- db2look导出的文件的字符集受两个配置的影响
- LANG
- 影响文件的表头
- 建议设置LANG=C,使得文件的头部和编码无关,不至于影响某些编辑器(如vim)对文件编码的检测
- DB2CODEPAGE
- 影响文件的内容
- 通过db2set进行设置,该设置是全局的,参考: https://phpor.net/blog/post/12804
- LANG
- db2look 默认不导出创建数据库的语句,也不导出表存在就删除的drop语句,可以通过选项开启:
- -createdb: 生成创建数据库的语句
- -dp: Generate DROP statement before CREATE statement
- -printdbcfg: Generate UPDATE DB CFG commands for the database configuration parameters
- 如果目标数据库和源数据库配置期望一样的话,这样会比较方便
AIX命令
查看单个用户最大进程数量:
|
1 |
lsattr -El sys0|grep maxuproc |
修改单个用户最大进程数量:
|
1 |
chdev -l sys0 -a maxuproc=256 |
DB2 创建实例
首先,在安装目录find db2icrt;
db2icrt 需要指定db2fenc账号和实例账号,而且,这些账号不会自动创建,需要事先创建:
|
1 2 |
useradd db2inst3 -g 102 passwd db2inst3 #修改密码 |
创建实例: (命令是在/opt/ibm/db2/V11.1/instance 下面的,默认没有在path目录中)
|
1 |
./db2icrt -u db2inst3 db2inst3 |
db2 create 的数据库默认在db2实例账户的家目录下的。
|
1 |
/home/db2inst3/db2inst3 |
启动实例:
|
1 2 3 |
su - db2inst3 db2start |
db2 实例名也不能多于8个字符(直到db2 11 中依然如此),哎
创建实例的时候,会自动往 /etc/services 中注册一个条目, 如: (不知道这个是如何选择到50001端口的,这是是因为另一个实例已经占用了 50000端口)
db2c_db2ist11 50001/tcp
创建实例时并不立即生成实例相关目录,只是在实例用户的目录中生成了sqllib目录,甚至在db2start后,都并不产生数据库的目录的。
DB2 和 Docker 的恩怨
DB2 11.5 的容器镜像,启动的时候,自动创建了数据库TESTDB, 但是没有自动启动DB2 manager,进入db2inst1账号后,由于db2admin没有在PATH里面,db2start会失败,所以,将路径 /opt/ibm/db2/V11.5/das/bin 假如到PATH 后,db2start可以正常启动,但是,db2 connect to testdb 时,就会报错,然后db2 manager进程就退出了。
然而,也找不到哪里有有用的错误日志。
db2 manager启动的时候,数据库本身并没有启动,可以激活数据库,也可以第一次connect to 数据库的时候自动激活,目前的情况就是第一次连接的时候失败,应该就是因为数据库启动失败
先怀疑一下:
- 可能是日志文件配置的太多、太大,磁盘不够,所以数据库启动不了
- 可能是启动数据库需要的内存不能满足需求,所以数据库启动失败
检查:
db2 get db cfg for testdb


日志文件存储需求: 1024 * 4K * (13+12) = 100MB ;
这个完全没有问题。
内存需求: 1237664 * 4K = 4.8GB ,然而,我的容器限制的是2GB的内存
修改内存需求配置:
|
1 |
db2 update db cfg for testdb using DATABASE_MEMORY 4096 |
修改后: 4096*4KB= 16MB (这个是非常小的,这里仅仅是快速测试一下是不是内存问题导致的失败,所以,随便写了一个很小的值)
再次测试,发现连接数据库正常了
总结:
- 注意修改数据库相关配置
问题:
- 默认的数据库内存大小是如何确定的?
DB2之动态sql
DB2中记录了sql的执行次数和平均时长,执行总时长以及CPU时间。
但是,这些数据是多长时间内的呢?
- 这些数据仅仅是记录在内存中的,重启数据库就没有了,也就是说,数据是从启动数据库开始的
- 鉴于内存大小的限制,动态sql也不可能保存启动数据库以来所有的sql的统计信息,那么是保存最近多长时间或多少条sql的记录吗?
- 应该都不是,仅仅和分配的内存大小有关系,查看分配的内存大小:

默认是4K的内存 - 如果空间用完后,新的sql进来的话,会如何处理呢?
- 如果新的sql已经存在在内存中,则仅仅修改已有记录的执行次数、执行时间等值就行了,不需要新的空间
- 如果是一个全新的sql,则直接丢弃?
- 如何查看动态sql内存的使用情况?
- 通常情况下,数据库中的sql类型是非常有限的,都记录下来是可能的
- 应该都不是,仅仅和分配的内存大小有关系,查看分配的内存大小:
- 动态sql的信息
- 动态sql记录的是执行次数、平均执行时间,并不记录某次的慢查询,如果偶尔又一次10s的查询,但是有1000次的查询都在1ms以内,那么,平均查询时间在10ms以内,这样的话,10s的那次慢查询是被淹没了的,如何发现10s的那次慢查询呢?
db2 中的sleep函数
db2中没有sleep函数,但是可以自定义一个sleep存储过程:
|
1 2 3 4 5 6 7 8 |
db2 "CREATE OR REPLACE PROCEDURE SLEEP(seconds INTEGER) BEGIN DECLARE end TIMESTAMP; SET end = CURRENT TIMESTAMP + seconds SECONDS; wait: LOOP IF CURRENT TIMESTAMP >= end THEN LEAVE wait; END IF; END LOOP wait; END" |
关于儿子
10.1之前被医生诊断为线状苔藓的儿子腿上的十多公分长的一片小疙瘩,说是没有特效药,也没有可靠的治疗方法,可能会变多,也可能自己就消退,不治疗也没有影响的,于是开了两管糠酸莫米松乳膏,10元一管,大约用了一周,一管没用完,已经明显消退了。
儿子最近的口头禅是:(跟图图学的)
为什么,谁说的,你怎么知道
儿子最近迷上五子棋了,因为他总是能赢,每天晚上都有和我下几局
kvm根据IP地址查找kvm(虚拟机)进程
由于IP地址不会出现在kvm进程参数中,如果kvm虚拟机的名字(或其他属性)上也不标记IP地址的话,使用者只告知IP地址的时候就不太好查找虚拟机了。
查找办法:
- 首先,根据IP地址查找到MAC地址
- 查找方法:
- 同一网段的其它机器上ping一下虚拟机的IP地址,然后,arp -an查看IP对应的MAC地址
- 查找方法:
- 然后,根据MAC地址去进程中搜索就行了
注意: 这里是机器活着到底情况下的办法,如果机器死了的时候就不能这样了,所以,最好还是把IP地址标记到某个地方
podman 入门
安装
centos官方yum源目前更新至podman-1.4.4,距离最新的1.5并不太远,所以,centos7上直接yum install -y podman就行。
启动
podman search busybox
podman pull docker.io/library/busybox
podman run -it –rm busybox
查看相关进程:
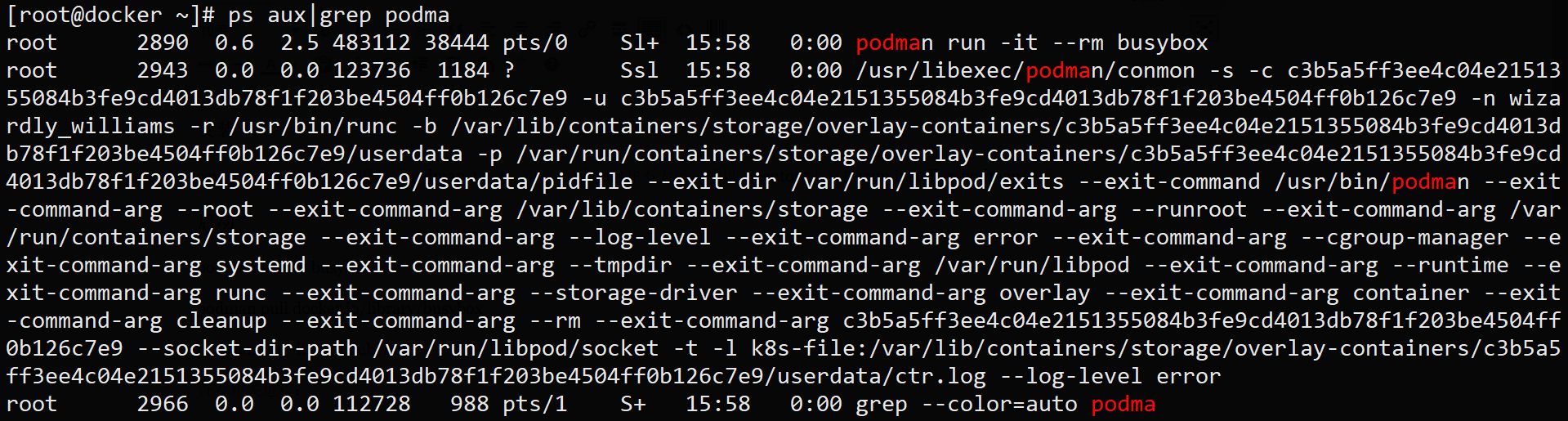
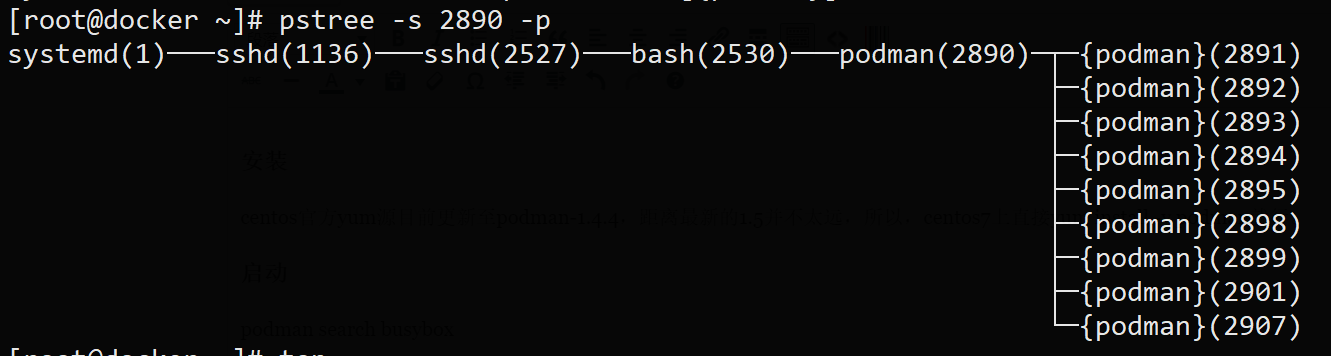

进程分析:
- podman进程并没有立即退出
- podman进程也不是容器进程(2953)的祖先进程,
- conmon(2943)进程才是容器进程的父进程
通过execsnoop了解podman的基本逻辑:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
3182 2530 podman run -it --rm busybox 3188 3187 /usr/sbin/iptables --version 3189 3187 /usr/sbin/ip6tables --version 3195 3193 /usr/libexec/cni/loopback 3200 3193 /usr/libexec/cni/bridge 3206 3200 /usr/libexec/cni/host-local 3212 3200 /usr/sbin/iptables --version 3213 3200 /usr/sbin/iptables -t nat -S --wait 3214 3200 /usr/sbin/iptables -t nat -N CNI-d286860d1f2c10088f58c4fa --wait 3215 3200 /usr/sbin/iptables -t nat -C CNI-d286860d1f2c10088f58c4fa -d 10.88.0.4/16 -j ACCEPT [...] 3216 3200 /usr/sbin/iptables -t nat -A CNI-d286860d1f2c10088f58c4fa -d 10.88.0.4/16 -j ACCEPT [...] 3217 3194 /usr/lib/systemd/systemd-sysctl --prefix=/net/ipv4/conf/vethaec894ac --prefix=/net/ipv4/neigh/vethaec894ac --prefix=/net/ipv6/conf/vethaec894ac --prefix=/net/ipv6/neigh/vethaec894ac 3218 3200 /usr/sbin/iptables -t nat -C CNI-d286860d1f2c10088f58c4fa ! -d 224.0.0.0/4 -j [...] 3219 3200 /usr/sbin/iptables -t nat -A CNI-d286860d1f2c10088f58c4fa ! -d 224.0.0.0/4 -j [...] 3220 3200 /usr/sbin/iptables -t nat -C POSTROUTING -s 10.88.0.4 -j CNI-d286860d1f2c10088f58c4fa [...] 3221 3200 /usr/sbin/iptables -t nat -A POSTROUTING -s 10.88.0.4 -j CNI-d286860d1f2c10088f58c4fa [...] 3222 3190 /usr/libexec/cni/portmap 3226 3190 /usr/sbin/iptables -t filter -S --wait 3227 3190 /usr/sbin/iptables -t filter -S --wait 3228 3190 /usr/sbin/iptables -t filter -C FORWARD -m comment --comment CNI firewall plugin rules [...] 3229 3190 /usr/sbin/iptables -t filter -C CNI-FORWARD -m comment --comment CNI firewall plugin rules [...] 3230 3190 /usr/sbin/iptables -t filter -C CNI-FORWARD -d 10.88.0.4/32 -m conntrack [...] 3231 3190 /usr/sbin/iptables -t filter -A CNI-FORWARD -d 10.88.0.4/32 -m conntrack [...] 3232 3190 /usr/sbin/iptables -t filter -C CNI-FORWARD -s 10.88.0.4/32 -j ACCEPT [...] 3233 3190 /usr/sbin/iptables -t filter -A CNI-FORWARD -s 10.88.0.4/32 -j ACCEPT [...] 3234 3191 /usr/libexec/podman/conmon -s -c 25320a1e64226351a66056671a5f0c8c382204b3ea183d69d1fce06293164f8d -u 25320a1e64226351a66056671a5f0c8c382204b3ea183d69d1fce06293164f8d -n sad_dijkstra -r [...] 3236 3235 /usr/bin/runc --systemd-cgroup 3242 3241 /usr/bin/runc init 3252 3190 /usr/bin/runc start 25320a1e64226351a66056671a5f0c8c382204b3ea183d69d1fce06293164f8d 3245 3244 sh |
- 首先,准备网络环境,通过iptables以及 containernetworking-plugins 实现
- 然后,通过conmon来借助runc启动容器进程
通过podman info 了解podman:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
[root@docker ~]# podman info host: BuildahVersion: 1.9.0 Conmon: package: podman-1.4.4-4.el7.centos.x86_64 path: /usr/libexec/podman/conmon version: 'conmon version 0.3.0, commit: unknown' Distribution: distribution: '"centos"' version: "7" MemFree: 81936384 MemTotal: 1567813632 OCIRuntime: package: runc-1.0.0-65.rc8.el7.centos.x86_64 path: /usr/bin/runc version: 'runc version spec: 1.0.1-dev' SwapFree: 3111645184 SwapTotal: 3221221376 arch: amd64 cpus: 1 hostname: docker kernel: 3.10.0-957.1.3.el7.x86_64 os: linux rootless: false uptime: 216h 45m 40.51s (Approximately 9.00 days) registries: blocked: null insecure: null search: - registry.access.redhat.com - docker.io - registry.fedoraproject.org - quay.io - registry.centos.org store: ConfigFile: /etc/containers/storage.conf ContainerStore: number: 1 GraphDriverName: overlay GraphOptions: null GraphRoot: /var/lib/containers/storage GraphStatus: Backing Filesystem: xfs Native Overlay Diff: "true" Supports d_type: "true" Using metacopy: "false" ImageStore: number: 1 RunRoot: /var/run/containers/storage VolumePath: /var/lib/containers/storage/volumes |
- 这里显示了buildah的版本号,podman和buildah是什么关系?buildah是制作镜像用的,应该是可以单独使用的,但是使用podman构建镜像的时候并没有调用buildah进程,难道编译到podman进程里面了?(事实却是如此:Podman uses Buildah’s golang API and can be installed independently from Buildah),参考:https://github.com/containers/libpod
- 虽然buidah也有run操作,也要容器的概念,但是这些和podman是不同的,buildah的run相当于dockerfile中的RUN,而容器也是一个短暂的状态
- conmon:
- registries: 允许有多个registry
- storage
- 存储驱动: overlay,docker已经默认overlay2了,podman为啥还不支持overlay2?
- 存储位置:/var/lib/containers/storage
podman远程连接
目前所有发行版并不带有该功能,通过varlink来实现的,原本只listen本地的unix socket,远程连接需要先走ssh通道,话说这个也无可厚非
Rootless
需要使用crun作为运行时,而不是runc,因为需要cgroup v2,runc不支持cgroup v2
https://github.com/containers/libpod/blob/master/docs/tutorials/rootless_tutorial.md
Skopeo
一个管理镜像仓库的工具
容器迁移
虽然可以设置一个检查点,保存到文件后,从另外一个机器上restore后,继续运行,但是,该模式从网络的角度来看,等待时间太长,或者根本就是中断的,而OpenStack中虚拟机的热迁移基本是无感知的;
测试发现,podman的checkpoint功能完成export功能都很难,尚未测试成功; 另外,如果容器中有僵尸进程,基本是export不了的
vim bash function dash
bash中的函数名中可以包含中划线(-)的,由于中划线比下划线敲起来要容易,所以我就喜欢中划线。但是一般来讲,中划线不能作为单词的一部分的,所以,关键字补全的时候就不能很好的补全。
但是,vim中可以让中划线作为关键字的字符,设置方法为:
se lisp
参考: https://superuser.com/questions/403516/exclude-dash-from-word-separators-in-vi
或vim 中查看帮助: help ‘iskeyword’