Abrt(Automatic bug detection and reporting tool)
gdb tui
gdb 的tui模式看起来会舒服一些,不过,有时候可能会由于终端处理不好而花掉,此时可以ctrl-z 推到后台在回来,重绘就好了
进入tui模式的两种方式:
- 启动时使用-tui选项
- 启动后使用ctrl – x a
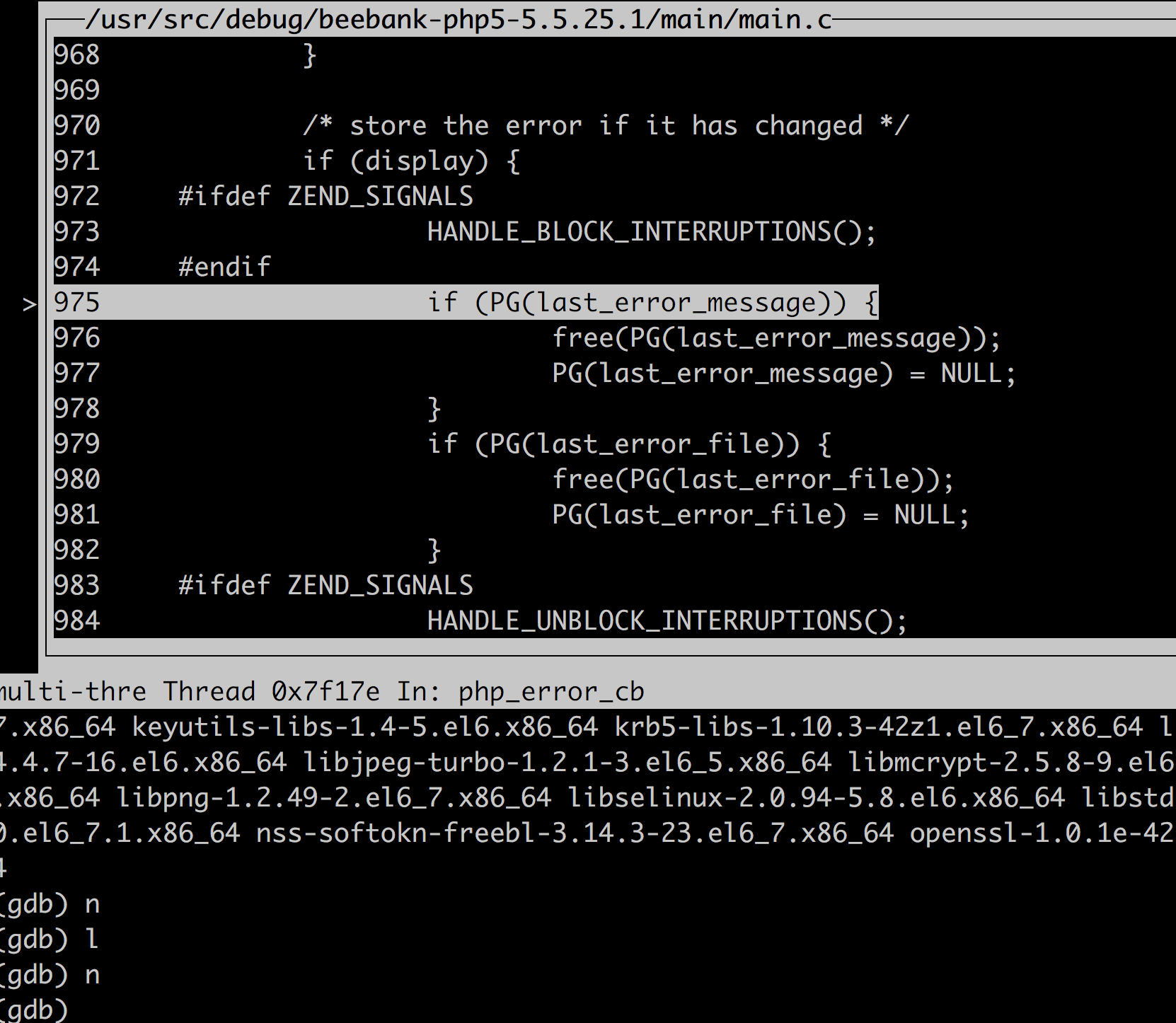
关于窗口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
help layout Change the layout of windows. Usage: layout prev | next | <layout_name> Layout names are: src : Displays source and command windows. asm : Displays disassembly and command windows. split : Displays source, disassembly and command windows. regs : Displays register window. If existing layout is source/command or assembly/command, the register window is displayed. If the source/assembly/command (split) is displayed, the register window is displayed with the window that has current logical focus. |
一共有4中展示方式:
- src: 显示源码窗口和命令窗口(如果是用纯汇编写的二进制程序,则源码窗口不会有东西的)
- asm: 显示汇编窗口和命令窗口
- split: 显示源码窗口、汇编窗口、命令窗口
- regs: 如果当前是源码窗口/汇编窗口和命令,则同时显示寄存器窗口,如果当前是split的,则。。。
ctrl+alt+j 可以快速切换窗口,所以有时候不必太过于纠结使用哪种layout
参考资料:
关于traceroute偶发超时的问题
刚配好的网络,traceroute测试一下:
|
1 |
traceroute -n 172.16.22.17 |
-n 是不需要ip反解析,执行会比较快;于是就遇到了今天的问题:快速执行几次该命令就会出现失败(*)的情况,如果执行的慢点儿倒是没有问题
分析:
- 可能是网络不稳定
- ping 测试,大量请求,无一丢包 (显然不是网络问题)
- 限速?
- traceroute 涉及的是udp和icmp,不放sysctl -a|grep rate 试试
原因如下:
该问题和内核的两个参数有关:icmp_ratelimit、icmp_ratemask
虽然 ping 也是icmp,但是这种类型的icmp默认没有速率限制,而端口不可达的icmp是有限制的,所以,ping没有问题,traceroute有问题
参考:
icmp_ratelimit : INTEGER
默认值是100 Jiffie
限制发向特定目标的匹配icmp_ratemask的ICMP数据报的最大速率。0表示没有任何限制,否则表示jiffies数据单位中允许发送的个数。(如果在icmp_ratemask进行相应的设置Echo Request的标志位掩码设置为1,那么就可以很容易地做到ping回应的速度限制了)
icmp_ratemask : INTEGER
在这里匹配的ICMP被icmp_ratelimit参数限制速率.
匹配的标志位: IHGFEDCBA9876543210
默认的掩码值: 0000001100000011000 (6168 十进制)
关于标志位的设置,可参考 源程序目录/include/linux/icmp.h
0 Echo Reply
3 Destination Unreachable *
4 Source Quench *
5 Redirect
8 Echo Request
B Time Exceeded *
C Parameter Problem *
D Timestamp Request
E Timestamp Reply
F Info Request
G Info Reply
H Address Mask Request
I Address Mask Reply
* 号的被默认限速(见上表mask)
匹配的标志位: IHGFEDCBA9876543210
默认的掩码值: 0000001100 0 0 0 0 1 1001 (6169 十进制)
0 Echo Reply 掩码匹配
关于cmdline
/proc/$pid/cmdline 记录的是进程的显示名,默认是命令行中的信息,但是也可以修改,比如,php中使用cli_set_process_title()可以修改cmdline;
需要注意的是:
- 如果原本的 cmdline 比较长,而修改后的比较短,则cmdline保留原来的长度,多余的部分被修改为’\0’,所以,获取的时候需要处理一下,bash中可以使用strings,php中可以使用trim
- 如果原本的cmdline比较短,而修改后的比较长,则会被扩展,而不是截断
cmdline vs comm
/proc/$pid/comm 有16字节的限制
PowerShell 入门
PowerShell 是一个可以操作对象的高级shell,是一个支持模块的shell。
如何编写模块?参考:http://www.jb51.net/article/56229.htm 基本上就是在模块目录下写一个包含有一些函数的文件,一个这种文件就是一个模块,然后配之以一个同名(不同扩展名)的manifest文件
两种注释方式:
段注释:
|
1 2 3 4 5 |
<# .... #> |
行注释:
|
1 |
#this is comment |
实例:
web请求:
方法1:http://blog.csdn.net/qq_34352010/article/details/53572234
方法2:
|
1 |
PS3> $(New-Object -TypeName System.Net.WebClient).downloadstring("https://baidu.com") |
文本处理:
http://www.pstips.net/processing-text-1.html
http://www.pstips.net/processing-text-2.html
http://www.pstips.net/processing-text-3.html
解析url:http://www.pstips.net/processing-text-4.html
获取所有的IPv4地址:
|
1 2 3 4 |
PS C:\Users\phpor> ipconfig |Select-String ipv4 |ForEach-Object {$a=$_ -split ":" ; if($a) {$b=$a[1] -split "\(" ;$b[0].trim()}} 172.16.161.13 10.0.2.15 192.168.56.1 |
获取ifconfig的ipv4地址:
|
1 |
ifconfig|Select-String -Pattern "\s*inet\s([0-9.]+)"|foreach {$_.Matches.Groups[1].Value} |

注意: 正则表达式的正确使用使得事情变得更加利索
PowerShell 显示气球提示框: http://www.pstips.net/powershell-displaying-balloon-tip.html
多个对象之间用逗号分隔:
|
1 2 3 |
PS C:\Users\phpor> "a", "b" a b |
单引号与双引号:
|
1 2 3 4 5 6 7 |
PS C:\Users\phpor> $word="World" PS C:\Users\phpor> "Hello, $word" Hello, World PS C:\Users\phpor> 'Hello, $word' Hello, $word |
单引号中的单引号,双引号中的双引号:
|
1 2 3 4 5 |
PS C:\Users\phpor> """a""" "a" PS C:\Users\phpor> '''a''' 'a' |
单引号中连续的两个单引号解释为1个单引号,双引号中连续的两个双引号解释为1个双引号
转移字符
一般都是用反斜线转义,但是powershell中使用反引号来转义,如:
|
1 2 3 4 5 |
PS C:\Users\phpor> "a`"b" a"b PS C:\Users\phpor> "a`nb" a b |
命令结果赋值给变量的写法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
PS C:\Users\phpor> $a=$(get-date) PS C:\Users\phpor> $a 2017年2月18日 23:49:21 PS C:\Users\phpor> $a=get-date PS C:\Users\phpor> $a 2017年2月18日 23:49:32 PS C:\Users\phpor> |
使用 $( cmd ) 的写法更舒服一些,更加接近于bash的写法
ISE比命令行写起来会舒服一些,不但有提示,还方便查帮助
PowerShell是已模块的形式添加功能的
选中命令时,下面就会出现命令的参数信息,按住ctrl点击命令时,参数信息界面就会隐藏
Win7升级Powershell 2.0到3.0
参考: https://www.microsoft.com/en-us/download/details.aspx?id=34595
下载一个十几MB的msu文件,执行安装,重启就行
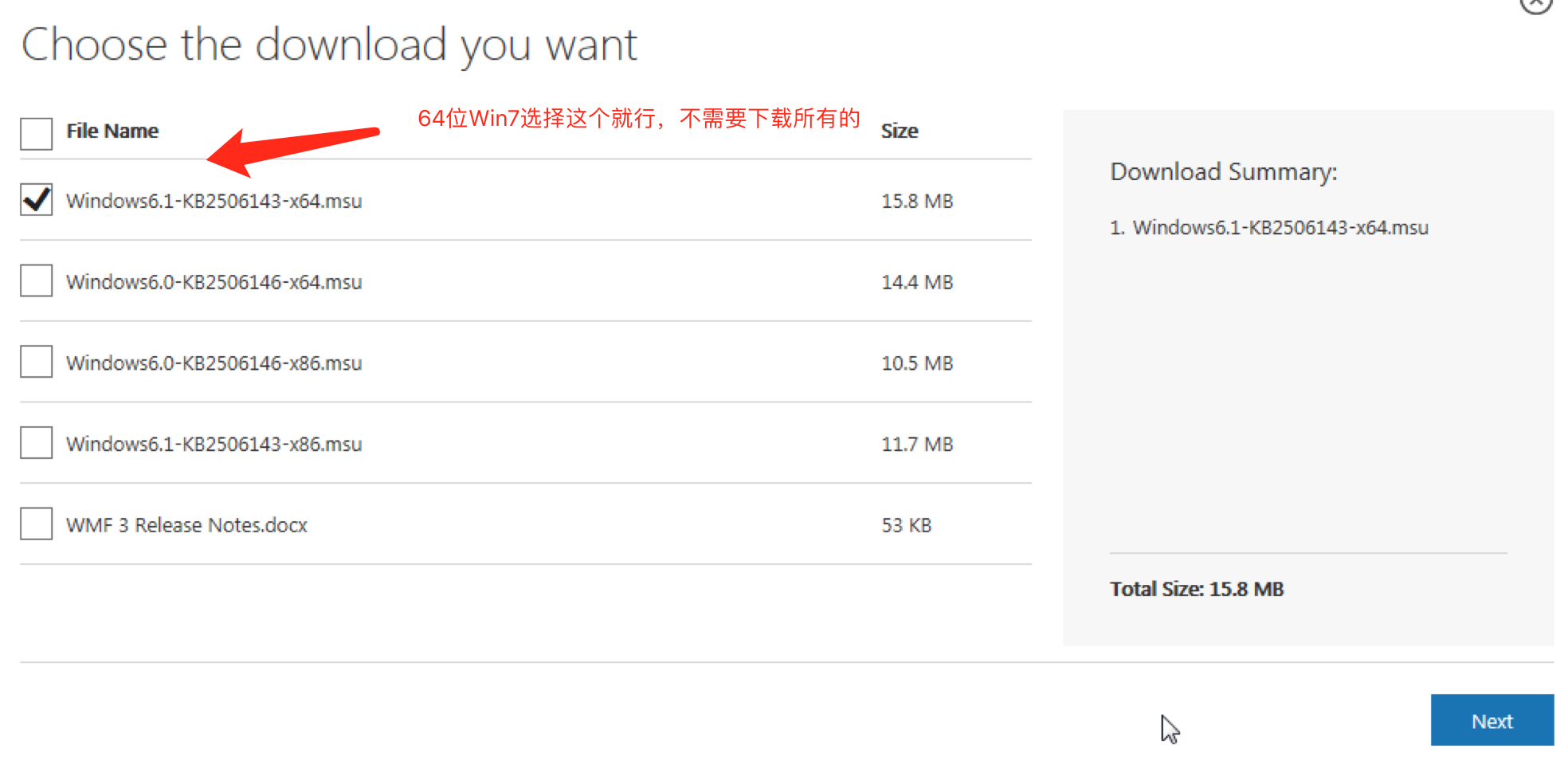
注意:
如果提示您的系统不支持该更新,则可以尝试更新一下系统,然后在安装,本人遇到问题后,安装了几十个更新之后就可以安装该安装包了;
或者先安装 dotNetFx45_Full_setup.exe ,在安装上面的下载也可以
使用 LVS 实现负载均衡原理及安装配置详解
我在看【使用 LVS 实现负载均衡原理及安装配置详解】, 分享给你, 快来看看吧! | http://mp.weixin.qq.com/s/eK_OUWLb8oO2RV0fZqeXFg
install win10 in vagrant
Virtualbox 磁盘整理
Virtualbox有两个很不爽的地方:
- 一旦占用了内存,将不会再释放;多个类似的虚拟机不能内存复用
- 磁盘文件很大,且每个虚拟机的磁盘都是一个完整的copy;一旦磁盘文件被撑大,就算内部文件已经被删除,磁盘文件也不会收缩
理论上可以压缩虚拟机的磁盘文件的,基本步骤为: (参考: http://www.cnblogs.com/findumars/p/3897818.html )
- 整理虚拟机磁盘
- 压缩虚拟机磁盘
磁盘工具:
windows: 下载: Sysinternals Suite 执行
|
1 |
sdelete -z c: |
该过程比较漫长
磁盘压缩方法:
|
1 |
VBoxManage modifyhd mydisk.vdi --compact |
30G 的磁盘文件可以压缩到22G