rancher集群初始状态:
1个 master + etcd +worker
1个worker
kube-apiserver进程为:
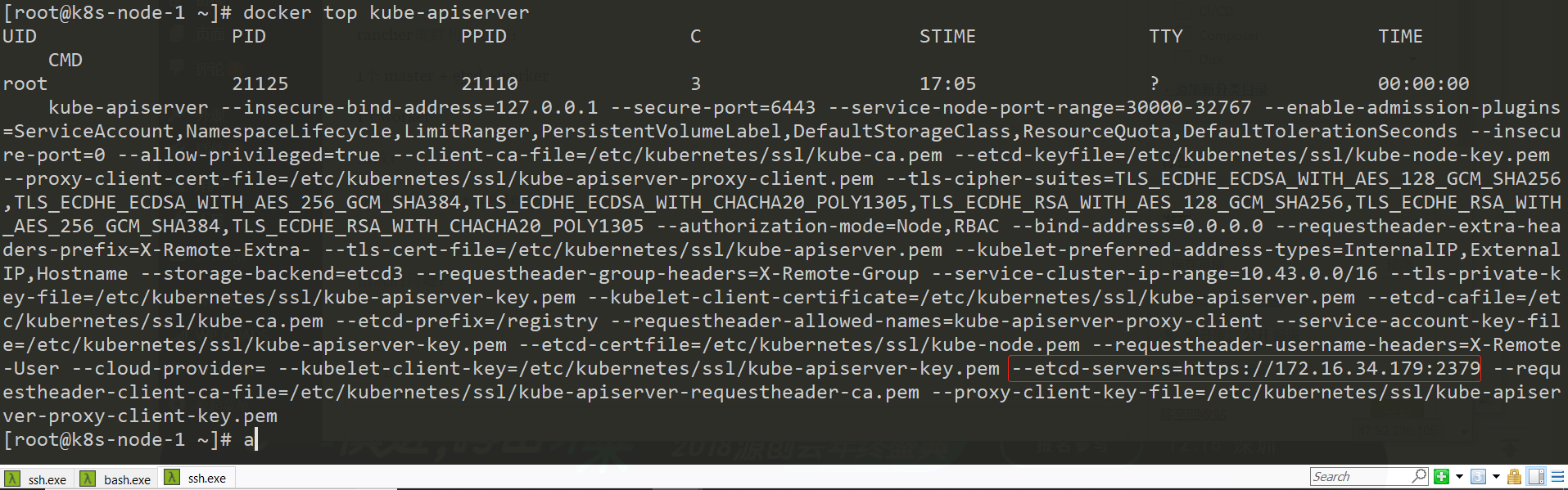
etcd进程为:

修改:
添加一个 etcd + master,上面的进程为:
kube-apiserver:
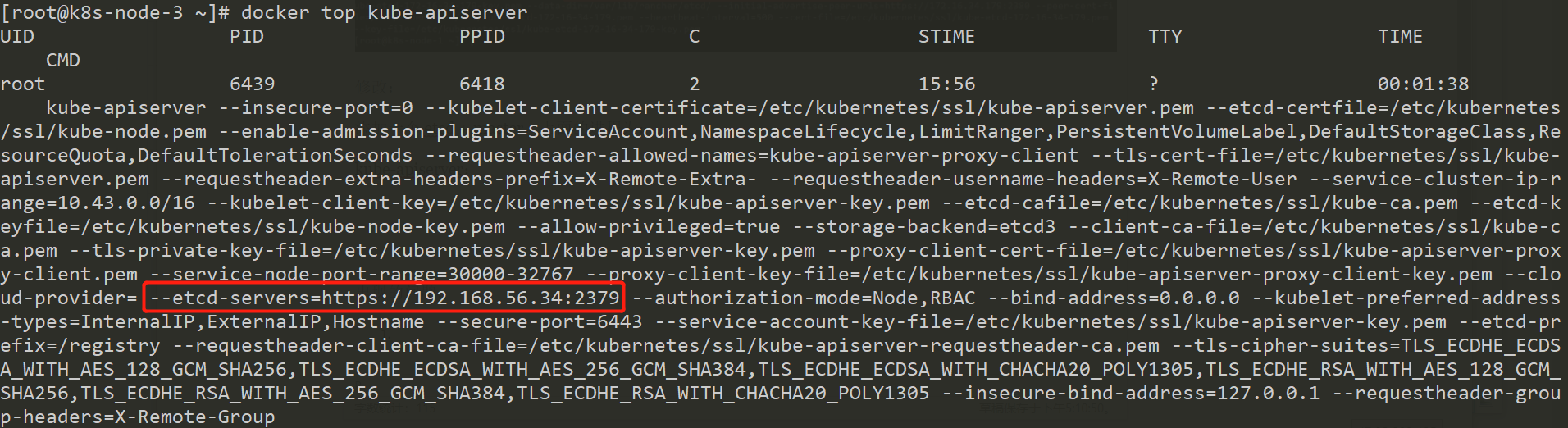
etcd进程:

出现的问题:
- 原有的etcd进程要将新的etcd添加到集群中,但是,报错为:
12018-11-27 08:44:26.674238 E | rafthttp: request cluster ID mismatch (got 3ab081c7572f57ca want e264d9f06628a989) - 由于添加出错,原有的etcd就不断尝试添加,但是该过程中2379的端口是不listen的,由于etcd出现问题,原有的kube-apiserver也就没法正常工作,所以,就算想删除新加的节点也是无计可施;
- 如何让etcd放弃添加新节点呢?
这个问题的重要原因在于etcd节点从单节点扩展到双节点,两个节点是最不好的集群,其中一个出问题,另一个没法说了算
rancher 2 etcd节点扩展为3 etcd节点:
- 新etcd节点由于也属于集群节点,所以,需要部署 kubelet、kube-proxy、flannel,非master节点还需要部署nginx-proxy
- 新etcd节点上etcd的启动参数都没有问题,但是,还是报cluster ID mismatch,不过,容器中执行:
1rm -fr /var/lib/rancher/etcd/member/
后,重启容器就OK了
总之,没有顺利扩展出来etcd节点过 - 虽然我们可以不使用rancher的办法扩展etcd节点,但是,由于rancher自动维护etcd节点添加到kube-apiserver的命令行参数里面,所以,自己手动扩展的etcd并不会被用上
- 3个etcd节点停掉一个的时候,etcdctl member list 看不到节点停掉的状态
思考:
- etcd新节点启动的时候应该 –initial-cluster-state=existing 才对吧? 否则,它怎么能知道自己需要加入到别的集群呢?
- 由于etcd新节点设置了 –initial-cluster-state=new ,而且初始的集群成员只有自己:
1--initial-cluster=etcd-k8s-node-3=https://192.168.56.34:2380
所以,理所当然地启动起来就可以工作了,自己就是一个全新的集群了 - 由于新节点上kube-apiserver配置的etcd后端就是etcd新节点,所以,kube-apiserver 也不知道自己是需要维护原有集群,而不是新建集群的,所以就直接访问新的etcd开始初始化一个新的集群了
- 所以,rancher这里实现的是不是有问题?