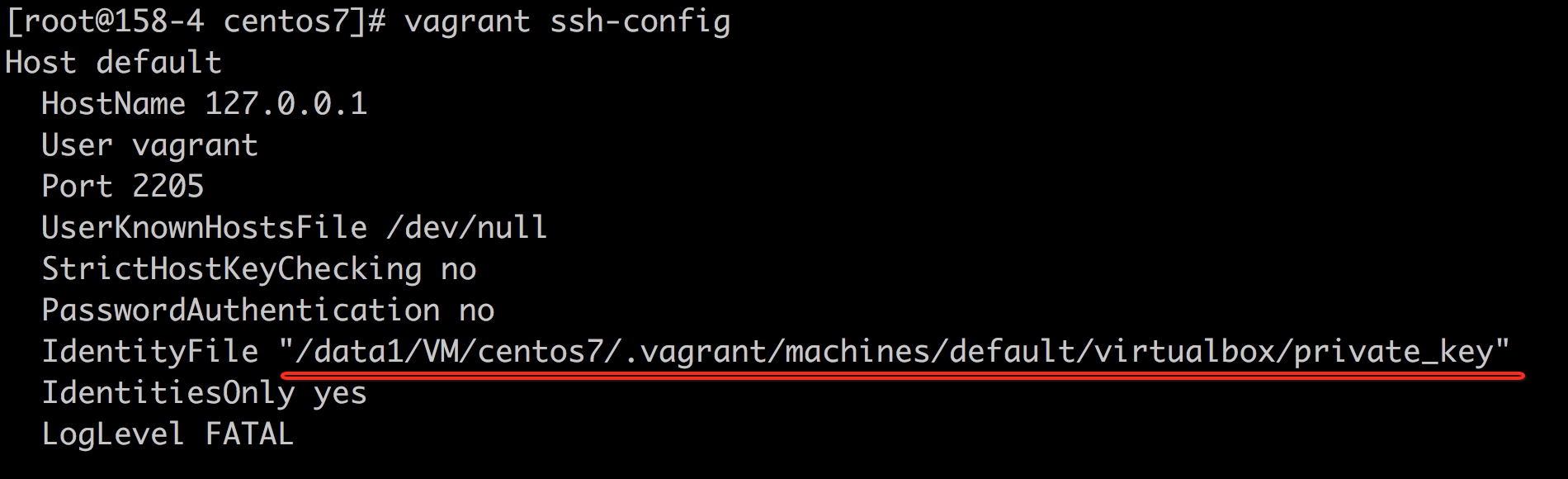
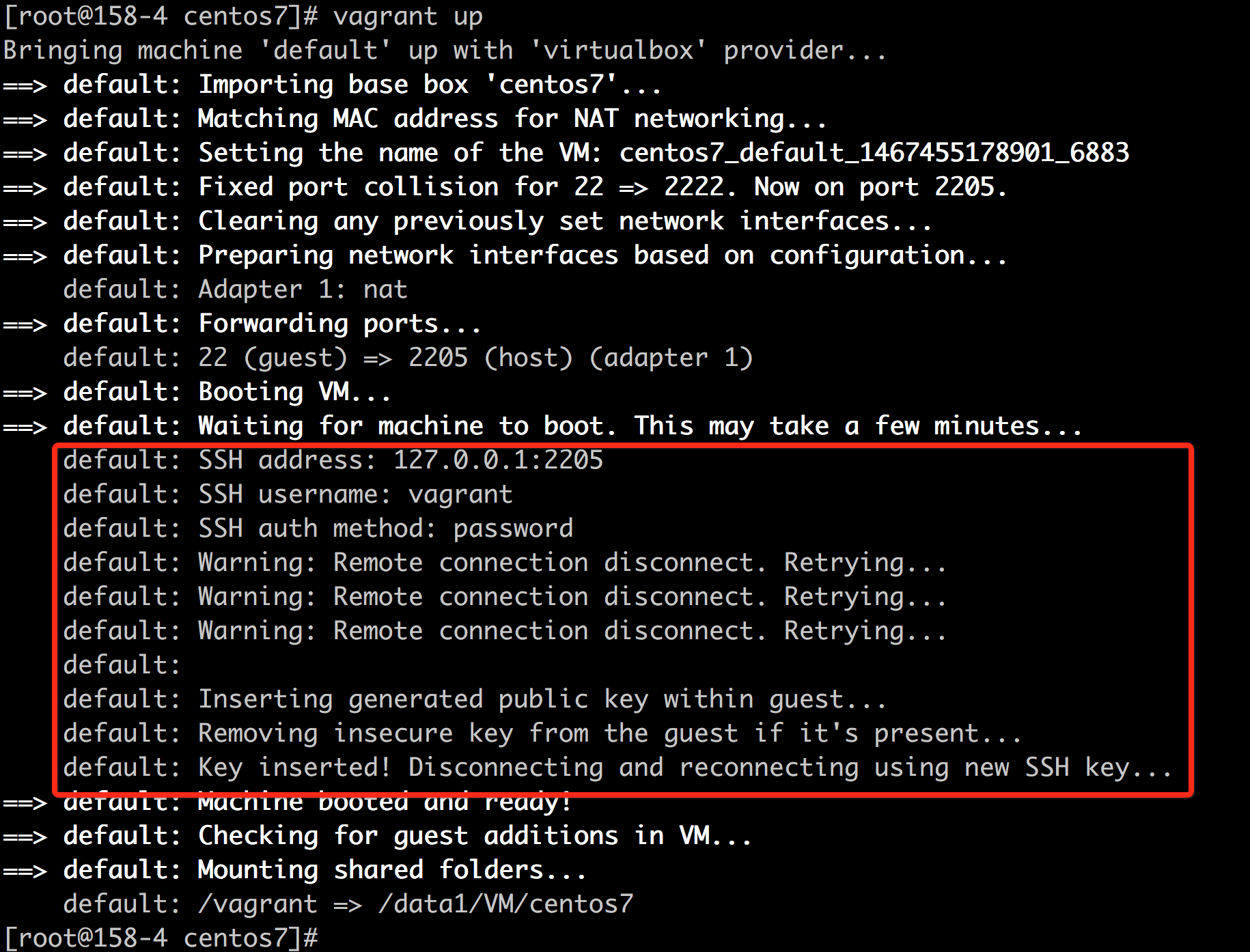
probe process("sapi/cli/php").provider("php").mark("compile__file__entry") {
printf("Probe compile__file__entry\n");
printf(" compile_file %s\n", user_string($arg1));
printf(" compile_file_translated %s\n", user_string($arg2));
}
probe process("sapi/cli/php").provider("php").mark("compile__file__return") {
printf("Probe compile__file__return\n");
printf(" compile_file %s\n", user_string($arg1));
printf(" compile_file_translated %s\n", user_string($arg2));
}
probe process("sapi/cli/php").provider("php").mark("error") {
printf("Probe error\n");
printf(" errormsg %s\n", user_string($arg1));
printf(" request_file %s\n", user_string($arg2));
printf(" lineno %d\n", $arg3);
}
probe process("sapi/cli/php").provider("php").mark("exception__caught") {
printf("Probe exception__caught\n");
printf(" classname %s\n", user_string($arg1));
}
probe process("sapi/cli/php").provider("php").mark("exception__thrown") {
printf("Probe exception__thrown\n");
printf(" classname %s\n", user_string($arg1));
}
probe process("sapi/cli/php").provider("php").mark("execute__entry") {
printf("Probe execute__entry\n");
printf(" request_file %s\n", user_string($arg1));
printf(" lineno %d\n", $arg2);
}
probe process("sapi/cli/php").provider("php").mark("execute__return") {
