在Linux中,中断当前运行的进程的方法有两种:
- 中断键方式:通常是DELETE键或CTRL-C,信号为SIGINT,终止前台进程
- 退出键方式:通常是CTRL-\,信号为SIGQUIT,不但终止前台进程,还产生core文件
DevOps
在Linux中,中断当前运行的进程的方法有两种:
|
1 2 3 4 5 6 |
[phpor@net ~]$ str=`echo -e "A\nB"` [phpor@net ~]$ echo $str A B [phpor@net ~]$ echo "$str" A B |
如果$a=”a b”; 即:包含空格
前者: cmd接到的是2个参数
后者: cmd接到的是1个参数
举个栗子:如下图,我要把grep的那个关键字用变量替换:
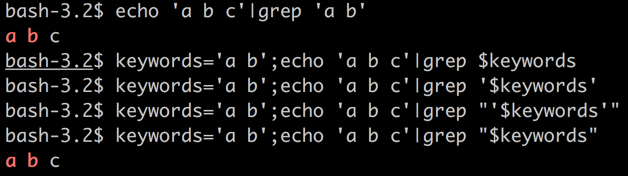

前者如果$a为空,则 $1得到的将是$b的值,出现参数错位的情况;后者则不会出现这种情况
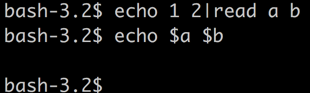
a b 变量没有被成功赋值;
原因: 由于管道的存在,默认情况下,第一个管道的前面部分是在当前bash进程中执行的,后面的被管道隔开的命令都是在单独的子shell中执行的,那么是bash的内置命令(如:read)也要单启动一个bash进程来执行,而子进程中的变量不会对父进程产生影响,显然,例子中read a b里面的a b是子进程中的变量,在父进程中是不能echo出来的。
据说bash提供了一个选项lastpipe,可以改变bash的行为,使得管道链中的最后一个命令在当前bash中执行,其他的命令都在子shell中执行,不过我的bash目前是4.1(目前最新是4.4,还没stable),还没有这个选项,通过shopt查询是否有该选项。不过,据说使用该选项将不得不禁用作业控制。
还有其他办法:
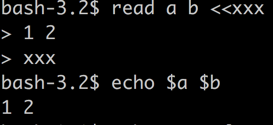
办法1: 使用Here Document
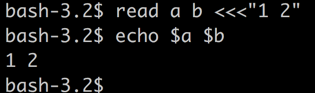
办法二: 使用Here String
办法三: 使用Here Command

这个似乎应该叫做Process Substitution
参考: http://www.tldp.org/LDP/abs/html/process-sub.html
搜索: https://www.google.com.hk/?gws_rd=cr,ssl#safe=strict&q=bash+read+pipe+into+variable
here文档和here字符串不同于其他语言中仅仅用来定义复杂的字符串的,而是有特殊目的的,bash中的here文档和here字符串是用在命令后面的,他自动修改了命令的标准输入,如:
错误用法:
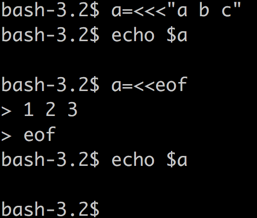
我们发现 变量a没有被成功复制。

hello world也没有成功被打印出来。
正确的用法:
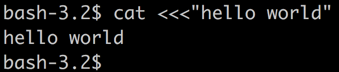
等效于:
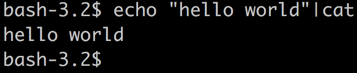
《Advanced Bash-Scripting Guide》中是这么说的:
A here document is a special-purpose code block. It uses a form of I/O redirection to feed a command list to an interactive program or a command, such as ftp, cat, or the ex text editor.
参考资料: http://www.tldp.org/LDP/abs/html/here-docs.html
没有找见这方面的文档
对于 echo “$a” 大可不必担心 $a 有函数 双引号而在替换后破坏结构;如果a='”123′ , 则不必担心echo “$a” 会被处理成 echo “”123”
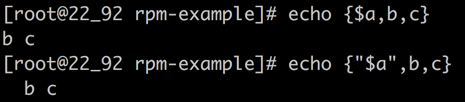
关于花括号扩展
花括号与元素之间不能有空格,元素之间逗号分隔且不能有空格

