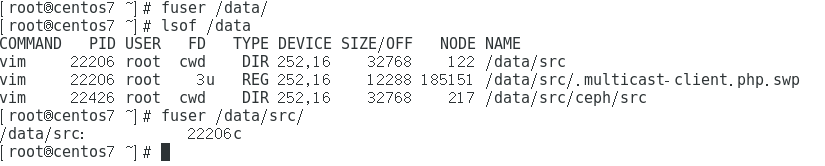
背景:
由于原来的ceph-4的系统盘没有做raid,为了更加靠谱,决定重装ceph-4; 首先,按照官方文档给出的方法,一个一个卸掉osd,然后
|
|
ceph osd purge {id} --yes-i-really-mean-it |
但是,发现crush中还是存在ceph-4,虽然没有了osd,看着很是碍眼,于是看了写help,执行
|
|
ceph osd crush unlink ceph-4 |
然后,crush中就看不到ceph-4了
后来,ceph-4重装后,执行:
|
|
ceph-deploy install ceph-4 --repo-url=http://mirrors.aliyun.com/ceph/rpm-luminous/el7/ ceph-deploy mgr create ceph-4 ceph-deploy mds create ceph-4 ceph-deploy rgw create ceph-4 ceph-deploy osd create ceph-4:/dev/vdb ceph-deploy osd create ceph-4:/dev/vdc ceph-deploy osd create ceph-4:/dev/vdd ceph-deploy osd create ceph-4:/dev/vde |
结果,ceph osd tree时,发现 ceph-4 在crush中的结构和别的host不一样,无论如何也不向这里的osd分配数据,如下:
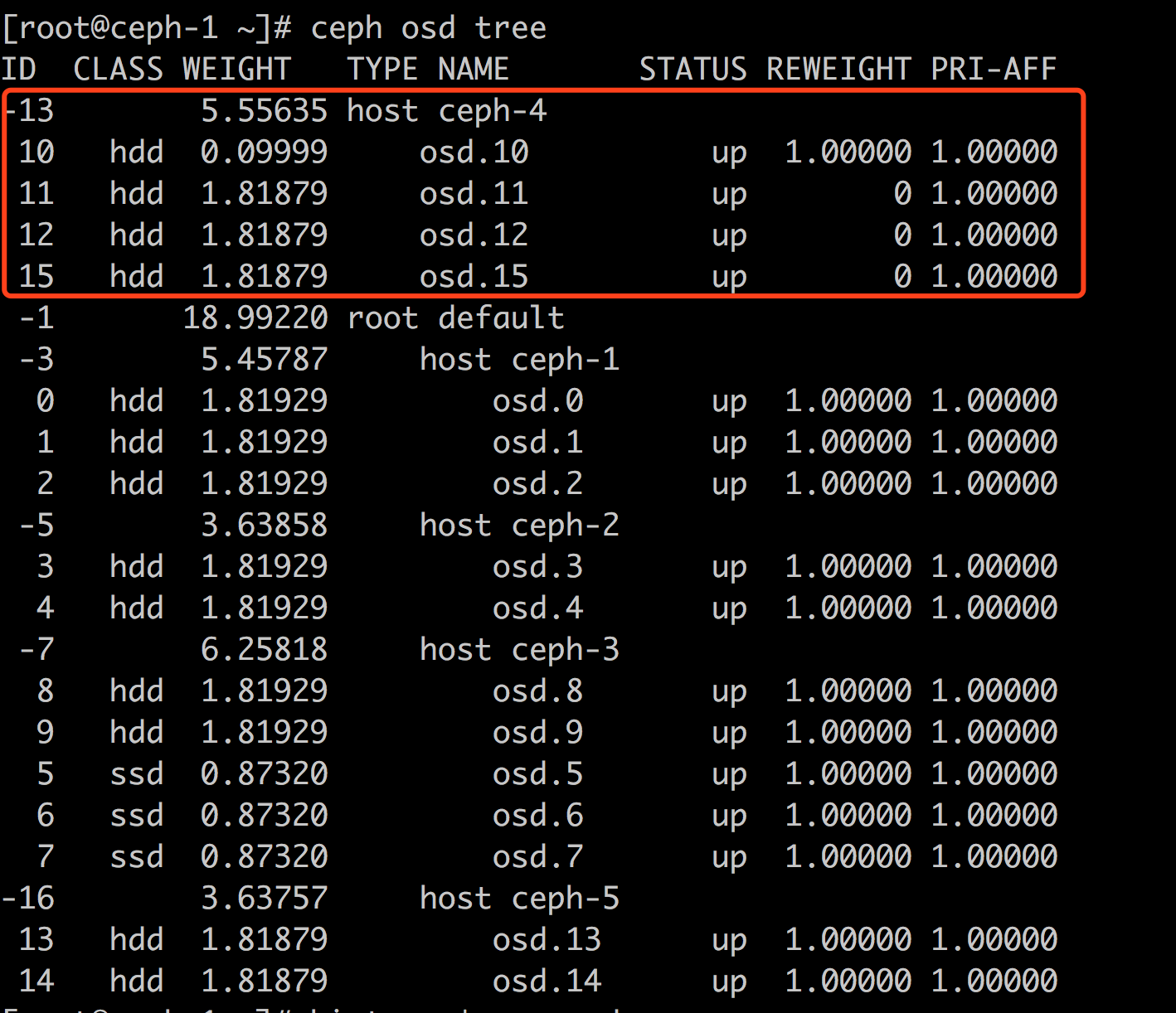
后经 Ceph中国社区2群 @孤舟 指点,他说我的pool走的都是default,ceph-4 没有在default,然而,我根本不知道是哪里的不同导致出现了这样的差异,于是@孤舟 赐我一锦囊,拆看如下:
|
|
ceph osd crush move ceph-4 root=default |
结果:

疑问:
ceph-1 ceph-2 ceph-3 ceph-4 ceph-5 我都是按照相同的命令来执行的,为什么ceph-4就例外了呢?
