锁的类型: 表锁、页锁、行锁、间隙锁【读锁(共享锁)、写锁(排他锁)】、乐观锁、悲观锁(晕,其实没这么多东西)
mysql.INNODB_LOCKS 这张表记录了发生了锁争用的信息;虽然一个事务正在加了一些锁,如果没有其它session等待这些锁的话,这个表里面也是查不到的哦
但是,A表正在事务中被更新时,如果:
lock tables A write;
虽然被阻塞,但是 mysql.INNODB_LOCKS里面却查不到任何记录! (why: lock tables 不是存储引擎级别的锁)
实例分析:
表结构:
|
|
CREATE TABLE `credit_core` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `uid` int(10) unsigned NOT NULL, `app_id` int(10) unsigned NOT NULL, `limit` int(10) unsigned NOT NULL DEFAULT '0', PRIMARY KEY (`id`), UNIQUE KEY `uniq_uid_appid` (`uid`,`app_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 |
sql语句1:
|
|
begin; select * from credit_core where uid=153 and app_id = 1 for update; insert into credit_core(uid, appid, `limit`) values(153, 1, 1000); commit; |
sql语句2:
|
|
begin; select * from credit_core where uid=154 and app_id = 1 for update; insert into credit_core(uid, appid, `limit`) values(154, 1, 1000); commit; |
如果简单认为innodb的锁都是行锁(尤其是select和insert操作的压根儿也不是一行),怎么可能发生死锁呢?
让我们模拟一下,分别在两个session中一行一行地交替执行两个事务,我们发现,确实在insert的时候死锁了
session 1:
|
|
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from credit_core where uid=153 and app_id = 1 for update; Empty set (0.00 sec) mysql> insert into credit_core(uid, app_id, `limit`) values(153, 1, 1000); #这里开始等待锁,第二个session执行到insert时,会发现死锁,然后取消事务并退出,然后,本sql得到锁并成功执行了 Query OK, 1 row affected (15.98 sec) mysql> |
session 2:
|
|
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from credit_core where uid=154 and app_id = 1 for update; Empty set (0.00 sec) mysql> insert into credit_core(uid, app_id, `limit`) values(154, 1, 1000); ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction mysql> |
如果我们不着急去执行session 2中的insert的语句,而是查询一下存在哪些锁,发现如下:
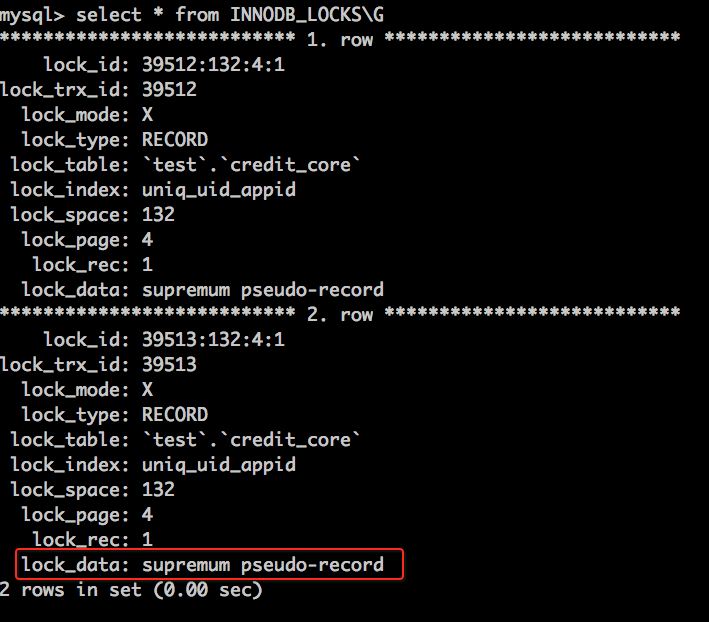
什么是supremum pseudo-record?
supremum pseudo-record :相当于比索引中所有值都大,但却不存在索引中,相当于最后一行之后的间隙锁
解决办法:
|
|
START TRANSACTION; insert into ... on duplicate key update `val`='XX'; commit; |
参看: http://blog.itpub.net/26250550/viewspace-1070422/
问题: 两个select … for update ; 加的是共享锁?否则不能同时两个select语句都能成功执行。还如何查证?
不能简单地说 select … for update 加的是共享锁还是排他锁; 如果select有结果,则加行锁,此时为排他锁; 如果没有结果,则加间隙锁,此时为共享锁(和间隙大小没有关系); 如果没有在事务中,则select for update是不加锁的;
参看: Enabling InnoDB Monitors: https://dev.mysql.com/doc/refman/5.6/en/innodb-enabling-monitors.html
|
|
set GLOBAL innodb_status_output_locks=ON; |
可以查看当前被设置的锁的信息:
|
|
SHOW ENGINE INNODB STATUS\G |
部分信息如下:
|
|
---TRANSACTION 39527, ACTIVE 3 sec 2 lock struct(s), heap size 360, 1 row lock(s) MySQL thread id 37, OS thread handle 0x7f5fb0733700, query id 458 localhost root cleaning up TABLE LOCK table `test`.`credit_core` trx id 39527 lock mode IX RECORD LOCKS space id 132 page no 4 n bits 72 index `uniq_uid_appid` of table `test`.`credit_core` trx id 39527 lock_mode X Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0 0: len 8; hex 73757072656d756d; asc supremum;; |
下面是insert 语句等待时的锁情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
mysql> select * from INNODB_LOCKS\G *************************** 1. row *************************** lock_id: 39515:132:4:1 lock_trx_id: 39515 lock_mode: X lock_type: RECORD lock_table: `test`.`credit_core` lock_index: uniq_uid_appid lock_space: 132 lock_page: 4 lock_rec: 1 lock_data: supremum pseudo-record *************************** 2. row *************************** lock_id: 39514:132:4:1 lock_trx_id: 39514 lock_mode: X lock_type: RECORD lock_table: `test`.`credit_core` lock_index: uniq_uid_appid lock_space: 132 lock_page: 4 lock_rec: 1 lock_data: supremum pseudo-record 2 rows in set (0.00 sec) mysql> select * from INNODB_TRX\G *************************** 1. row *************************** trx_id: 39515 trx_state: LOCK WAIT trx_started: 2015-12-25 15:15:50 trx_requested_lock_id: 39515:132:4:1 trx_wait_started: 2015-12-25 15:25:24 trx_weight: 4 trx_mysql_thread_id: 35 trx_query: insert into credit_core(uid, app_id, `limit`) values(153, 1, 1000) trx_operation_state: inserting trx_tables_in_use: 1 trx_tables_locked: 1 trx_lock_structs: 3 trx_lock_memory_bytes: 360 trx_rows_locked: 2 trx_rows_modified: 1 trx_concurrency_tickets: 0 trx_isolation_level: REPEATABLE READ trx_unique_checks: 1 trx_foreign_key_checks: 1 trx_last_foreign_key_error: NULL trx_adaptive_hash_latched: 0 trx_adaptive_hash_timeout: 10000 trx_is_read_only: 0 trx_autocommit_non_locking: 0 *************************** 2. row *************************** trx_id: 39514 trx_state: RUNNING trx_started: 2015-12-25 15:15:40 trx_requested_lock_id: NULL trx_wait_started: NULL trx_weight: 2 trx_mysql_thread_id: 37 trx_query: NULL trx_operation_state: NULL trx_tables_in_use: 0 trx_tables_locked: 0 trx_lock_structs: 2 trx_lock_memory_bytes: 360 trx_rows_locked: 1 trx_rows_modified: 0 trx_concurrency_tickets: 0 trx_isolation_level: REPEATABLE READ trx_unique_checks: 1 trx_foreign_key_checks: 1 trx_last_foreign_key_error: NULL trx_adaptive_hash_latched: 0 trx_adaptive_hash_timeout: 10000 trx_is_read_only: 0 trx_autocommit_non_locking: 0 2 rows in set (0.00 sec) |
学习资料:
http://hedengcheng.com/?p=771 非常不错