实用的脚本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#!/bin/bash DB=$1 db2 connect to $DB || exit #### 提取所有表名到变量tables # 错误的写法 tables=$(db2 -x list tables | awk '{print $1}') # 正确的写法 (这一定不是最简洁的,但是逻辑很清晰) tmp=$(db2 -x list tables) tables=$(echo "$tmp"| awk '{print $1}' ..... |
脚本基本逻辑是:
- 连接数据库
- 获取所有表的表名
- 然后做想做的事(如:导出表数据)
脚本很简单,但是,还是写出问题来了
其实,短短的代码里面藏着很多知识呢
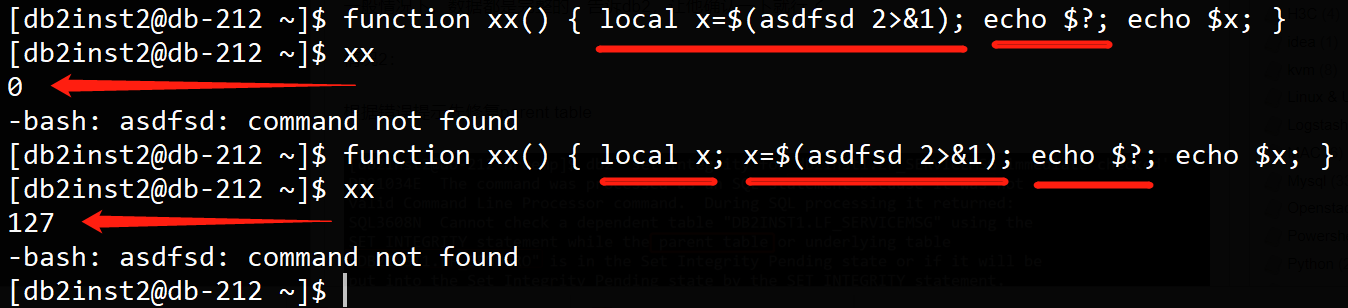
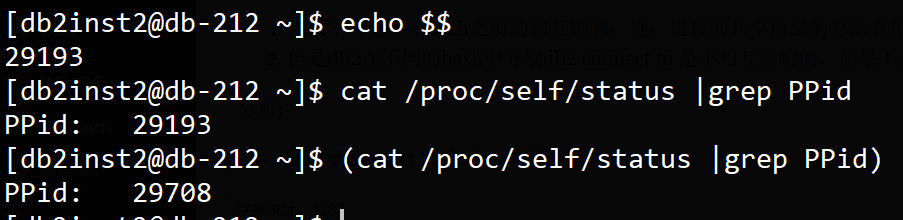
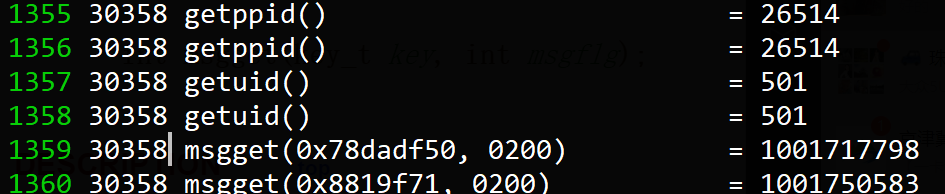
上述的错误的写法之所以错,是因为db2进程的PPid不是当前的bash,但是和正确的写法差别不大呀,为什么PPid就不一样了呢? 可以参考: https://phpor.net/blog/post/12836
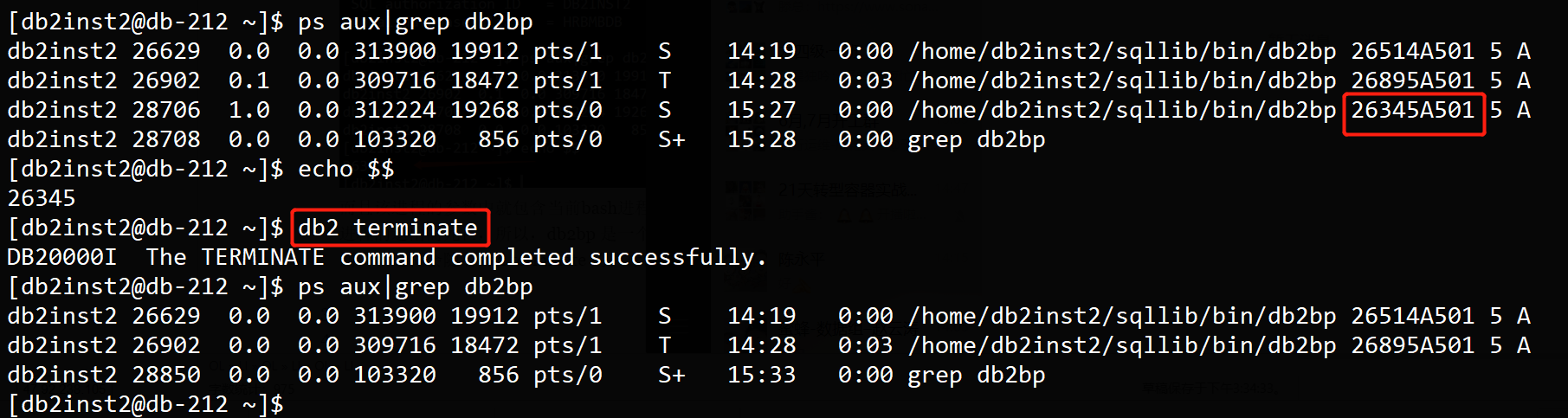
为什么db2 那么关心PPid ?可以参考:https://phpor.net/blog/post/12806
更新:
就算非常小心的去写,bash中通过函数内部使用db2命令,很容易就进入的不同的环境,所以,为了能让db2和bash很好的结合,我创造了一个db2cli,其架构就是:
bash中定义函数调用自定义的db2函数,该db2函数内部通过curl访问一个httpserver,让本次会话的db2命令都在同一个httpserver进程内部执行,httpserver地址:https://github.com/phpor/go-example/tree/master/app/db2-proxy
db2cli地址:













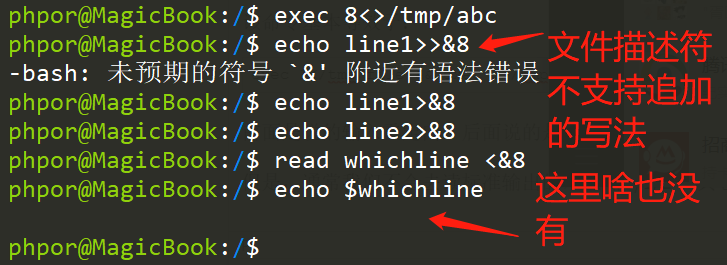
 当然,这样总是读第一行
当然,这样总是读第一行