关于规则引擎
github上有不少关于规则引擎的项目,其中.net java 的比较多,go的就非常少。
https://github.com/topics/rules-engine
json的:
https://github.com/CacheControl/json-rules-engine
这个只是key op value 是否超过定义的规则
https://github.com/mithunsatheesh/node-rules
c#:
https://github.com/microsoft/RulesEngine
这个是编排工作流的
java:
https://github.com/selwynshen/nics-easy-rules
这里的思想可以看看
关于json规则引擎
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "name": "transaction minimum", "priority": 3, "on" : true, "condition": function(R) { R.when(this.transactionTotal < 500); }, "consequence": function(R) { this.result = false; R.stop(); } } |
这个的特点是,可以直接在规则中定义函数; 这个适用于外包软件中的定制开发
golang 中的指针
模拟电路 之 三极管的基本使用

通常情况下,我们不必使用电压表和电流表; 直接使用探针就行了。
bash 中文汉字乱码问题
篇首语
汉字乱码分很多种情况,自从计算机进入中国就从来没有间断过,本次只讨论其中一种情况。
现象:
- 终端上可以显示汉字,vim中编辑汉字也没问题
- bash中的汉字在移动光标的时候就乱了
分析与解答:
- 终端上能显示汉字,说明终端的编码和程序认为的你的终端的编码是一致的;就是说,你的终端设置为utf-8编码时,通常ssh都会把该信息告诉给服务器端的程序(如:bash),通常是不会错的,但是,bash中如果手动export LANG环境变量,且和终端实际设置不一致时,该bash启动的程序(如:vim)得到的LANG信息就是手动export 的LANG,可能和实际终端设置的不一致,这时候,bash启动的那些程序就不能正确处理(输入、输出)汉字了;注意: bash中手动设置的LANG环境变量不管export与否,都不影响bash本身,要想影响到bash也容易,只需要在export之后,再在该bash中执行一个新的bash,这个新的bash就会按照export的LANG来工作了,所以,bash本身处理(输入、输出)汉字并不受当前进程中设置的LANG的影响,只受bash启动时传递给bash的LANG的影响。
- 曾经,build容器镜像的时候,直接设置了LANG=zh_CN.UTF-8,于是每次docker exec -it $container-name bash 的时候,bash都是工作在LANG=zh_CN.UTF-8的配置下的,所以,总是不会出现上面讨论的这种问题的。
- 偶尔,有一次,使用了一个没有设置LANG=zh_CN.UTF-8 的容器镜像,创建了一个没有明确设置LANG=zh_CN.UTF-8的容器,于是,每次docker exec -it $container-name bash 的时候,bash环境中就只会存在创建容器(镜像)时指定的很少的几个环境变量,docker命令上下文中的LANG 是不会影响 docker exec -it $container-name bash 的。 这种情况可以在docker exec 时指定环境变量,如:
docker exec -e LANG=zh_CN.UTF-8 -it $container-name bash - 如何查看bash中影响到当前bash进程的那个LANG 呢?
- 不是 set
- 不是echo $LANG
- 而是: cat /proc/$$/environ
- 对于bash进程来讲,正确的LANG 和不正确的LANG 在程序逻辑上差别是什么呢?
- 这里不直接看代码,让我们通过strace看一下
- 比较方法:
- strace 一个LANG为空的bash和一个LANG=zh_CN.UTF-8的bash,然后输入汉字
- 前者: 逐个字节的read,逐个字节的write;虽然是逐个字节的write,到了终端时,终端也能拼成正确的汉字,所以,表面上工作的似乎是正常的
- 后者: 逐个字节的read,多字节的汉字时,是多个字节凑齐后一起write的;(注意:这里存在一点儿问题,如果用户就是随便输入的,根本不可能凑齐一个合法的字符呢?会不会就卡死了呢?)
- 但是,当我们使用方向键移动光标时:
- 前者认为我们好移动的是一个字节,而终端就啥了,总不能把光标放到一个汉字的中间(或三分之一处)吧
- 后者则能很好的告诉终端移动多少,于是就不会乱码,而且能很好的处理删除汉字的操作
- strace 一个LANG为空的bash和一个LANG=zh_CN.UTF-8的bash,然后输入汉字
- 虽然解决办法很简单,就是设置LANG, 但是什么时候设置LANG 却很关键。 懂了原理之后,以后再也不怕这种乱码了,以后再也不用总是靠“猜”了
内存都去哪儿了?
windows上启动虚拟机的时候,我们在任务管理器中看不到一个占用很大内存的进程(就是虚拟机进程),但是linux上启动虚拟机是可以看到这样的虚拟机进程的。
为什么呢?
有没有工具可以查看到虚拟机分配走的这部分内存呢?
