cloud-init 工作原理 – 每天5分钟玩转 OpenStack(171) – CloudMan6的博客 – CSDN博客
Management Tools – KVM
mac brew HOMEBREW_NO_GITHUB_API
brew install spinx-build 的时候可能会遇到如下错误:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
/System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/lib/ruby/2.0.0/open-uri.rb:353:in `open_http': 422 Unprocessable Entity (GitHub::Error) from /System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/lib/ruby/2.0.0/open-uri.rb:709:in `buffer_open' from /System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/lib/ruby/2.0.0/open-uri.rb:210:in `block in open_loop' from /System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/lib/ruby/2.0.0/open-uri.rb:208:in `catch' from /System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/lib/ruby/2.0.0/open-uri.rb:208:in `open_loop' from /System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/lib/ruby/2.0.0/open-uri.rb:149:in `open_uri' from /System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/lib/ruby/2.0.0/open-uri.rb:689:in `open' from /System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/lib/ruby/2.0.0/open-uri.rb:30:in `open' from /usr/local/Library/Homebrew/utils.rb:367:in `open' from /usr/local/Library/Homebrew/utils.rb:397:in `issues_matching' from /usr/local/Library/Homebrew/utils.rb:425:in `issues_for_formula' from /usr/local/Library/Homebrew/exceptions.rb:145:in `fetch_issues' from /usr/local/Library/Homebrew/exceptions.rb:141:in `issues' from /usr/local/Library/Homebrew/exceptions.rb:184:in `dump' from /usr/local/Library/brew.rb:167:in `rescue in <main>' from /usr/local/Library/brew.rb:65:in `<main>' |
修改 /usr/local/Library/Homebrew/utils.rb 的代码,打印url看看:
|
1 |
https://api.github.com/search/issues?q=sphinx+repo:Homebrew/homebrew+in:title+state:open&per_page=100 |
莫非访问不了api.github.com ?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$ curl "https://api.github.com/search/issues?q=sphinx+repo:Homebrew/homebrew+in:title+state:open&per_page=100" { "message": "Validation Failed", "errors": [ { "message": "The listed users and repositories cannot be searched either because the resources do not exist or you do not have permission to view them.", "resource": "Search", "field": "q", "code": "invalid" } ], "documentation_url": "https://developer.github.com/v3/search/" } |
看起来是有返回值的,而且是合法的json,继续看 /System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/lib/ruby/2.0.0/open-uri.rb 的代码,发现很可能是httpcode的问题:
|
1 |
curl -v "https://api.github.com/search/issues?q=sphinx+repo:Homebrew/homebrew+in:title+state:open&per_page=100" |
发现http code为 422 , 而/System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/lib/ruby/2.0.0/open-uri.rb 遇到 422 是走异常逻辑的,如果能简单修改代码使其认为是正常似乎是可以的; 但是mac 不让修改/System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/lib/ruby/2.0.0/open-uri.rb , root账号也不行
回头看 /usr/local/Library/Homebrew/utils.rb ,发现如下逻辑:

export HOMEBREW_NO_GITHUB_API=1
问题解决
其实 spinx-build 是在生成man page的时候用到的,某些情况下,大可不必非要去生成man page
虚拟机镜像操作
软件包: libguestfs-tools
这里的 guestfish 挺不错的
- 查看镜像分区及其使用情况:
12345# virt-df -a centos7.3.raw -h|column -t文件系统 大小 已用空间 可用空间 使用百分比%centos7.3.raw:/dev/sda2 497M 147M 350M 30%centos7.3.raw:/dev/sda5 100M 0 100M 0%centos7.3.raw:/dev/sda6 42G 2.1G 40G 5% - 查看镜像中的文件信息
1virt-ls -a centos7.3.img -l / - copy 文件到镜像
1virt-copy-in -a centos7.3.img /tmp/hello.txt /tmp/ - 查看镜像中的文件
1virt-cat -a centos7.3.img /tmp/hello.txt - 查看镜像中的文件系统分区信息: virt-filesystems –long –parts –blkdevs -h -a CentOS-7-x86_64-GenericCloud-1708.raw
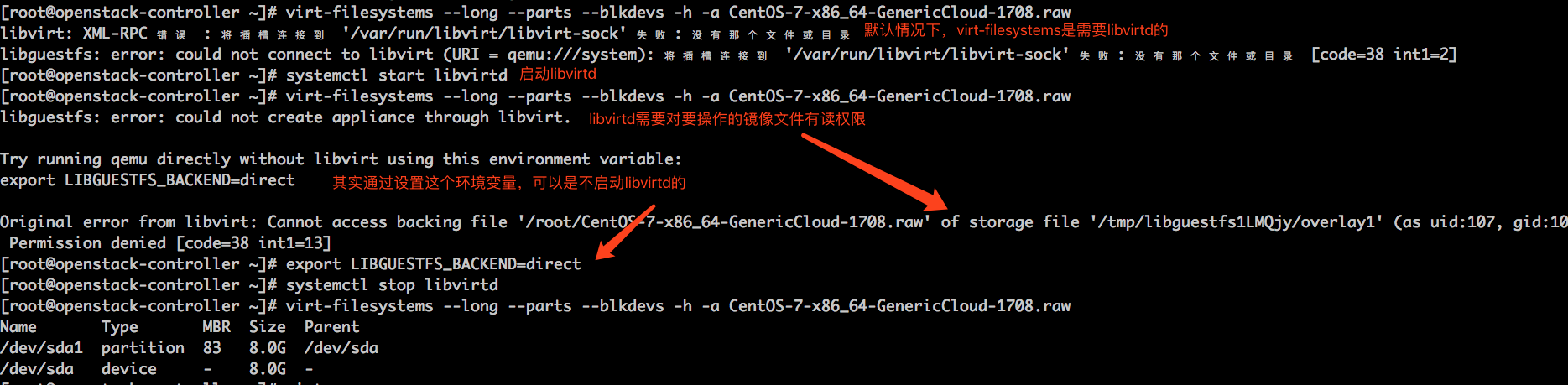
virt-resize: –shrink 并不能让镜像文件变的更小(反而变大了)

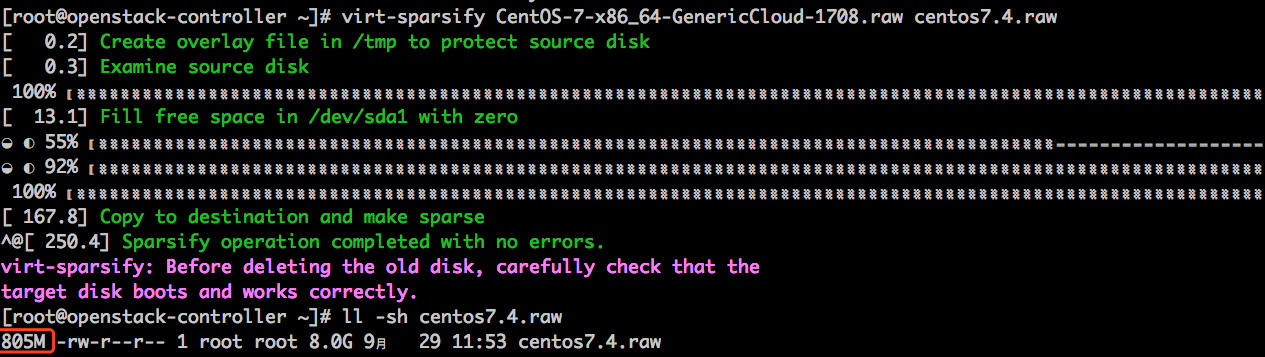
virt-sparsify 可以使得一个镜像文件变成一个稀疏文件,对于发布、存储镜像很有必要
Building a cloud ready linux image locally using KVM | Ravello Blog
Refactoring a Dockerfile for Image Size
http://blog.replicated.com/refactoring-a-dockerfile-for-image-size/
1. 尽量减少不必要的包
2. 包管理器自动安装的包不一定都是必须的,可能只是建议安装
resolv.conf 之options都有啥
- 你没法通过options来禁用ipv6解析
- single-request: 用来指定分别执行A和AAAA解析;即,收到A记录解析的结果后在发送AAAA记录解析请求; 默认情况下,同时在一个连接上发送A和AAAA的解析,这样效率会高一倍;然而,有些dns server不能很好地处理这种请求方式,很可能不能正确地返回AAAA的响应,以至于请求会超时
- single-request-reopen:强制A和AAAA的解析在两个连接中处理(主要体现在连接的源端口不同)
参考:
openstack 与 ldap的集成
按照下面参考中的做法,添加一个认证的中间件就可以搞定
参考: https://docs.openstack.org/keystone/latest/advanced-topics/external-auth.html
openstack dashboard之session timeout
文档中说在 /etc/openstack-dashboard/local_settings 中修改(或添加)SESSION_TIMEOUT 可以控制dashboard的过期时间,但是修改了怎么也不生效,后看代码发现:
dashboard登录后总是去keystone获取一个token的,token总有过期时间的,所以,dashboard的session过期时间就是自己定义的过期时间和token的过期时间取小的那个。
keystone 的token过期时间配置参考: /etc/keystone/kestone.conf