我能想到的ceph-4唯一的不同就是ceph-4曾经存在过,可能删除的时候没有处理利索,难道是:
|
|
ceph osd crush unlink ceph-4 |
使用的不当? 文档中还有一个
的用法,不知道二者有何差异,不过很可能是这样:
|
|
ceph osd crush remove ceph-4 |
这个remove似乎也可以移除osd的,但是purge似乎对于osd来讲更加彻底
稍后研究
问题2
- ceph osd out 的时候会rebalance一次
- ceph osd purge 的时候(也可能是ceph osd crush remove ceph-4 的时候)也会rebalance一次
- 那么,能否通过设置 ceph osd set norebalance ,避免两次rebalance呢?似乎不行,set norebalance似乎只对于osd down掉有效,而out、remove操作似乎都不参考该设置,参考: http://www.xuxiaopang.com/2016/11/11/doc-ceph-table/
问题3
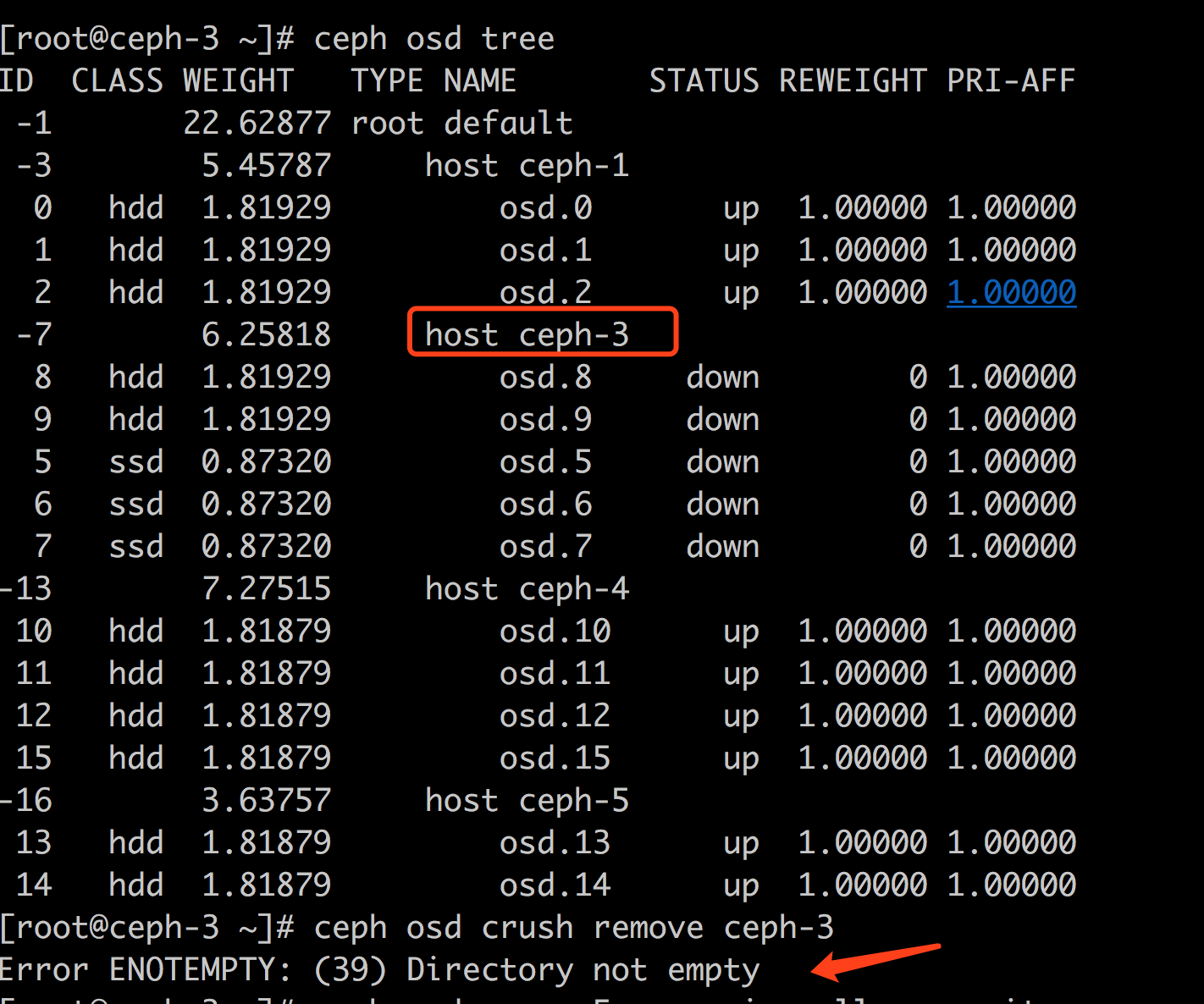
一个host下面一般有多个osd,一个一个地purge有点儿麻烦,能否直接ceph osd crush remove <host> 呢?
答案是: 不可以的,就如同不能直接删除非空目录一个道理:
rebalance 时间预估
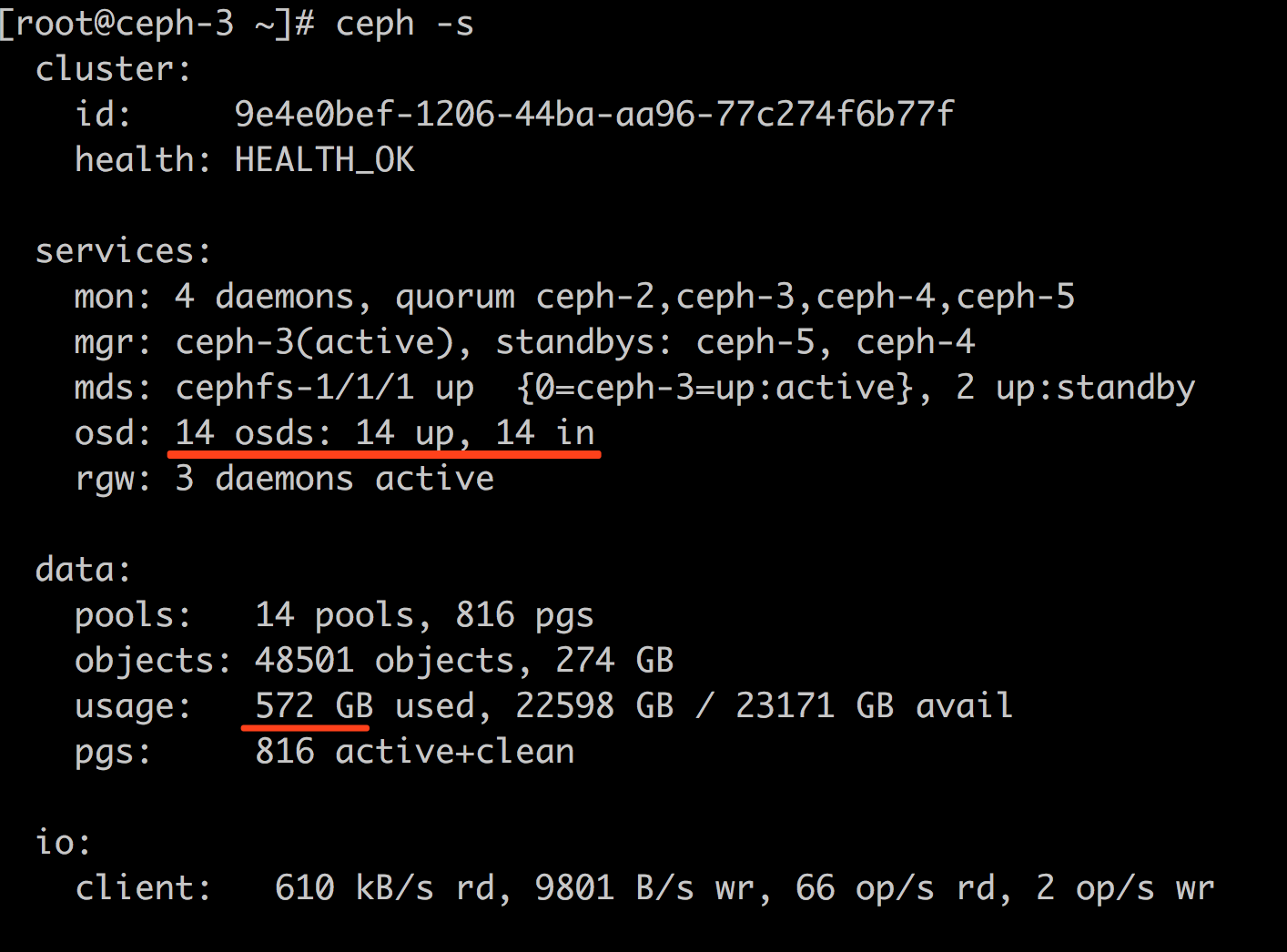
移除osd之前: 572 GB
移除osd以后: 399GB

应该说有 572-399 = 173GB的数据需要找回来, 然后计算带宽就行了,我这里的恢复速度也就 70MB/s ,如此计算的话: 173*1024/70/60=42 分钟
一般来讲,每秒700MB的网络才算正常,那样的话4分钟就能搞定
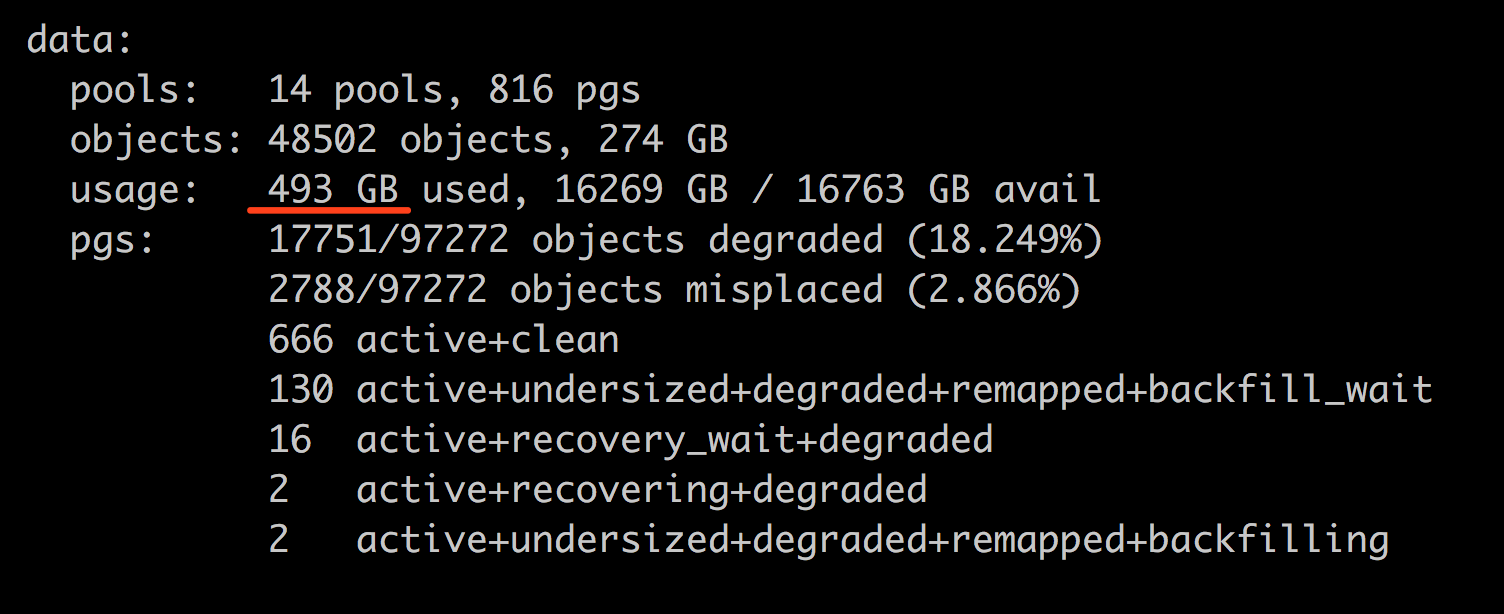
我的实际情况: 18:16:04 开始恢复, 18:46 的时候才恢复情况如下:(30分钟大约 50% 的样子)
结论:
crush要搞明白