printf("Probe execute__return\n");
printf(" request_file %s\n", user_string($arg1));
printf(" lineno %d\n", $arg2);
}
probe process("sapi/cli/php").provider("php").mark("function__entry") {
printf("Probe function__entry\n");
printf(" function_name %s\n", user_string($arg1));
printf(" request_file %s\n", user_string($arg2));
printf(" lineno %d\n", $arg3);
printf(" classname %s\n", user_string($arg4));
printf(" scope %s\n", user_string($arg5));
}
probe process("sapi/cli/php").provider("php").mark("function__return") {
printf("Probe function__return: %s\n", user_string($arg1));
printf(" function_name %s\n", user_string($arg1));
printf(" request_file %s\n", user_string($arg2));
printf(" lineno %d\n", $arg3);
printf(" classname %s\n", user_string($arg4));
printf(" scope %s\n", user_string($arg5));
}
probe process("sapi/cli/php").provider("php").mark("request__shutdown") {
printf("Probe request__shutdown\n");
printf(" file %s\n", user_string($arg1));
printf(" request_uri %s\n", user_string($arg2));
printf(" request_method %s\n", user_string($arg3));
}
probe process("sapi/cli/php").provider("php").mark("request__startup") {
printf("Probe request__startup\n");
printf(" file %s\n", user_string($arg1));
printf(" request_uri %s\n", user_string($arg2));
printf(" request_method %s\n", user_string($arg3));
}