP地址。
由于docker和宿主机共享内核,一不小心可能会把整个宿主机搞挂,而且,docker热迁移也是个难题,所以,尽管openstack马上可以支持docker,我也不想让docker直接部署在计算节点;我的思路是,将docker部署在openstack管理的kvm虚拟机上,这样还能通过热迁移kvm的方式将容器迁移到别的计算节点。
注意事项: