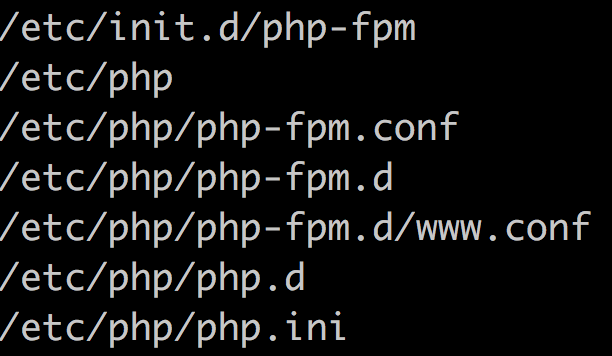
基础知识
- 打包根目录,默认user home目录下的rpmbuild,如下:
|
|
# rpm --showrc|grep rpmbuild -14: _topdir %{getenv:HOME}/rpmbuild |
- 打包共需要几个子目录,如下:
|
|
# ls ~/rpmbuild/ BUILD BUILDROOT RPMS SPECS SRPMS SOURCES |
其中:
SPECS:spec文件目录,其实你完全可以spec文件放在任意你喜欢放置的地方
SOURCES: 源码目录,spec中Source指定的文件如果是相对路径就来这里找,当然,Source可以是一个url地址; 该目录位置由 _sourcedir 定义,如:
|
|
# rpm --showrc|grep _sourcedir RPM_SOURCE_DIR="%{u2p:%{_sourcedir}}" -14: _sourcedir %{_topdir}/SOURCES |
该目录可以没有,如,通过命令行选项的–define来定义一个指定的路径,如下:(将源码目录定位到当前目录)
|
|
rpmbuild --define "_sourcedir `pwd`" ... |
BUILD:%setup指令默认会将源码解压缩到该目录,并在该目录下进行编译
BUILDROOT:%make_install 宏会将需要安装的文件安装到该目录下,用于生成rpm包
RPMS:编译好的二进制rpm文件以及debuginfo rpm文件会放到该目录下,如:
|
|
/home/phpor/rpmbuild/RPMS/x86_64/openresty-1.9.15.1-1.x86_64.rpm /home/phpor/rpmbuild/RPMS/x86_64/openresty-debuginfo-1.9.15.1-1.x86_64.rpm |
SRPMS:一般来讲,二进制RPM是指定平台下的,在不同的平台下需要重新编译,而SRPMS目录是用于放置带有源码的rpm文件,该rpm文件在安装时会进行及时编译的,如:在对openresty进行rpm打包时有如下srpm文件生成:
|
|
# rpm -qlp /home/phpor/rpmbuild/SRPMS/openresty-1.9.15.1-1.src.rpm ngx_txid.tar.gz openresty-1.9.15.1.tar.gz openresty.spec |
源码的rpm包包含需要的源码和一个spec文件(二进制的rpm包不包含spec文件)
- 基于源码编译的rpm包一般(rpmbuild -ba )会产生三个文件,openresty打包产物如下:
|
|
Wrote: /home/phpor/rpmbuild/SRPMS/openresty-1.9.15.1-1.src.rpm Wrote: /home/phpor/rpmbuild/RPMS/x86_64/openresty-1.9.15.1-1.x86_64.rpm Wrote: /home/phpor/rpmbuild/RPMS/x86_64/openresty-debuginfo-1.9.15.1-1.x86_64.rpm |
- 其实你完全可以在spec文件中没有编译操作而只是把预先准备好的二进制文件install到BUILDROOT下,然后生成二进制的rpm文件,但是似乎没有同时产生三个rpm文件显得专业
SPEC文件说明
spec文件中有一大堆的宏和类似宏的东西,搞懂这些对rpm打包极为重要。
%setup
该宏的作用是,将源码安装到BUILD目录下,无参情况下的%setup等价于:
|
|
cd %{_topdir}/BUILD rm -fr %{name}-%{version} gzip -dc %{_sourcedir}/%{source} | tar -xvvf - if [ $? -ne 0 ]; then exit $? fi cd %{name}-%{version} cd /usr/src/redhat/BUILD/%{name}-%{version} chown -R root.root . chmod -R a+rX,g-w,o-w . |
-n选项:
如果source解压后的目录名不是spec中定义的 %{name}-%{version}, 那么目录切换就会出错,这时候可以使用-n参数,如: %setup -n phpor ,则上面逻辑中的 %{name}-%{version}将会是-n指定的参数phpor
-c选项:
如果源码目录不是在一个指定的目录下,如: 对于软件phpor-1.0,目录结构如下:
如果: tar -zcf phpor-1.0.tar.gz phpor-1.0 则比较正常
如果: cd phpor-1.0 && tar -zcf phpor-1.0 * 则解压出来将没有phpor-1.0这个目录,而是x1 x2 x3 三个目录(或文件),这时候就需要在打rpm包的时候预先创建phpor-1.0这个目录,然后解压到该目录,这就是使用-c的作用了
更多参考: http://www.rpm.org/max-rpm/s1-rpm-inside-macros.html#S3-RPM-INSIDE-SETUP-MULTI-SOURCE
%prep
其实该宏很简单:
|
|
# rpm --eval "%prep" %prep LANG=C export LANG unset DISPLAY |
%install
|
|
# rpm --eval "%install" %install LANG=C export LANG unset DISPLAY |
%makeinstall
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# rpm --eval "%makeinstall" /usr/bin/make \ prefix=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/usr \ exec_prefix=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/usr \ bindir=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/usr/bin \ sbindir=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/usr/sbin \ sysconfdir=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/etc \ datadir=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/usr/share \ includedir=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/usr/include \ libdir=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/usr/lib64 \ libexecdir=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/usr/libexec \ localstatedir=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/var \ sharedstatedir=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/var/lib \ mandir=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/usr/share/man \ infodir=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64/usr/share/info \ install |
