#ifdef LINUX_OOM_ADJUST
/*
* The magic "don't kill me" values, old and new, as documented in eg:
* http://lxr.linux.no/#linux+v2.6.32/Documentation/filesystems/proc.txt
* http://lxr.linux.no/#linux+v2.6.36/Documentation/filesystems/proc.txt
*/
static int oom_adj_save = INT_MIN;
static char *oom_adj_path = NULL;
struct {
char *path;
int value;
} oom_adjust[] = {
{"/proc/self/oom_score_adj", -1000}, /* kernels >= 2.6.36 */
{"/proc/self/oom_adj", -17}, /* kernels <= 2.6.35 */
{NULL, 0},
};
/*
* Tell the kernel's out-of-memory killer to avoid sshd.
* Returns the previous oom_adj value or zero.
*/
void
oom_adjust_setup(void)
{
int i, value;
FILE *fp;
debug3("%s", __func__);
for (i = 0; oom_adjust[i].path != NULL; i++) {
oom_adj_path = oom_adjust[i].path;
value = oom_adjust[i].value;
if ((fp = fopen(oom_adj_path, "r+")) != NULL) {
if (fscanf(fp, "%d", &oom_adj_save) != 1)
verbose("error reading %s: %s", oom_adj_path,
strerror(errno));
else {
rewind(fp);
if (fprintf(fp, "%d\n", value) <= 0)
verbose("error writing %s: %s",
oom_adj_path, strerror(errno));
else
debug("Set %s from %d to %d",
oom_adj_path, oom_adj_save, value);
}
fclose(fp);
return;
}
}
oom_adj_path = NULL;
}
/* Restore the saved OOM adjustment */
void
oom_adjust_restore(void)
