go mod 会产生大量cache,很多老旧的cache也不会自动删除,所以,没事儿要清理一下:
|
1 |
go clean -modcache |
DevOps
go mod 会产生大量cache,很多老旧的cache也不会自动删除,所以,没事儿要清理一下:
|
1 |
go clean -modcache |
缘起:
一个PHP进程本来看不到使用任何的多线程方法,但是,strace时却发现大量的clone调用,而且,ps时,还发现进程状态是Sl 的,随不解,gdb 探查之,发现如下堆栈:
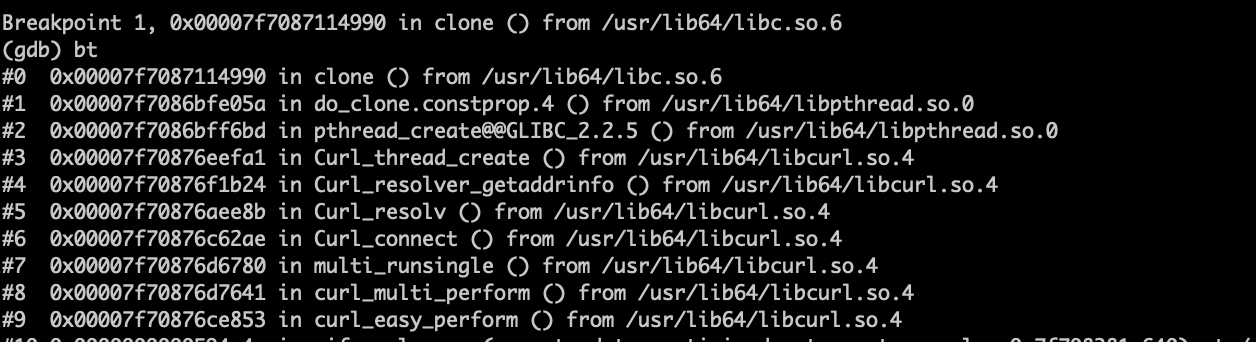
为什么一个简单的域名解析还需要劳驾线程呢?
寻找参考资料:
多线程中使用curl致coredump问题 – 云+社区 – 腾讯云 (tencent.com)
对于多线程的环境,libcurl如果使用 SIGALARM 来实现dns的查询超时控制的话,会有问题,所以,会考虑使用线程的方式来实现。
但是,对于PHP这种单线程环境来讲,使用SIGALARM 也没有问题。
libcurl编译时使用 –enable-ares 来避免使用线程做域名解析
看PHP7中的base64.c, 发现代码比想象的要长不少,仔细看了一下,发现对于不同的目标环境有一些优化,一部分优化就是关于sse的技术: What are SSE instruction sets and what do they do? (techjunkie.com)
该技术应该能优化很多算法。不过,代码看起来就比较晦涩了。

|
1 2 |
# echo "you are right"| gzip --stdout|php -r 'echo gzinflate(substr(file_get_contents("php://stdin"), 10, -8));' you are right |
|
1 2 |
$ echo "you are right"| gzip --stdout| gzip -d you are right |
测试实例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
package main import ( "bufio" "fmt" "net" "sync" ) func main() { addr := "127.0.0.1:8181" ln, err := net.Listen("tcp", addr) if err != nil { panic(err) return } conn1, err := net.Dial("tcp", addr) if err != nil { panic(err) } n, err := fmt.Fprintf(conn1, "client hello\n") if err != nil { panic(err) } if n == 0 { panic("应该能发送成功的") } wg := &sync.WaitGroup{} wg.Add(1) go func(conn net.Conn) { defer wg.Done() r := bufio.NewReader(conn) l, _ , _ := r.ReadLine() println("s:", string(l)) conn.Close() }(conn1) //ln.Close() // 如果这里 Close的话,下面的Accept就会失败,尽管上面有一个已经创建成功的连接 conn, err := ln.Accept() if err != nil { panic(err) } clientHello, _, _ := bufio.NewReader(conn).ReadLine() fmt.Println("c:", string(clientHello)) fmt.Fprintf(conn, "server hello\n") conn.Close() wg.Wait() } |
golang空结构体作为值传递时是不会copy的,都是同一个全局变量。
因为空结构体不管是什么类型,执行什么方法,都无法改变其内容,因为他没有内容,随意,这么干是安全的。