%make_install
|
|
# rpm --eval "%make_install" make install DESTDIR=/home/phpor/rpmbuild/BUILDROOT/%{name}-%{version}-%{release}.x86_64 |
%files
最好写的细一些,不要直接写 / (根目录)
- 配置文件使用%config指定
- 如果需要往 /etc/init.d 下安装启动脚本,则更不能直接写 / ,因为这意味着还要安装目录 /etc/init.d ,而该目录已被chkconfig包所使用,会出现冲突,所以可以添加对chkconfig包的依赖(当然不明确声明也没关系,只要/etc/init.d 目录存在即可),然后只安装需要安装的/etc/init.d/下面的脚本
%config
配置文件可以通过该指令指定,配置文件比较特殊,有时候期望卸载软件的时候配置还能保留;rpm是这么处理配置文件的:
- 如果配置文件没有修改过,卸载软件时删除
- 如果配置文件修改过,卸载软件时备份到其他文件,如:
|
|
# rpm -e beebank-test warning: /etc/hello.conf saved as /etc/hello.conf.rpmsave |
rpmbuild 选项说明
-bp:只解压缩文件,不编译
-bc:编译但不安装
-bi: 编译、安装(到$RPM_BUILD_ROOT目录下),不删除 $RPM_BUILD_ROOT目录,不生成rpm文件,方便查看安装的位置是否正确
-ba:即生成源码rpm包,也生成二进制rpm包
其实源rpm包比较好创建,就是把指定的source和spec两个文件打成一个rpm压缩包;如果是自己已经编译过的目录(不让rpm来编译,就不会有debuginfo rpm包)
-bb: 只生成二进制rpm包
-bs:只生成源码rpm包
-t*:直接build指定的tar包,该tar包中包含了spec文件
rpmbuild debug
rpmbuild总是根据spec文件生成一个shell脚本,该脚本是%_tmppath 下的一个临时文件,具体查看 %_tmppath 的方式:
|
|
#rpm --eval "%_tmppath" /var/tmp |
通过查看生成的shell脚本就能比较清楚地知道rpm是如何工作的,宏扩展后具体是什么
另: spec文件中是可以直接写shell脚本的,如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
%define prefix /usr/local/openresty %define ln_nginx /usr/sbin/nginx Name: beebank-openresty Version: 1.9.15.1 Release: 1 Summary: OpenResty, scalable web platform by extending NGINX with Lua Group: Development/Languages License: BSD URL: https://openresty.org/ Source0: beebank-openresty-1.9.15.1.tar.gz Source1: ngx_txid.tar.gz Packager: phpor <junjie.li@beebank.com> %description Openresty build for beebank %prep %setup %setup -D -b 1 %build ./configure --prefix=%{prefix} \ --with-pcre-jit \ --with-ipv6 \ --without-http_redis2_module \ --with-http_iconv_module \ --add-module=../ngx_txid \ -j2 make %install %make_install %post for f in %{prefix}/bin/*; do ln -s $f /usr/bin/$(basename $f);done [ -e /etc/nginx ] || ln -s %{prefix}/nginx/conf /etc/nginx [ -e /usr/sbin/nginx ] || ln -s %{prefix}/nginx/sbin/nginx %{ln_nginx} %files /* %doc %changelog %preun for f in %{prefix}/bin/*; do unlink /usr/bin/$(basename $f);done [ -h %{ln_nginx} ] && [ $(readlink -f %{ln_nginx}) = "%{prefix}/nginx/sbin/nginx" ] && unlink /usr/sbin/nginx |
注释
#标识注释, 注释中的%也需要用%%代替,否则也会执行宏扩展
关于PHP打rpm包:
- 由于扩展的安装没有参考prefix的定义,而是直接安装到系统里面的,所以执行%makeinstall 时,并没有将扩展安装到buildroot下,所以,打包的时候就打不进去,这个需要看一下如何解决
调试技巧
- rpm打包比较浪费时间的事情是: 源码编译耗时比较长,但是spec文件容易写错,编译出问题的情况比较好解决,因为通常会把编译没有问题的命令贴到spec文件中,问题是安装部分可能会不是太满意,需要多次调试,而rpm打包总是经历编译的步骤,失败后编译使用的临时文件和目录都会删除掉,就是说,每次调试都要经历漫长的编译,然后发现安装部分还是有点儿小问题;解决办法:
办法1: 写spec文件时不删除已编译的文件,下次把%setup %config %build 部分都去掉,直接install,不过这时候需要在install的时候显式的cd到指定的目录
办法2: 直接提供编译好的文件作为源文件,然后spec文件中不写编译语句
办法3: make 时添加选项: %{?_smp_mflags} 即:如果是多处理器的话则并行编译
- 如何了解rpm打包每个步骤都做了什么?
rpm的好些阶段都是可以直接写shell命令的,我们不妨添加一些暂停语句使之暂停来查看其生成的中间脚本文件,如:添加 read -p “press enter to continue…” ,示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
Name: beebank-test Version: 1.0.0 Release: 1 Summary: phpor's hello world Group: Development/Languages License: BSD URL: http://phpor.net Source0: beebank-test-1.0.0.tar.gz %description test %prep read -p "prep ok , press enter to continue..." %setup -q read -p "setup ok , press enter to continue..." %build read -p "build ok , press enter to continue..." %configure read -p "configure ok , press enter to continue..." make read -p "make ok , press enter to continue..." %install read -p "install ok , press enter to continue..." %makeinstall read -p "makeinstall ok , press enter to continue..." %files /usr/bin/hello %config /etc/hello.conf %doc %changelog |
rpmbuild中间脚本文件:
实例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
#!/bin/sh RPM_SOURCE_DIR="/home/phpor/rpmbuild/SOURCES" RPM_BUILD_DIR="/home/phpor/rpmbuild/BUILD" RPM_OPT_FLAGS="-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector --param=ssp-buffer-size=4 -m64 -mtune=generic" RPM_ARCH="x86_64" RPM_OS="linux" export RPM_SOURCE_DIR RPM_BUILD_DIR RPM_OPT_FLAGS RPM_ARCH RPM_OS RPM_DOC_DIR="/usr/share/doc" export RPM_DOC_DIR RPM_PACKAGE_NAME="beebank-test" RPM_PACKAGE_VERSION="1.0.0" RPM_PACKAGE_RELEASE="1" export RPM_PACKAGE_NAME RPM_PACKAGE_VERSION RPM_PACKAGE_RELEASE LANG=C export LANG unset CDPATH DISPLAY ||: RPM_BUILD_ROOT="/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64" export RPM_BUILD_ROOT PKG_CONFIG_PATH="${PKG_CONFIG_PATH}:/usr/lib64/pkgconfig:/usr/share/pkgconfig" export PKG_CONFIG_PATH set -x umask 022 cd "/home/phpor/rpmbuild/BUILD" [ "$RPM_BUILD_ROOT" != "/" ] && rm -rf "${RPM_BUILD_ROOT}" mkdir -p `dirname "$RPM_BUILD_ROOT"` mkdir "$RPM_BUILD_ROOT" cd 'beebank-test-1.0.0' LANG=C export LANG unset DISPLAY /usr/bin/make \ prefix=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr \ exec_prefix=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr \ bindir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/bin \ sbindir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/sbin \ sysconfdir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/etc \ datadir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/share \ includedir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/include \ libdir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/lib64 \ libexecdir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/libexec \ localstatedir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/var \ sharedstatedir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/var/lib \ mandir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/share/man \ infodir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/share/info \ install sleep 100 /usr/lib/rpm/find-debuginfo.sh --strict-build-id "/home/phpor/rpmbuild/BUILD/beebank-test-1.0.0" /usr/lib/rpm/check-buildroot /usr/lib/rpm/redhat/brp-compress /usr/lib/rpm/redhat/brp-strip-static-archive /usr/bin/strip /usr/lib/rpm/redhat/brp-strip-comment-note /usr/bin/strip /usr/bin/objdump /usr/lib/rpm/brp-python-bytecompile /usr/bin/python /usr/lib/rpm/redhat/brp-python-hardlink /usr/lib/rpm/redhat/brp-java-repack-jars |
从该脚本来看,里面并没有出现解压缩源码包(%setup)部分的逻辑,即:其中没有包含%prep %setup 部分逻辑,而是从%build部分开始的,%build 逻辑:
|
|
# rpm --eval '%build' %build LANG=C export LANG unset DISPLAY |
其实,%prep (包含%setup逻辑)是一个单独的临时脚本文件,如下:
Executing(%prep): /bin/sh -e /var/tmp/rpm-tmp.L3sv7t
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# cat /var/tmp/rpm-tmp.L3sv7t #!/bin/sh RPM_SOURCE_DIR="/home/phpor/rpmbuild/SOURCES" RPM_BUILD_DIR="/home/phpor/rpmbuild/BUILD" RPM_OPT_FLAGS="-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector --param=ssp-buffer-size=4 -m64 -mtune=generic" RPM_ARCH="x86_64" RPM_OS="linux" export RPM_SOURCE_DIR RPM_BUILD_DIR RPM_OPT_FLAGS RPM_ARCH RPM_OS RPM_DOC_DIR="/usr/share/doc" export RPM_DOC_DIR RPM_PACKAGE_NAME="beebank-test" RPM_PACKAGE_VERSION="1.0.0" RPM_PACKAGE_RELEASE="1" export RPM_PACKAGE_NAME RPM_PACKAGE_VERSION RPM_PACKAGE_RELEASE LANG=C export LANG unset CDPATH DISPLAY ||: RPM_BUILD_ROOT="/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64" export RPM_BUILD_ROOT PKG_CONFIG_PATH="${PKG_CONFIG_PATH}:/usr/lib64/pkgconfig:/usr/share/pkgconfig" export PKG_CONFIG_PATH set -x umask 022 cd "/home/phpor/rpmbuild/BUILD" LANG=C export LANG unset DISPLAY read -p "prep ok , press enter to continue..." cd '/home/phpor/rpmbuild/BUILD' rm -rf 'beebank-test-1.0.0' /usr/bin/gzip -dc '/home/phpor/rpmbuild/SOURCES/beebank-test-1.0.0.tar.gz' | /bin/tar -xf - STATUS=$? if [ $STATUS -ne 0 ]; then exit $STATUS fi cd 'beebank-test-1.0.0' /bin/chmod -Rf a+rX,u+w,g-w,o-w . read -p "setup ok , press enter to continue..." exit 0 |
%build 部分是一个单独的脚本,一般包含./configure && make,如下:
Executing(%build): /bin/sh -e /var/tmp/rpm-tmp.oaK7vF
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
#!/bin/sh RPM_SOURCE_DIR="/home/phpor/rpmbuild/SOURCES" RPM_BUILD_DIR="/home/phpor/rpmbuild/BUILD" RPM_OPT_FLAGS="-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector --param=ssp-buffer-size=4 -m64 -mtune=generic" RPM_ARCH="x86_64" RPM_OS="linux" export RPM_SOURCE_DIR RPM_BUILD_DIR RPM_OPT_FLAGS RPM_ARCH RPM_OS RPM_DOC_DIR="/usr/share/doc" export RPM_DOC_DIR RPM_PACKAGE_NAME="beebank-test" RPM_PACKAGE_VERSION="1.0.0" RPM_PACKAGE_RELEASE="1" export RPM_PACKAGE_NAME RPM_PACKAGE_VERSION RPM_PACKAGE_RELEASE LANG=C export LANG unset CDPATH DISPLAY ||: RPM_BUILD_ROOT="/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64" export RPM_BUILD_ROOT PKG_CONFIG_PATH="${PKG_CONFIG_PATH}:/usr/lib64/pkgconfig:/usr/share/pkgconfig" export PKG_CONFIG_PATH set -x umask 022 cd "/home/phpor/rpmbuild/BUILD" cd 'beebank-test-1.0.0' LANG=C export LANG unset DISPLAY read -p "build ok , press enter to continue..." CFLAGS="${CFLAGS:--O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector --param=ssp-buffer-size=4 -m64 -mtune=generic}" ; export CFLAGS ; CXXFLAGS="${CXXFLAGS:--O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector --param=ssp-buffer-size=4 -m64 -mtune=generic}" ; export CXXFLAGS ; FFLAGS="${FFLAGS:--O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector --param=ssp-buffer-size=4 -m64 -mtune=generic -I/usr/lib64/gfortran/modules}" ; export FFLAGS ; ./configure --build=x86_64-redhat-linux-gnu --host=x86_64-redhat-linux-gnu \ --target=x86_64-redhat-linux-gnu \ --program-prefix= \ --prefix=/usr \ --exec-prefix=/usr \ --bindir=/usr/bin \ --sbindir=/usr/sbin \ --sysconfdir=/etc \ --datadir=/usr/share \ --includedir=/usr/include \ --libdir=/usr/lib64 \ --libexecdir=/usr/libexec \ --localstatedir=/var \ --sharedstatedir=/var/lib \ --mandir=/usr/share/man \ --infodir=/usr/share/info read -p "configure ok , press enter to continue..." make read -p "make ok , press enter to continue..." exit 0 |
%install是单独一个中间shell脚本,如下:
Executing(%install): /bin/sh -e /var/tmp/rpm-tmp.f9kumb
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
#!/bin/sh RPM_SOURCE_DIR="/home/phpor/rpmbuild/SOURCES" RPM_BUILD_DIR="/home/phpor/rpmbuild/BUILD" RPM_OPT_FLAGS="-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector --param=ssp-buffer-size=4 -m64 -mtune=generic" RPM_ARCH="x86_64" RPM_OS="linux" export RPM_SOURCE_DIR RPM_BUILD_DIR RPM_OPT_FLAGS RPM_ARCH RPM_OS RPM_DOC_DIR="/usr/share/doc" export RPM_DOC_DIR RPM_PACKAGE_NAME="beebank-test" RPM_PACKAGE_VERSION="1.0.0" RPM_PACKAGE_RELEASE="1" export RPM_PACKAGE_NAME RPM_PACKAGE_VERSION RPM_PACKAGE_RELEASE LANG=C export LANG unset CDPATH DISPLAY ||: RPM_BUILD_ROOT="/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64" export RPM_BUILD_ROOT PKG_CONFIG_PATH="${PKG_CONFIG_PATH}:/usr/lib64/pkgconfig:/usr/share/pkgconfig" export PKG_CONFIG_PATH set -x umask 022 cd "/home/phpor/rpmbuild/BUILD" [ "$RPM_BUILD_ROOT" != "/" ] && rm -rf "${RPM_BUILD_ROOT}" mkdir -p `dirname "$RPM_BUILD_ROOT"` mkdir "$RPM_BUILD_ROOT" cd 'beebank-test-1.0.0' LANG=C export LANG unset DISPLAY read -p "install ok , press enter to continue..." /usr/bin/make \ prefix=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr \ exec_prefix=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr \ bindir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/bin \ sbindir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/sbin \ sysconfdir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/etc \ datadir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/share \ includedir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/include \ libdir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/lib64 \ libexecdir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/libexec \ localstatedir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/var \ sharedstatedir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/var/lib \ mandir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/share/man \ infodir=/home/phpor/rpmbuild/BUILDROOT/beebank-test-1.0.0-1.x86_64/usr/share/info \ install read -p "makeinstall ok , press enter to continue..." /usr/lib/rpm/find-debuginfo.sh --strict-build-id "/home/phpor/rpmbuild/BUILD/beebank-test-1.0.0" /usr/lib/rpm/check-buildroot /usr/lib/rpm/redhat/brp-compress /usr/lib/rpm/redhat/brp-strip-static-archive /usr/bin/strip /usr/lib/rpm/redhat/brp-strip-comment-note /usr/bin/strip /usr/bin/objdump /usr/lib/rpm/brp-python-bytecompile /usr/bin/python /usr/lib/rpm/redhat/brp-python-hardlink /usr/lib/rpm/redhat/brp-java-repack-jars |
其中包含生成debuginfo,如果不想生成debuginfo,则可以在 ~/.rpmmacros 中添加:
参考: 制作PHP rpm包