{
FILE *fp;
debug3("%s", __func__);
if (oom_adj_save == INT_MIN || oom_adj_path == NULL ||
(fp = fopen(oom_adj_path, "w")) == NULL)
return;
if (fprintf(fp, "%d\n", oom_adj_save) <= 0)
verbose("error writing %s: %s", oom_adj_path, strerror(errno));
else
debug("Set %s to %d", oom_adj_path, oom_adj_save);
fclose(fp);
return;
}
#endif /* LINUX_OOM_ADJUST */
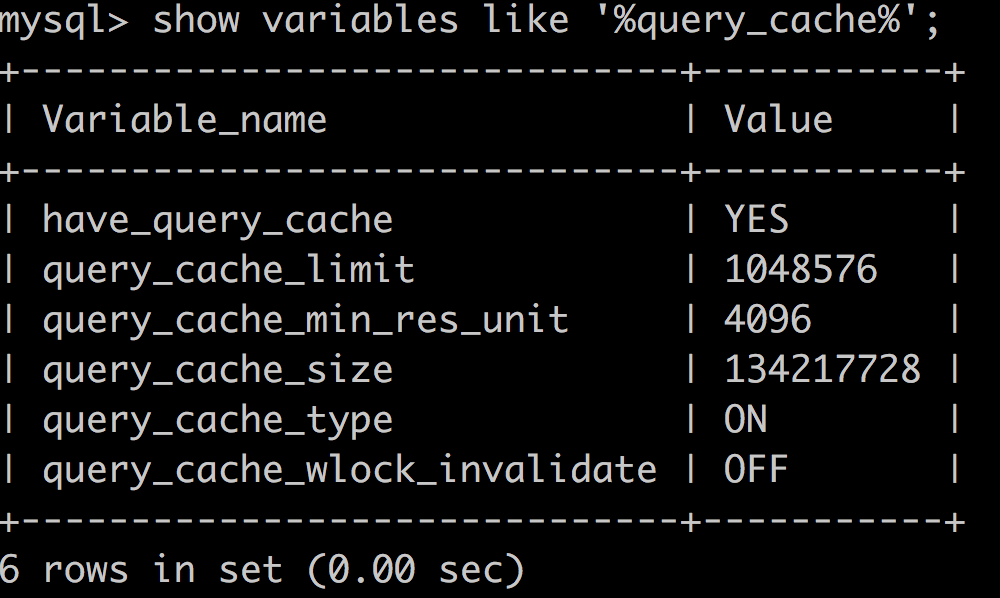
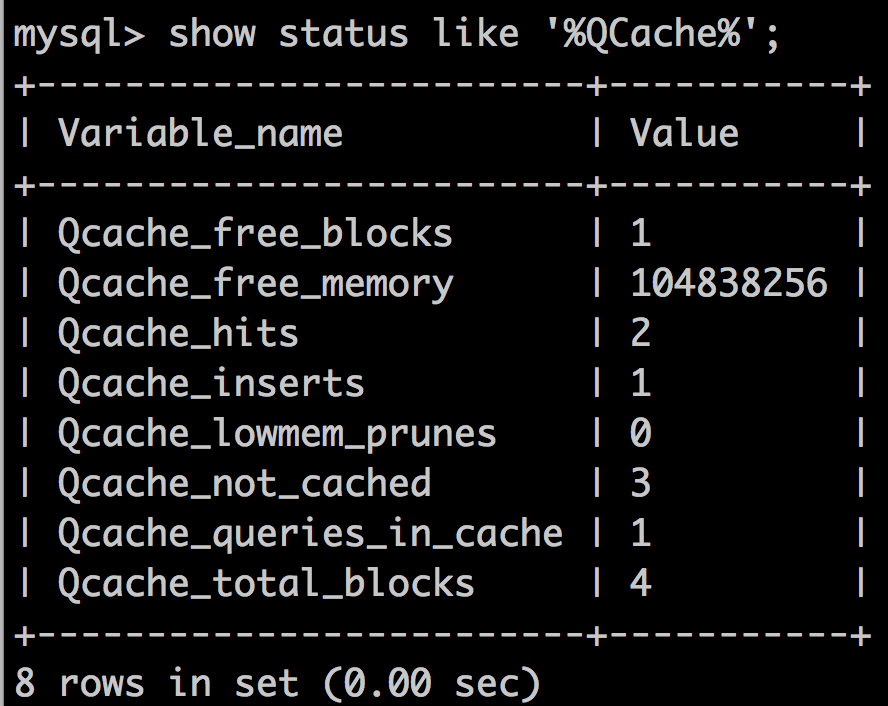




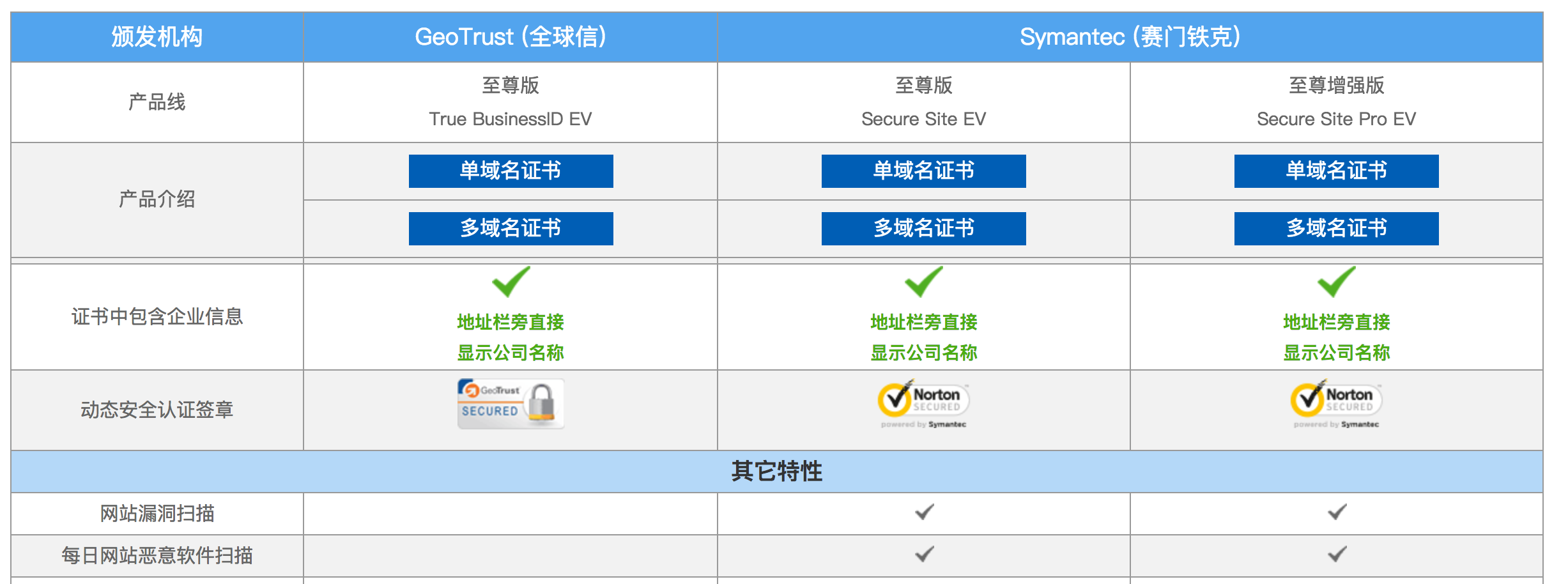
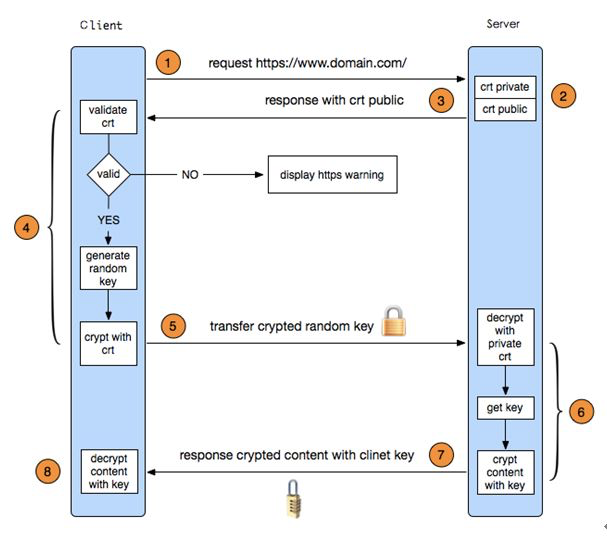
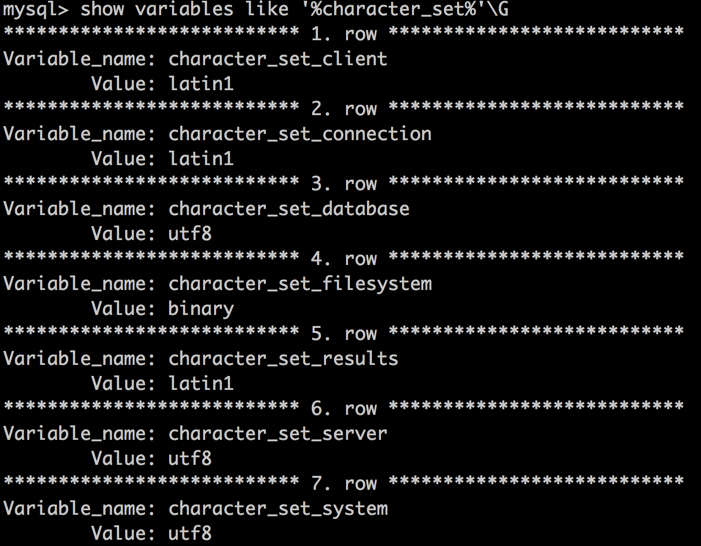 mysql 命令查询的结果显示都是“问号”,解决办法:
mysql 命令查询的结果显示都是“问号”,解决办法: