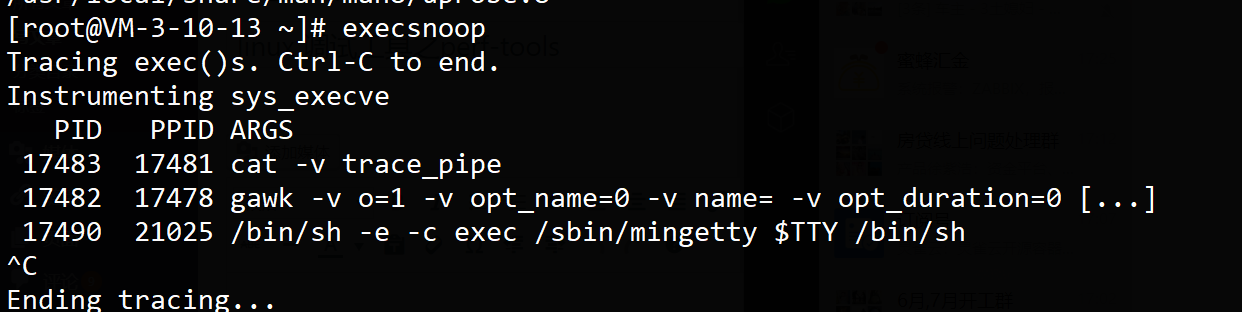
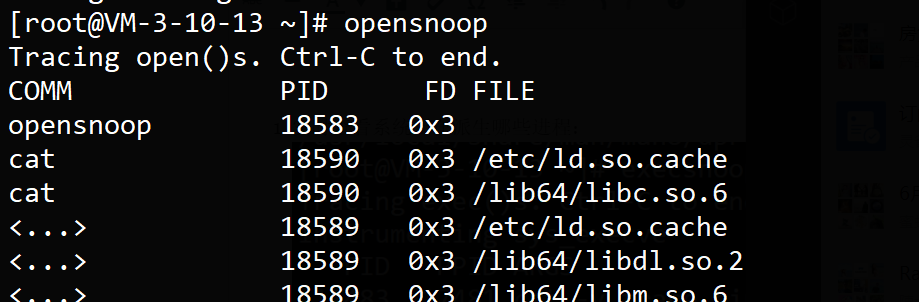
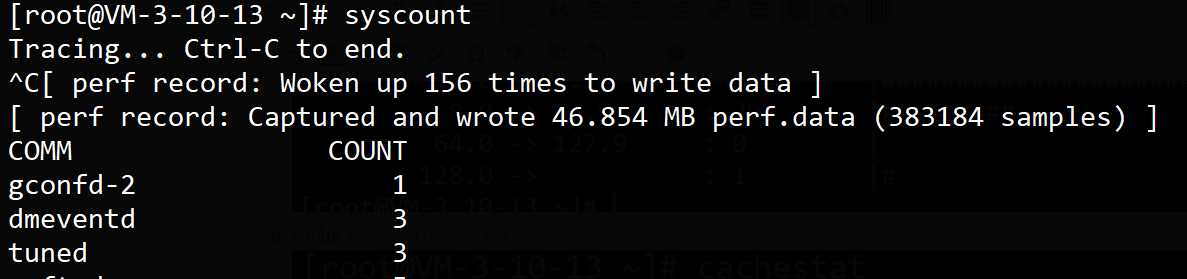
http://developer.51cto.com/art/201902/591639.htm
部署一个sourcegraph来在线阅读代码可能是一个不错的体验
DevOps
http://developer.51cto.com/art/201902/591639.htm
部署一个sourcegraph来在线阅读代码可能是一个不错的体验
关于容器中已经没有了进程,但是容器还是杀不死的情况:
用bash作为初始进程启动了一个容器:
|
1 |
docker run -it --rm redis:5.0.5 bash |
然后,在bash中cat了一个二进制文件:
|
1 |
cat /usr/local/bin/gosu |
如此,bash卡死,不能操作了,可能是因为转码没有处理好导致的。
docker top时已经看不到容器中存在任何进程了,但是docker run进程依然存在

docker stop操作也不能停掉容器。
原因在于:

就是说,docker run进程向/dev/pts/0 write的时候,阻塞住了,这就和pts有关了
解决办法,kill -9 22784
https://blog.csdn.net/xj80231314/article/details/88689898
看的想吐的redis集群
php中参考的conf.d 目录是在编译时指定的,不能在运行时修改,如果非要修改,也不是不行,可以直接用sed来修改php这个二进制文件:
|
1 |
sed 's/conf\.d/conf.e/' /usr/bin/php >/tmp/php |
如果是签名或者有摘要校验的二进制文件如phar文件,则不能直接使用sed修改
由于学习swoole的时候,需要使用swoole扩展,但是偶尔又想单步调试一些逻辑,不得不使用xdebug扩展,但是swoole扩展和xdebug扩展势不两立,有不能通过参数来切换是否使用xdebug,于是通过此法搞了两个php二进制文件,二者使用不同的conf.d 目录,就可以单独配置扩展了。
但是phpstorm中单个项目不能同时使用两个php解释器,只好在使用时临时切换php解释器了
A进程总是连接B进程listen的1158端口,而且连接到断开的持续时间很短,由于知道1158端口,所以,B进程很容易被找到,现在不知道A进程是哪个,只知道是本机的某进程来连接1158端口的。
如何找到A进程呢?
对于持续时间不太短的连接,我们通常可以使用ss -anp来查看,但是对于持续时间足够短的连接,ss是不太容易抓到的。毕竟,当机器上进程数多的时候,每个连接都扫一遍所有的进程下的fd,会明显感觉很慢的。
所以,一种办法是:
不使用ss的-p选项,只使用ss -an,从结果中拿到感兴趣的端口后,再去/proc/*/fd/* 中找对应的fd,但是,进程的fd中对应的socket的id并不出现在ss的结果中,无法对应起来。
另一种办法:
直接去 /proc/net/tcp 中查找感兴趣的连接,基本逻辑如下:
|
1 2 3 4 5 6 7 8 9 |
while : ; do cat /proc/net/tcp |grep ":0486"|awk '$10 != 23774779 {print $10}' done | while read key;do echo $key; for fd in /proc/*/fd/*; do v=$(readlink $fd) [[ $v = socket*$key* ]] && { echo $fd $v ; } done done |
其中的 :0486 是我们感兴趣的端口号的16进制表示, 23774779 是我们不感兴趣的连接
其实,这样也未必能抓到感兴趣的连接,毕竟连接消失的太快。
比较靠谱的办法是:
|
1 |
kill -19 $pid_of_B |
让B进程休眠,这样,A进程进入的连接不能被及时处理,就不会立即断开,然后使用ss -anp就可以了,除非A进程设置了非常短的超时,那么,可能我们就需要研究一下systemtap了
https://docs.zephir-lang.com/0.12/en/motivation
zephir是为开发PHP扩展而发明的一门语言,而且只能用来开发PHP扩展,通常,PHP的扩展都是编译运行的,但是zephir却是把自己编译成字节码给zend解释执行的,但是他也能进一步编译成机器语言
Zephir was not created to replace PHP or C. Instead, we think it is a complement to them, allowing PHP developers to venture into code compilation and static typing. Zephir is an attempt to join good things from the C and PHP worlds, looking for opportunities to make applications faster.
只能写带名字空间的class
Code in Zephir must be placed in classes. The language is intended to create object-oriented libraries/frameworks, so code outside of a class is not allowed. Additionally, a namespace is required:
他可以直接调用PHP语言定义的函数
必须写注释:
In most languages, comments are simply text ignored by the compiler/interpreter. In Zephir, multi-line comments are also used as docblocks, and they’re exported to the generated code, so they’re part of the language!
If a docblock is not located where it is expected, the compiler will throw an exception.
zephir相当于是跑在zend上的另一门语言
办法1: 不知道
办法2:
把现有的db2 connect to 。。,db2 connect reset等用bash的function包装一下,在包装函数里面添加逻辑,不直接db2使用原生的方法