如果花括号中的元素含有变量,而变量中含有空格是没有问题的,但是空格元素可能会被丢掉,所以,为了不发生意外,变量最好用双引号引起来
参考: http://c.biancheng.net/cpp/view/2739.html
https://www.gnu.org/software/bash/manual/html_node/Shell-Parameter-Expansion.html
1. 取长度
|
1 2 3 4 |
str="abcd" expr length $str # 4 echo ${#str} # 4 expr "$str" : ".*" # 4 |
2. 查找子串的位置
|
1 2 3 4 5 |
str="abc" expr index $str "a" # 1 expr index $str "b" # 2 expr index $str "x" # 0 expr index $str "" # 0 |
3. 选取子串
|
1 2 3 4 5 6 7 8 9 |
str="abcdef" expr substr "$str" 1 3 # 从第一个位置开始取3个字符, abc expr substr "$str" 2 5 # 从第二个位置开始取5个字符, bcdef expr substr "$str" 4 5 # 从第四个位置开始取5个字符, def echo ${str:2} # 从第二个位置开始提取字符串, bcdef echo ${str:2:3} # 从第二个位置开始提取3个字符, bcd echo ${str:(-6):5} # 从倒数第二个位置向左提取字符串, abcde echo ${str:(-4):3} # 从倒数第二个位置向左提取6个字符, cde |
4. 截取子串
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
str="abbc,def,ghi,abcjkl" echo ${str#a*c} # 输出,def,ghi,abcjkl 一个井号(#) 表示从左边截取掉最短的匹配 (这里把abbc字串去掉) echo ${str##a*c} # 输出jkl, 两个井号(##) 表示从左边截取掉最长的匹配 (这里把abbc,def,ghi,abc字串去掉) echo ${str#"a*c"} # 输出abbc,def,ghi,abcjkl 因为str中没有"a*c"子串 echo ${str##"a*c"} # 输出abbc,def,ghi,abcjkl 同理 echo ${str#*a*c*} # 空 echo ${str##*a*c*} # 空 echo ${str#d*f) # 输出abbc,def,ghi,abcjkl, echo ${str#*d*f} # 输出,ghi,abcjkl echo ${str%a*l} # abbc,def,ghi 一个百分号(%)表示从右边截取最短的匹配 echo ${str%%b*l} # a 两个百分号表示(%%)表示从右边截取最长的匹配 echo ${str%a*c} # abbc,def,ghi,abcjkl |
可以这样记忆, 井号(#)通常用于表示一个数字,它是放在前面的;百分号(%)卸载数字的后面; 或者这样记忆,在键盘布局中,井号(#)总是位于百分号(%)的左边(即前面) 🙂
(#用于卸掉前面部分,%用于卸掉后面部分; 出现一次是最短匹配,出现两次是最长匹配)
5. 字符串替换
|
1 2 3 4 5 6 |
str="apple, tree, apple tree" echo ${str/apple/APPLE} # 替换第一次出现的apple echo ${str//apple/APPLE} # 替换所有apple echo ${str/#apple/APPLE} # 如果字符串str以apple开头,则用APPLE替换它 echo ${str/%apple/APPLE} # 如果字符串str以apple结尾,则用APPLE替换它 |
# 用于前缀替换
%用于后缀替换
6. 比较
|
1 2 3 4 |
[[ "a.txt" == a* ]] # 逻辑真 (pattern matching) [[ "a.txt" =~ .*\.txt ]] # 逻辑真 (regex matching) [[ "abc" == "abc" ]] # 逻辑真 (string comparision) [[ "11" < "2" ]] # 逻辑真 (string comparision), 按ascii值比较 |
7. 连接
|
1 2 3 |
s1="hello" s2="world" echo ${s1}${s2} # 当然这样写 $s1$s2 也行,但最好加上大括号 |
转自: http://www.cnblogs.com/frydsh/p/3261012.html
keyword:
bash,字符串,操作
很多命令都会提供一个bash-complete的脚本,在执行该命令时,敲tab可以自动补全参数,会极大提高生产效率。docker亦如此,如:yum install docker后,会有一个文件: /usr/share/bash-completion/completions/docker ; 显然,该脚本是用于bash自动补全的,但是,不幸的是,直接 source 执行该脚本后,docker命令后敲tab,有如下错误:

难道docker的bash自动补全还能有问题?
放狗一搜,解决办法如下:
我这里虽然安装了bash-completion ,但是没有执行其中的一个文件:
|
1 |
/usr/share/bash-completion/bash_completion |
该文件中有上面缺少的命令,自然,执行该文件就解决了。
其实 bash_completion 包中已经包含了一堆常用命令的bash自动补全的脚本的:
bash补全脚本编写:(实例)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#!/bin/bash #该脚本执行后,输入alissh 空格后敲tab键就可以提示阿里ecs的名字 #ips 命令可以输出阿里ecs的: 名字 ip 说明 #alissh complete complete -F alissh_complete alissh function alissh_complete() { cur="${COMP_WORDS[COMP_CWORD]}" opts=$(ips|awk '{print $1}') COMPREPLY=($(compgen -W "$opts" -- {cur})) } function alissh() { name=$1 ip=$(ips|grep "$1" |awk '{print $2}') ssh $ip } |
complete -F func cmd 其中func的规则:
func可以接受到3个参数:
$0: 就是bash
$1: 命令名
$2: 需要补全的单词的一部分
$3: 上一个完整的单词 , 如果当前要补全的是第一个参数,则上一个完整的单词就是命令名
使用命令(任何语言)来实现命令补全(不过还是shell方便,实在不会shell就选择其他语言):
通过命令 mycomplete 给命令phpor来补全:
|
1 |
complete -C mycomplete phpor |
其中: mycomplete 命令将接到三个参数:
$1: 命令名(就是phpor)
$2: 需要补全的单词
$3: 命令行中出现的最后一个完整的单词
mycomplete要做的事情就是根据最后一个完整的单词来推测下个(要补全的)单词;只是如果命令行中已经包含了超过3个单词,则第二个单词信息将得不到; 其实不是的,只是从命令行参数中得不到,从环境变量是可以得到的,环境变量 COMP_LINE 保存了整个命令行的内容,命令行参数只是有助于我们定位光标的位置。
complete -C 和 -F 的说明
-C 指定一个命令; -F 指定一个函数 。 那么, -C 指定一个函数能行吗? -F 指定函数一定能行吗?
其实:
可以通过是strace -e file bash 来了解bash自动补全的逻辑,可以通过函数命令complete来设置自动补全函数,如果不存在自动补全函数的话,会自动在补全目录下搜索当前执行的命令为名称的文件,如 ~/.local/share/bash-completion/completions/byssh ,我们可以在这里添加自动补全逻辑
complete 的更多用法参考: man bash 搜索: Programmable Completion
如果我们需要补全一些常规得到东西,可以使用 -A ,如:
参考资料:
且看下docker info:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
Containers: 43 Images: 57 Server Version: 1.9.1 Storage Driver: devicemapper Pool Name: docker-8:5-12884902107-pool Pool Blocksize: 65.54 kB Base Device Size: 107.4 GB Backing Filesystem: Data file: /dev/loop0 Metadata file: /dev/loop1 Data Space Used: 107.4 GB Data Space Total: 107.4 GB Data Space Available: 0 B Metadata Space Used: 70.27 MB Metadata Space Total: 2.147 GB Metadata Space Available: 2.077 GB Udev Sync Supported: true Deferred Removal Enabled: false Deferred Deletion Enabled: false Deferred Deleted Device Count: 0 Data loop file: /data1/docker/devicemapper/devicemapper/data Metadata loop file: /data1/docker/devicemapper/devicemapper/metadata Library Version: 1.02.107-RHEL7 (2015-12-01) Execution Driver: native-0.2 Logging Driver: json-file Kernel Version: 3.10.0-327.13.1.el7.x86_64 Operating System: CentOS Linux 7 (Core) CPUs: 32 Total Memory: 94.15 GiB Name: 158-5.i.bbtfax.com ID: TFQT:NSMK:UZP5:3ZMA:QLXD:O6JI:UENZ:PVE2:NR2S:5XIN:U3OB:6673 WARNING: bridge-nf-call-iptables is disabled WARNING: bridge-nf-call-ip6tables is disabled |
metadata一般不会太大,暂且不论。

问题:
一个docker存储空间被占满了:
关于loop-lvm 和 direct-lvm:
docker存储空间扩容(不丢数据): https://docs.docker.com/engine/userguide/storagedriver/device-mapper-driver/
docker在线扩容脚本: http://phpor.net/blog/post/3624
扩容不要等到一点儿空间也没有的时候才做,否则后果有二:
话说有一个叫做影梭的app,可以基于shadowsocks(一下简称ss)在本地启动一个vpn,vpn流量走的是ss,相当安全;既然ss可以翻墙,也同样可以翻到内网;那么,ss能替代vpn吗?
下面讨论ss与vpn的一些区别:
从来没想到过,存储故障能导致系统必须重启才能解决问题,尤其是,必须断电重启,reboot都不好使。
为什么呢?
存储故障导致进程因处于等待资源状态而处于D状态,该状态无法响应任何信号,即使 -9 信号也不好使。此种场景一般来讲dmesg能看到错误信息,如下图所示:
默认当等待资源超过120s时,内核会打印错误如下错误信息。

具体可能出现很多表现,如: top 、ps、ls 等卡死; 甚至访问/proc目录下的东西(如: /proc/xxx/cmdline ) 都能卡死,原以为/proc 下的东西都在内存中,其实完全不是,/proc 根本就是个接口
还有比reboot -f都需要等待更悲催的吗?

参考文章:
我们知道,linux会将文件尽可能的cache到内存里面,系统运行一段时间后,我们发现内存几乎被用完了,其实大部分是cache;而且,说实在的,真的没有必要去清理这个cache,内存真的不够用的时候,这些cache会自动释放的。
你们我们这人就是洁癖,就想把这些cache从内存中请出去,该用哪个命令呢?
我没有找到使用哪个命令,但是dd和rm可以做到:
通过drop_cache 实现:
|
1 |
echo 3 > /proc/sys/vm/drop_caches |
情景
出于某种目的,docker容器挂在了外部的文件,而且期望当外部文件发生变化的时候,docker容器对应的文件也发生变化。
难道本来不是这样的吗?是也不是:
是: echo “append info” >>/the/file 立即反应到docker容器内部了
不是: 通过vim编辑,添加一行,docker容器内部文件没有变化
分析: 应该是echo和vim有不同
当不知道的时候,结果就是: 有时候可以,有时候不可以,恶心不恶心?
放狗搜索,这里说的详细: https://github.com/docker/docker/issues/15793
总结一下:
只要想办法确保inode不变即可,如: 编辑文件的时候,先copy走,编辑完再cat 到原文件中。
什么? 你使用vim修改挂载的文件之后,docker容器中的文件立刻就变化了?
先确认下该文件的inode是否变化了(我不想去证明vim修改文件肯定会导致inode发生变化)
如果容器内挂载了宿主机目录/home/phpor/test 到容器内部 /test , 现在创建目录 /home/phpor/test/taoyi ;然后在另一个终端容器进入容器/test/taoyi 目录, 这时候,如果宿主机上mv /home/phpor/test/taoyi /home/phpor/taoyi , 然后 创建文件 /home/phpor/taoyi/file ; 这时候,在另一个终端下对于原本已经进入 /test/taoyi 的回话将可以看到file文件
fpm不区分虚拟主机,但是支持pool,每个pool listen不同的端口,每个pool有自己的配置
可以记录accesslog、slowlog
log可以记录到syslog,可以指定facility、ident、日志级别