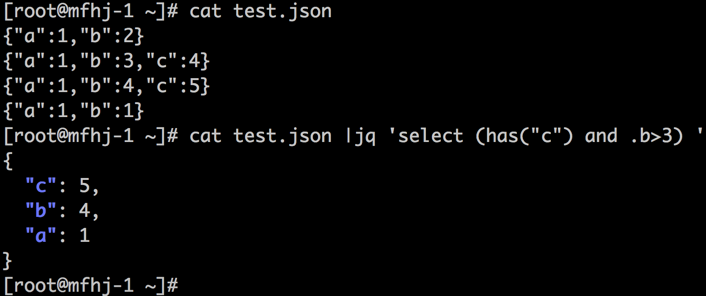
Delve is a debugger for the Go programming language. The goal of the project is to provide a simple, full featured debugging tool for Go. Delve should be easy to invoke and easy to use. Chances are if you’re using a debugger, most likely things aren’t going your way. With that in mind, Delve should stay out of your way as much as possible.
tcpstat reports certain network interface statistics much like vmstat does for system statistics. tcpstat gets its information by either monitoring a specific interface, or by reading previously saved tcpdump data from a file.
tcprstat is a free, open-source TCP analysis tool that watches network traffic and computes the delay between requests and responses.
tcprstat is related to the tcpstat tool, but it focuses on response time measurements, not on the amount and size of the network traffic. This makes it useful for response time analysis, which is needed for techniques such as Goal-Driven Performance Optimization.
The advantages of tcprstat are as follows:
It is lightweight and unobtrusive. No bulky log files need be written and analyzed.
Requests and responses are timed with microsecond resolution.
The output is easy to import into spreadsheets, manipulate with command-line scripts, graph with gnuplot, and so on.
It is protocol-agnostic, and works well for a large variety of client-server protocols that have a simple request-response model.