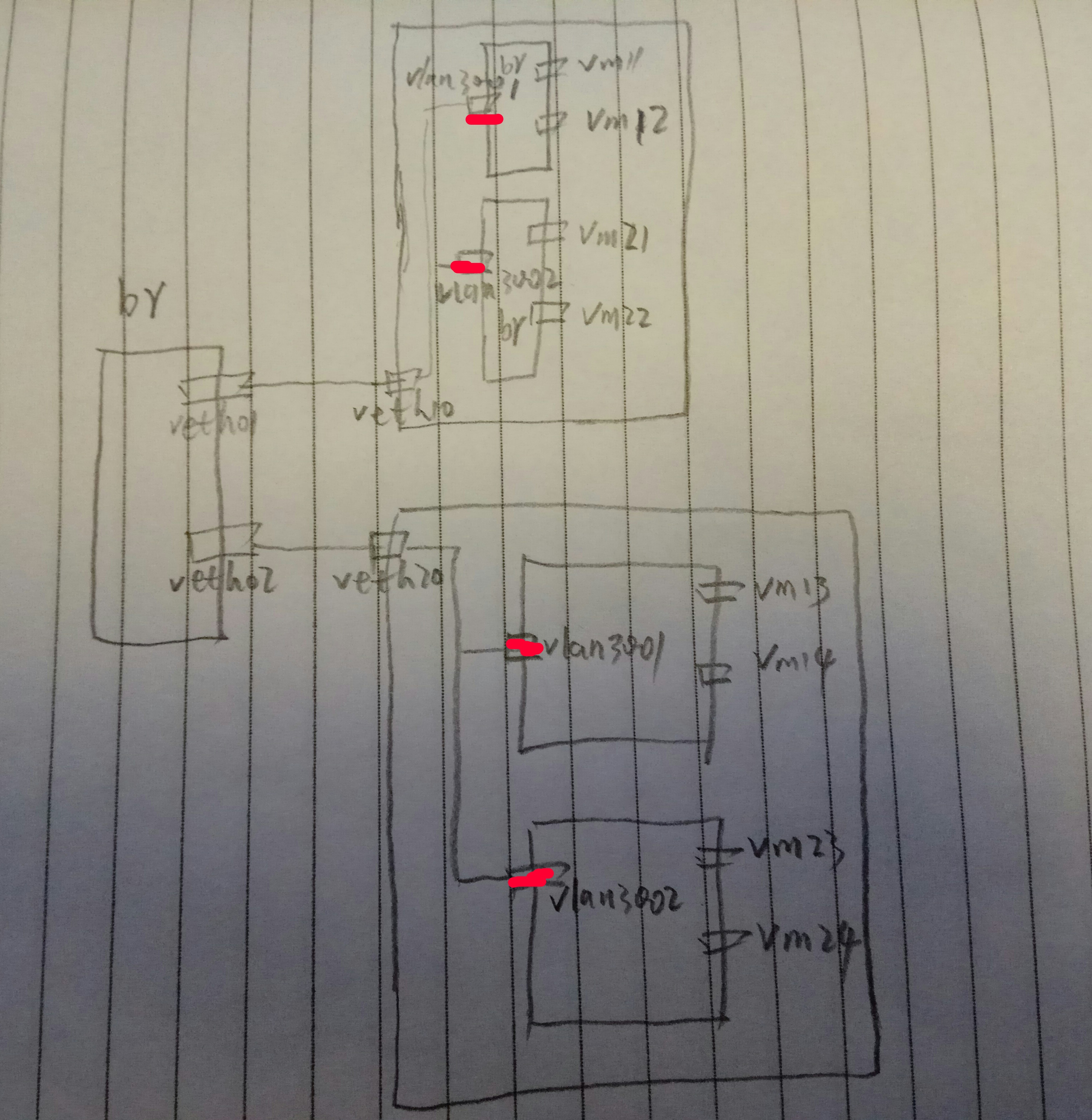
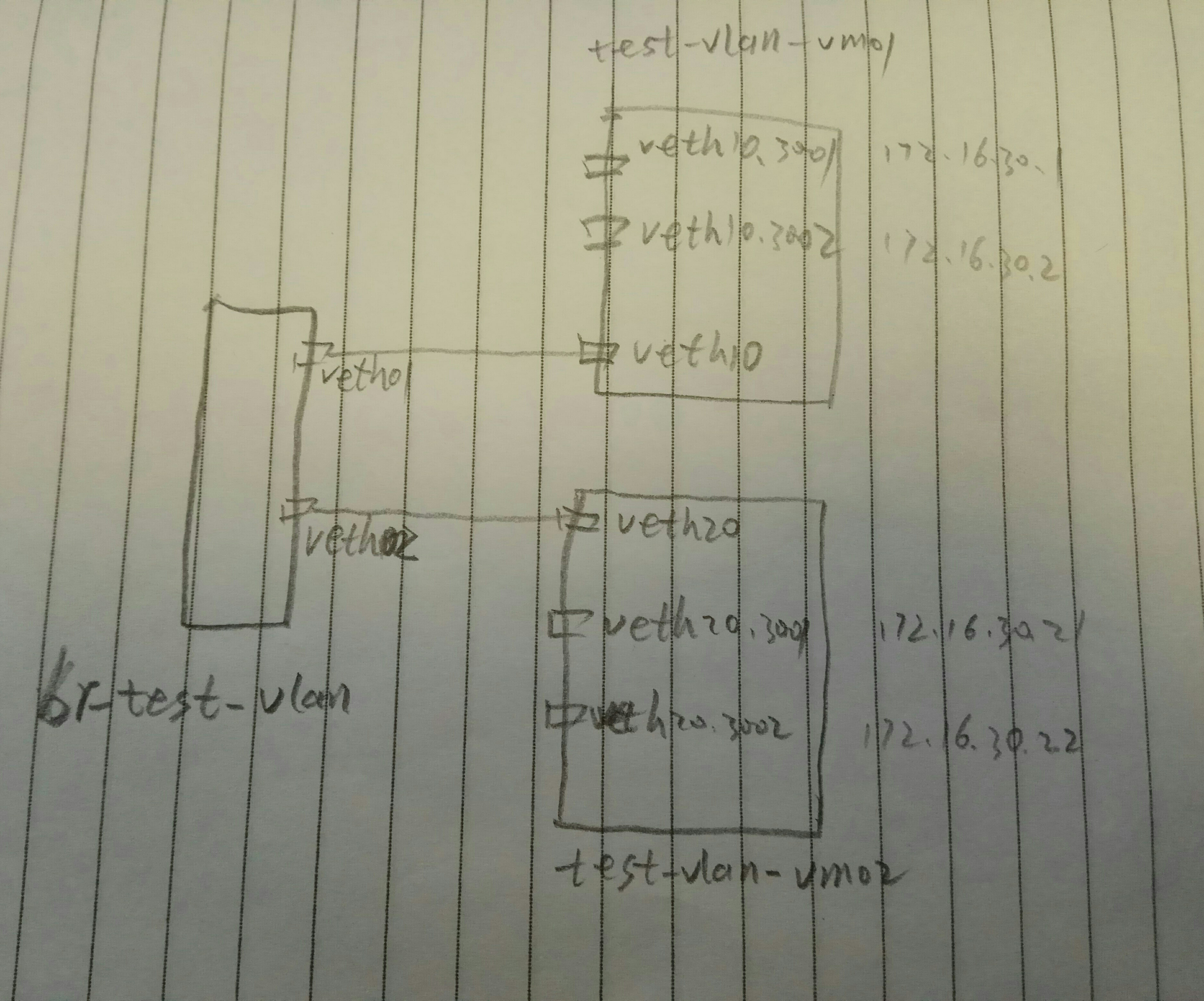
我们通过一个网桥两个设备对,来连接两个网络名字空间,每个名字空间中创建两个vlan
借助vconfig来配置vlan:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
#创建网桥 brctl addbr br-test-vlan #创建veth对儿 ip link add veth01 type veth peer name veth10 ip link add veth02 type veth peer name veth20 #将veth对儿的一段添加到网桥 brctl addif br-test-vlan veth01 brctl addif br-test-vlan veth02 #启动设备 ip link set dev br-test-vlan up ip link set dev veth01 up ip link set dev veth02 up ip link set dev veth10 up ip link set dev veth20 up #创建网络名字空间 ip netns add test-vlan-vm01 ip netns add test-vlan-vm02 #将设备对儿的另一端添加到另个名字空间(其实在一个名字空间也能玩,只是两个名字空间更加形象) ip link set veth10 netns test-vlan-vm01 ip link set veth20 netns test-vlan-vm02 #分别进入两个名字空间创建vlan和配置ip #配置名字空间test-vlan-vm01 ip netns exec test-vlan-vm01 bash #配置vlan 3001 和 vlan 3002 vconfig add veth10 3001 vconfig add veth10 3002 #启动两个vlan的设备 ip link set veth10.3001 up ip link set veth10.3002 up #分别在两个vlan上配置ip (这里简单起见,使用了同一个网段了IP,缺点是,需要了解一点儿路由的知识) ip a add 172.16.30.1/24 dev veth10.3001 ip a add 172.16.30.2/24 dev veth10.3002 #添加路由 route add 172.16.30.21 dev veth10.3001 route add 172.16.30.22 dev veth10.3002 #配置名字空间test-vlan-vm02 ip netns exec test-vlan-vm02 bash #配置vlan 3001 和 vlan 3002 vconfig add veth20 3001 vconfig add veth20 3002 #启动两个vlan的设备 ip link set veth20.3001 up ip link set veth20.3002 up #分别在两个vlan上配置ip (这里简单起见,使用了同一个网段了IP,缺点是,需要了解一点儿路由的知识) ip a add 172.16.30.21/24 dev veth20.3001 ip a add 172.16.30.22/24 dev veth20.3002 #添加路由 route add 172.16.30.1 dev veth20.3001 route add 172.16.30.2 dev veth20.3002 |
