如果在wsl中打开了某个目录,则在Windows上执行删除操作,虽然执行了删除操作,但是还是能看见,只是不能访问,直到wsl中退出该目录,该目录就会自动删除掉了
lua 之 require
lua 的 require 会自动避免重复加载的,如:
hello.lua
|
1 2 3 4 5 6 7 8 9 |
local a = {} local i = 0 print("loading a ...") function a:say() print(i) i = i + 1 end return a |
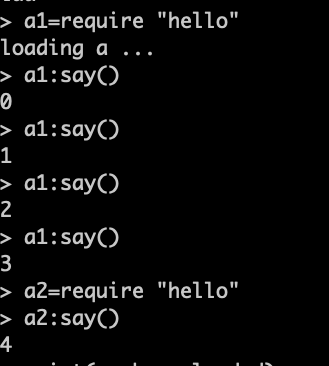
要想重复加载也行:
|
1 |
package.loaded[luafile] = nil |
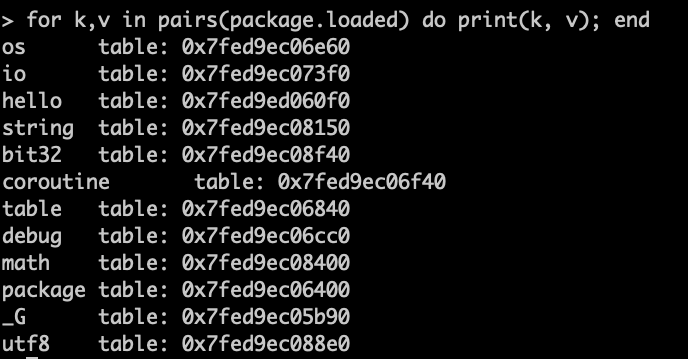
由此也可以通过package.loaded 知道都load了哪些包了:
如何知道进程运行在哪个核上
下图是htop能直观看到的数据:

第一个CPU很忙,太多的时间花费在了内核,为什么内核那么消耗CPU:
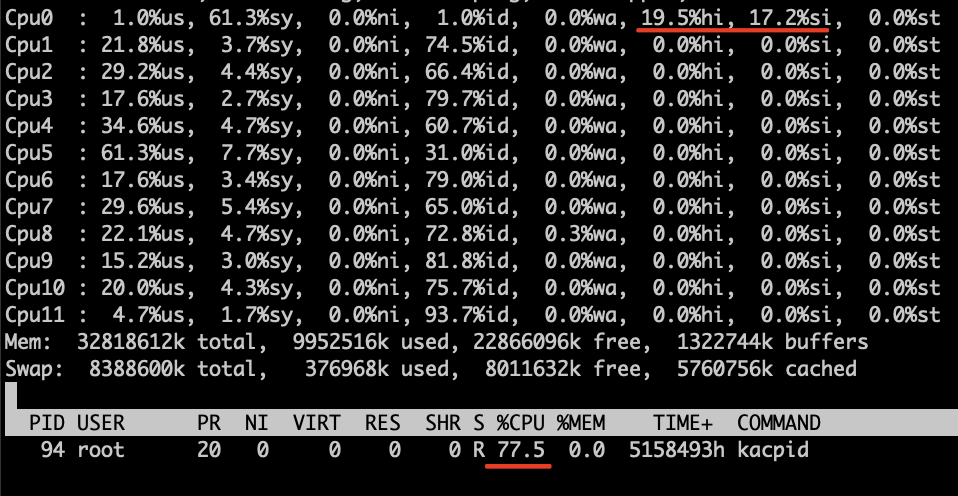
该CPU主要干了三件事:
- 硬终端 (估计这个是导致kacpid非常忙的根源)
- 软终端 (主要是网卡中断)
- 内核进程kacpid
连续执行如下命令会发现acpi中断非常多,而且确实都是发生在CPU0上的,自然处理该中断的也就是CPU0了;如果说要把网卡软中断和acpi中断分开,那么就是,要么把acpi从CPU0挪走,要么把网卡软中断从CPU0挪走
|
1 |
cat /proc/interrupts |grep acpi |
lua tcp udp
https://github.com/openresty/lua-nginx-module#ngxsocketudp
udp 支持unix dgram , 不需要连接池,可以把connect的结果保存到全局变量,但是,每次用完就close也开销不大
tcp 支持unix stream, 通过set_keepalive 支持连接池
中国移动的家用WIFI路由器网关dns问题
dns的cache长期不能refresh,解决办法,重启
nginx多进程间的负载均衡
nginx是如何把任务分配到每个worker的呢?这种分配平均吗?合理吗?
通过strace 一个worker进程,部分逻辑如下:

我们发现,accept4是放在epoll_wait后面的,不难推测:
- nginx的epoll_wait 是在看那个文件描述符有事件发生了(就是需要处理了),当然,这里不包含listen的那个文件描述符(不是不能,是不应该);如果有事件发生,则处理,这些都是已经接收了的连接,有可能是(已建立的连接上的)新的请求。如果没有事件发生,则调用accept4看看有没有新的连接进来。这个逻辑就保证了,如果我比较闲,那么我就接活儿,如果我没闲着,我就不接活儿了
golang的chan阻塞与deadlock
示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
func main() { c := make(chan int , 1) go func() { // 消费者 <-c }() go func() { // 如果没有这个协程,就得报deadlock而终止程序 i := 0 for { i++ } }() c <- 1 c <- 1 c <- 1 } |
如上程序:
如果没有第二个go协程,那么第一个协程是消费者,main协程是生产者,消费者死去后,就会出现deadlock错误; 原以为是runtime检测到我们在写一个没人消费的chan感到奇怪而报错,实际上不是的,甚至也不是写不进去而报错,而是,没有一个协程是能被执行的了(就好比陈佩斯的小偷中说的那样,这大半夜的也每个车让我指挥指挥),所以,runtime才感觉很迷茫,就报了个deadlock; 如果有第二个协程在的话,runtime会很高兴地去执行第二个协程的,真的不在意那个chan是否有人消费的。
kibana 搜索隐藏内容
|
1 |
$("span").each(function(k, v) { arr = $(v).html().match(/c_level=C.?/); if(arr && arr.length>0) console.log(arr[0]);}) |
hive transform
总是需要写一些transform放在hive上也挺麻烦,尤其这个transform还需要复杂的配置文件或者是访问IP首先等情况,还不见得能跑通,于是,我就发明了一个万能的transform:
|
1 |
hive -e "select transform(1) using 'nc 10.210.227.25 1234'" |
只需要在自己喜欢的机器上执行命令行程序就行,使用nc来做这个万能的transform,然而,自己的程序总是需要listen一个端口是不是也很麻烦,其实不难:
办法1:
使用 nc -l 10.210.227.25 1234 -e “your-command”
办法2: 如果你的nc版本太低,还不支持-e
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
package main import ( "flag" "net" "os" "os/exec" "strings" ) func main() { addr := flag.String("addr", ":1234", "[host]:port") cmdline := flag.String("cmd", "", "command") flag.Parse() command := strings.SplitN(*cmdline, ",,", -1) cmdName := command[0] args := command[1:] l, err := net.Listen("tcp", *addr) if err != nil { println(err.Error()) return } for { c, err := l.Accept() if err != nil { break } cmd := exec.Command(cmdName, args...) cmd.Stderr = os.Stderr cmd.Stdout = c cmd.Stdin = c go func() { if err := cmd.Run(); err != nil { println(err.Error()) } _ = c.Close() }() } } |
把这个编译一下,类似于nc的作用
注意:
使用transform时要注意:
|
1 |
hive -e "select transform(1) using 'nc 10.210.227.25 1234' from TableA limit 10" |
虽然这了有limit 10 ,你的transform干的可能不是10个的活儿,哪怕这个table只有一个file,可能和执行这个任务用到的机器数量有关;从这个角度来看,hive还不够聪明;
可能需要自己优化一下:
|
1 |
hive -e "select transform(1) using 'nc 10.210.227.25 1234' from (select * from TableA limit 10) a " |
transform 只能靠进程数量提高效率,没法在进程内并发?这个不担心乱序?
可以设置reducer的数量来限制并发。
transform的输出格式:
If there is no AS clause after USING my_script, Hive assumes that the output of the script contains 2 parts: key which is before the first tab, and value which is the rest after the first tab. Note that this is different from specifying AS key, value because in that case, value will only contain the portion between the first tab and the second tab if there are multiple tabs.
如果transform子句的using 后面没有as子句:
则输出被视为以第一个tab为分隔的两列,第一列是key,第二列是value;如果输出中没有tab,则整行都是第一列,第二列就是NULL;如果输出中有tab,则第一个tab之前的是第一列,第一个tab以后的都视为第二列
如果transform子句的using 后面有as子句:
则按照tab分隔视为多列
参考:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Transform