有:vmmap
参考:https://serverfault.com/questions/19935/virtual-machine-memory-usage-not-appearing-in-taskmanager
hadoop中各种进程的作用
yarn中的资源调度:
参考: https://blog.51cto.com/14048416/2342195
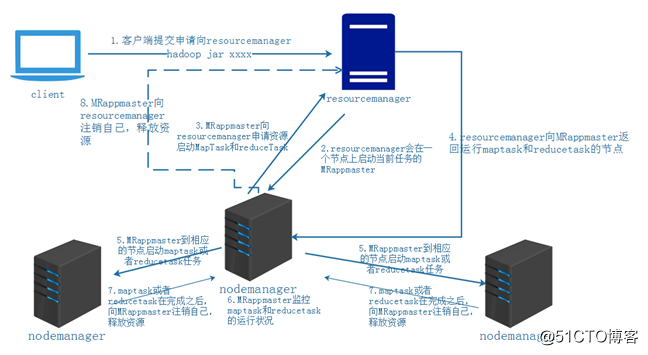
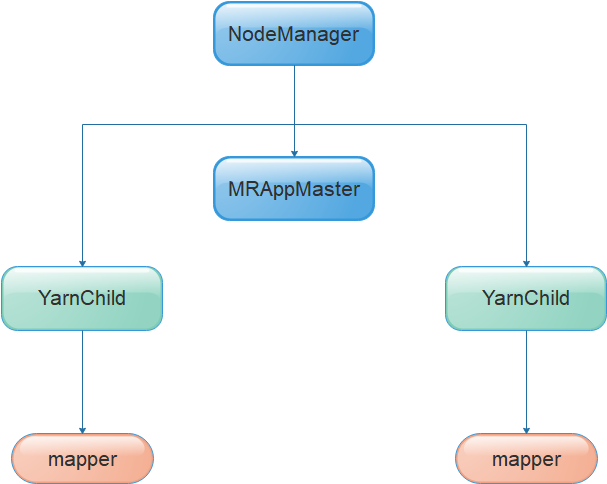
进程关系:
nodemanager要执行的脚本如下:
|
1 2 3 4 5 6 7 8 9 10 |
ll /tmp/hadoop-root/nm-local-dir/usercache/root/appcache/application_1576057255094_0007/container_1576057255094_0007_01_000003/ total 132 -rw-r--r-- 1 root root 129 Dec 12 04:15 container_tokens -rwx------ 1 root root 723 Dec 12 04:15 default_container_executor.sh -rwx------ 1 root root 669 Dec 12 04:15 default_container_executor_session.sh lrwxrwxrwx 1 root root 105 Dec 12 04:15 job.jar -> /tmp/hadoop-root/nm-local-dir/usercache/root/appcache/application_1576057255094_0007/filecache/10/job.jar -rw-r----- 1 root root 117057 Dec 12 04:15 job.xml -rwx------ 1 root root 3571 Dec 12 04:15 launch_container.sh lrwxrwxrwx 1 root root 64 Dec 12 04:15 sum.sh -> /tmp/hadoop-root/nm-local-dir/usercache/root/filecache/14/sum.sh drwx--x--- 2 root root 6 Dec 12 04:15 tmp |
default_container_executor.sh ==调起===> default_container_executor_session.sh ===调起===> launch_container.sh ===> 调起 ===> org.apache.hadoop.mapred.YarnChild
这里的脚本都是临时生成的,从进程上来看,YarnChild 的父进程是 default_container_executor.sh 而不是 launch_container.sh,是因为从default_container_executor.sh 到 org.apache.hadoop.mapred.YarnChild 的中间的所有“调起”,都使用的是exec,并不fork新的进程,也没有新的进程ID,以至于 org.apache.hadoop.mapred.YarnChild 的父进程就是default_container_executor.sh
(MRAppMaster和YarnChild的诞生方式差不多,都是nodemanager直接生出来的),所以所,MRAppMaster是一个临时的进程
各进程关系
NameNode: 只有在name节点上存在,只有一个进程。
DataNode: 只存在于数据节点上,每个数据节点有且只有一个这样的常住进程,负责该节点上数据的存取维护操作。
NodeManger:
ResourceMange:
从容器外部编辑容器内部文件的方法 docker-vim
通常来讲,容器为了更小,是不会带编辑器的,但是,利用docker cp 命令copy出来,编辑后再copy进去显得又比较麻烦,于是:
上一个简单的脚本:docker-vim
|
1 2 3 4 5 6 7 8 9 10 |
#!/bin/bash cname=$1 file=${2#/} pid=$(docker inspect -f '{{.State.Pid}}' $cname) [[ $pid == "" ]] && { echo $0 only use for running container; exit; } cd /proc/$pid/root vim $file |
用法:
|
1 |
docker-vim $contaner-name $file-in-container |
注意:
- 脚本中没有直接vim /proc/$pid/root/$file ,因为这个可以read到文件内容,但是write会失败; 所以,先cd到/proc/$pid/root ,再vim $file 这样是正常的
- 该方法 仅适用于运行这的容器,(通常这可能并不是问题),可能有更好的编辑文件的办法
- 将容器文件系统挂载到宿主机的某个位置
- 让容器动态挂载一个有编辑器程序的volume
- 做一个非常简易的无依赖的编辑器程序copy到容器里面
路由的错
明明服务listen了9736端口,外面访问该端口却连接失败。在服务器上tcpdump抓包发现,只有syn,并没有syn-ack,更没有rst。
难道是防火墙? Iptables都是空的;
难道有其它高级的设置?
难道网络有问题? 我已经ssh到这个机器上了(其实是从某个机器跳过来的)
灵光一闪,可能是路由问题,找不到回包路由,自然就没法回包了; ip route一下,果然没有默认路由,只有一条同网段机器的路由,我的ssh就是从同网段的其它机器上过来的。
添加默认路由后,一切ok了
upas 相关概念
node
nodemanager 是节点管理器,可以启动该节点上的服务器(server,包括domainAdminServer),添加节点的时候,节点类型有两种,一种是ssh类型,可以通过ssh来启动服务;另一种是java类型,说的就是nodemanager,默认listen 7730端口
domain
UPAS的最大管理单位,是一个逻辑概念
每个domain对应一个adminServer进程,一个节点上可以部署多个adminServer进程,相当于多个domain,每个域名字可以相同,ID一定不同;
同一个域中可以包含多个不同节点上的adminServer,他们之间靠组播进行同行,靠什么标识为同一个域的?
ID?: 每个adminServer按说应该有一个唯一的ID或者名字(但是文档说名字可以不唯一)
组播地址: 组播地址=组播IP+端口号
不同节点上的同一个domain的adminServer是如何身份验证的?
domain之间靠(虚拟)组播进行通信;组播就是真实意义上的组播,虚拟组播应该是类型组播功能的自己实现的一种通信方式吧。
- UPAS一般在域里的服务器之间通过组播共享相互的状态,因此需要IP地址和端口号。域脱离子网,不能通过组播共享信息时,用TCP代替Multicase。它在UPAS里被称为虚拟组播,创建域时可以声明要使用虚拟组播。
- 此时利用服务器的默认监听IP地址、端口号,会在服务器之间共享信息。因此在脱离子网的域里所有服务器必须声明监听IP地址、端口号。此外还要声明不能使用组播。
server
其实就是定义到某个节点上的一个upas进程,可以配置jvm选项、监听器等
application
组的概念
webadmin
是管理某个特定域的管理界面,upas中好像不存在一个可以创建、删除、修改domain的web控制台;创建、删除域是通过setup/ant 或upasadmin 来完成的,webadmin只用于当前域的配置。
webadmin中可以添加节点,节点设置只能在webadmin的首页找到
upasadmin
可以连接das和可以不连接das,二者能用的命令是不一样的,执行help时,就会只显示可用的命令的列表。
关于license
license过期只影响进程启动,不影响服务提供,只是记录证书过期日志而已。至于服务器时间不能正常,只是因为他们测试需要而已。
upas请求分发机制
- htl进程负责端口监听,请求进来后(即accept操作返回后),得到一个新的fd,通过unix socket将fd传送到hth进程
- hth进程还listen了一个端口,真实处理请求的进程会连接到这个端口,等着被分配任务,hth从htl接到fd后,读取请求,通过一定的分发规则,安排到某个任务处理者(就是webadmin中定义的server)
- 由于htl和hth之间是通过unix socket通信的,所以,二者只能在同一台机器上。也因为二者传递的是fd,也只能通过unix socket传递
- 由于hth和任务处理者通过tcp通信,所以,二者是可以在不同的机器上的
upws/bin/wswebadmin
这个并不是一个web管理界面,而是一个命令行接口,需要制定upws 安装目录才能正常启动,因为需要找配置文件:
|
1 |
UPWSDIR=/home/upas/upws /home/upas/upws/bin/wswebadmin |
不带任何参数时进入交互式命令行界面,通过 -C 选项可以直接执行命令,但是,返回的是json的数据;
wsadmin 和wswebadmin类似,除了输出的不是json; strace发现,二者都是通过访问 /home/upas/upws/path/wsmd 这个socket来工作的,这个socket是wsm listen的。
/home/upas/upas7/webserver 和 /home/upas/upws 居然是相同的东西,而且不是软连接
/home/upas/upas7/domains/upas_domain/config/domain.xml 这里记录了application connector等所有的东西。
server和upws之间是通过注册号来分发请求的,类似于nginx中的upstream名字