查看一下vlan配置:
|
1 2 3 4 5 |
# cat /proc/net/vlan/config VLAN Dev name | VLAN ID Name-Type: VLAN_NAME_TYPE_RAW_PLUS_VID_NO_PAD veth10.3001 | 3001 | veth10 veth10.3002 | 3002 | veth10 |
现在,我们可以分别在两个名字空间来ping另外一个名字空间的两个IP,虽然两个IP都能ping通,但是使用的源IP是不同的,走的vlan也是不同的,我们可以在veth01/veth10/veth02/veth20/br-test-vlan 任意一个上抓包,会看到vlan信息:
|
1 2 3 4 5 6 7 8 9 |
# tcpdump -i veth10 -nn -e tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on veth10, link-type EN10MB (Ethernet), capture size 262144 bytes 15:38:18.381010 82:f7:0e:2d:3f:62 > 9e:58:72:fa:11:15, ethertype 802.1Q (0x8100), length 102: vlan <span style="color: #ff0000;">3001</span>, p 0, ethertype IPv4, <strong><span style="color: #ff0000;">172.16.30.1 > 172.16.30.21</span></strong>: ICMP echo request, id 19466, seq 1, length 64 15:38:18.381183 9e:58:72:fa:11:15 > 82:f7:0e:2d:3f:62, ethertype 802.1Q (0x8100), length 102: vlan <span style="color: #ff0000;"><strong>3001</strong></span>, p 0, ethertype IPv4, 172.16.30.21 > 172.16.30.1: ICMP echo reply, id 19466, seq 1, length 64 15:38:19.396796 82:f7:0e:2d:3f:62 > 9e:58:72:fa:11:15, ethertype 802.1Q (0x8100), length 102: vlan 3001, p 0, ethertype IPv4, 172.16.30.1 > 172.16.30.21: ICMP echo request, id 19466, seq 2, length 64 15:38:19.396859 9e:58:72:fa:11:15 > 82:f7:0e:2d:3f:62, ethertype 802.1Q (0x8100), length 102: vlan 3001, p 0, ethertype IPv4, 172.16.30.21 > 172.16.30.1: ICMP echo reply, id 19466, seq 2, length 64 15:38:23.162052 82:f7:0e:2d:3f:62 > 9e:58:72:fa:11:15, ethertype 802.1Q (0x8100), length 102: vlan 3002, p 0, ethertype IPv4, 172.16.30.2 > <strong><span style="color: #ff0000;">172.16.30.22</span></strong>: ICMP echo request, id 19473, seq 1, length 64 15:38:23.162107 9e:58:72:fa:11:15 > 82:f7:0e:2d:3f:62, ethertype 802.1Q (0x8100), length 102: vlan 3002, p 0, ethertype IPv4, <strong><span style="color: #ff0000;">172.16.30.22 > 172.16.30.2</span></strong>: ICMP echo reply, id 19473, seq 1, length 64 |
如果试图从veth10.3001 去ping 172.16.30.22 是不能通的,因为是不同的vlan呀:
|
1 2 3 4 5 |
# ping -I veth10.3001 172.16.30.22 PING 172.16.30.22 (172.16.30.22) from 172.16.30.1 veth10.3001: 56(84) bytes of data. ^C --- 172.16.30.22 ping statistics --- 9 packets transmitted, 0 received, 100% packet loss, time 8231ms |
不适用vconfig的解法:
|
1 |
ip link add link veth10 name veth10.3001 type vlan id 3001 |
另: vlan 一般以 设备名.vlanid 来命名,不过并非强制,如下命名为 vlan3003也是没问题的
|
1 |
# ip link add link veth10 name vlan3003 type vlan id 3003 |
注意:一个主设备上相同vlan好的子设备最多只能有一个
|
1 2 |
# ip link add link veth10 name vlan3001 type vlan id 3001 RTNETLINK answers: File exists |
所以,正常来讲,一般是这样的: