我使用tokyotyrant的方式如下:
/data1/tokyotyrant/bin/ttserver -host 10.10.10.111 -port 6789 -dmn -pid /data1/tokyotyrant_data/6789/6789.pid -le -uas -thnum 16 -log /data1/tokyotyrant_data/6789/6789.log -ulog /data1/tokyotyrant_data/6789/6789.ulog -sid 6789 -mhost 10.10.10.112 -mport 7890 -rts /data1/tokyotyrant_data/6789/6789.rts *
两项统计数据如下:
[root@localhost ~]# tcrmgr inform -port 6789 10.10.10.111
record number: 10470754
file size: 2014949218
[root@localhost ~]# tcrmgr inform -port 6789 -st 10.10.10.111 | grep rss
memrss 3826147328
[root@localhost ~]#
疑问:
存储的数据占用的内存大小file size为2G; 但是物理内存占用为3.8G; 我承认程序本身会占用一部分内存,100MB了不得了吧,那么其余的1.7G都做什么用了呢?
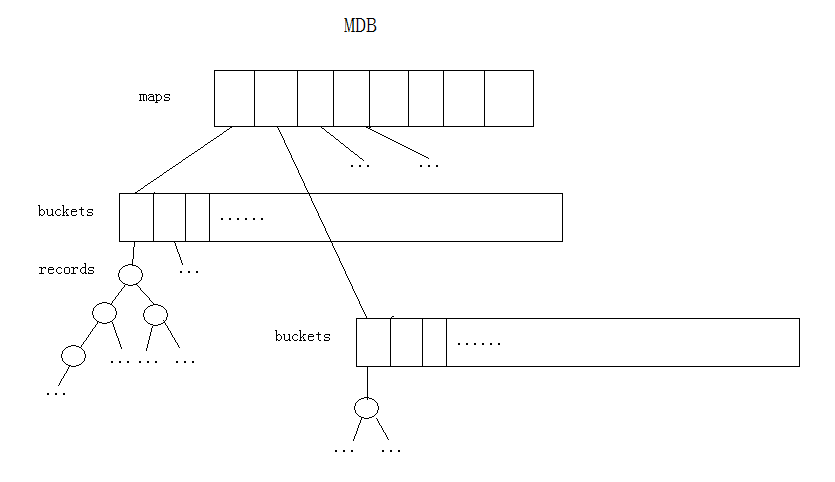
首先,通过看源码,得知,file size是通过存储的数据计算出来的,其中包括存储数据的数据结构占用的空间和key+value占用的空间。计算方式如下:
tcutil.c
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/* Get the total size of memory used in a map object. */
uint64_t tcmapmsiz(const TCMAP *map){
assert(map);
return map->msiz + map->rnum * (sizeof(*map->first) + sizeof(tcgeneric_t)) +
map->bnum * sizeof(void *);
}
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
所以,即使没有一条记录,filesize也不会是0的; 默认的bnum为65672; 如果你的机器是32位的,则,0条记录时的filesize为: 65672 * 4 = 262688; 所以,如果你执行了vanish,发现filesize不为0 ,就不用奇怪了。
什么? 在源码中没有找到 65672 ? 哦,这个数字是这么来的:
tcutil.c
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
#define TCMDBMNUM 8 // number of internal maps
#define TCMDBDEFBNUM 65536 // default bucket number
…
/* Create an on-memory hash database object. */
TCMDB *tcmdbnew(void){
return tcmdbnew2(TCMDBDEFBNUM);
}
/* Create an on-memory hash database with specifying the number of the buckets. */
TCMDB *tcmdbnew2(uint32_t bnum){
TCMDB *mdb;
if(bnum < 1) bnum = TCMDBDEFBNUM;
bnum = bnum / TCMDBMNUM + 17;
TCMALLOC(mdb, sizeof(*mdb));
TCMALLOC(mdb->mmtxs, sizeof(pthread_rwlock_t) * TCMDBMNUM);
TCMALLOC(mdb->imtx, sizeof(pthread_mutex_t));
TCMALLOC(mdb->maps, sizeof(TCMAP *) * TCMDBMNUM);
if(pthread_mutex_init(mdb->imtx, NULL) != 0) tcmyfatal("mutex error");
for(int i = 0; i < TCMDBMNUM; i++){
if(pthread_rwlock_init((pthread_rwlock_t *)mdb->mmtxs + i, NULL) != 0)
tcmyfatal("rwlock error");
mdb->maps = tcmapnew2(bnum);
}
mdb->iter = -1;
return mdb;
}
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
说明:
(65536 / 8 + 17 ) * 8 = 65672
关于tcmdb的实现基本都是在 tcutil.c 中的,难道说tcmdb原来是作为一个cache工具来实现的?
其它tcbdb tchdb都是定义在单独的文件中的,而tcmdb则是定义在 tcutil.h中的,而且tcmdb也完全是通过map来实现的。