参考:
- colorTool: https://github.com/Microsoft/console/releases
- 可以直接使用iTerm的配色方案: https://github.com/mbadolato/iTerm2-Color-Schemes
DevOps
参考:
Linux桌面中一个非常有用的功能就是可以在任意文件夹中直接右键在这里打开bash终端,Windows中也是可以的:
shift + 右键 : 可以直接打开powershell, 然后输入bash就行了,似乎也很简单
如果还嫌麻烦的话,可以参考:https://blog.csdn.net/gulang03/article/details/79177500 直接将bash添加到右键菜单
更加高级一点的是使用cmder,可以直接注册到右键菜单,而且还可以在cmder中设置直接启动bash
|
1 |
cmder /REGIST all |
想修改系统环境变量,不知道如何找到入口,不同版本的windows差别较大,win10中比较方便的办法是: 直接在左下角的搜索中搜索“环境变量”,回车直达下面界面:

应该看不见了吧?
但是,看下图:
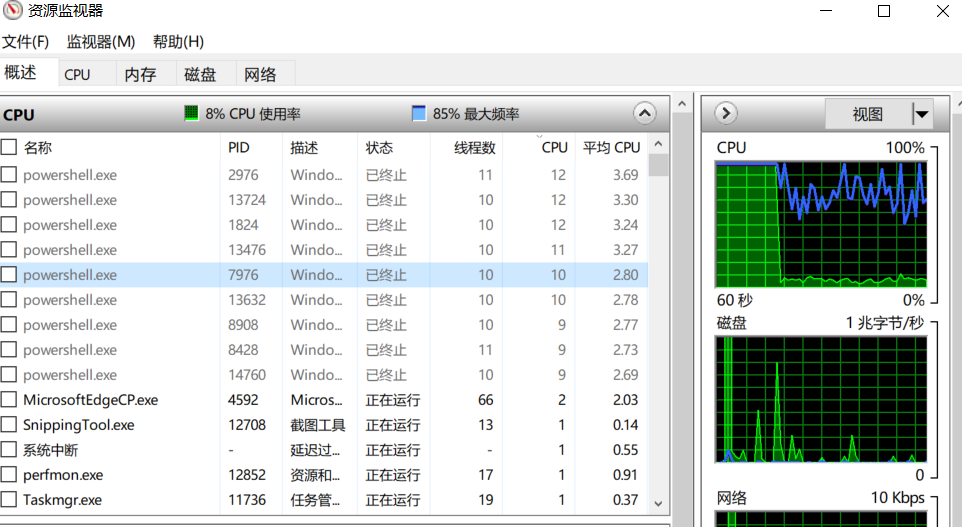
这里的powershell状态为已终止,而且还占用了一部分cpu呢。
这些powershell生前是这样子的:
|
1 |
do {;}while(1) |
最后,尽管看到了已终止状态的cpu,也不过是昙花一现,很快(10s左右吧)也就没有了
从下图来看,windows的powershell的死循环程序并没有占用100%的cpu,为什么?
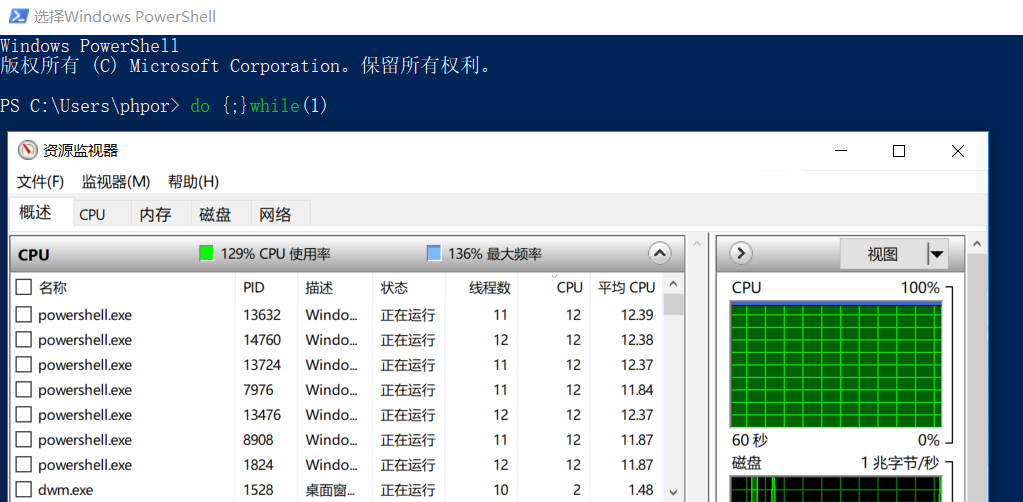
原因: 这里的 12.39*8 ~= 100 ; 因为这个电脑是4核心8线程的,满负荷是800%,将800%折合成100%的话,100%就折合成12.38%左右,所以说,这里的12.38%就是一个核心的意思;
当启动到9个powershell死循环的时候,就不能再保证每个进程占用12%的cpu了:

以前的软件开发非常注重方法,注重质量,软件开发周期长。
现在的软件开发更注重快速迭代。
一个很重要的原因是:
以前的软件多是开发完卖出去的;
现在的软件大多是自己提供线上服务的;
所以:
对于前者,你不可能让客户每天部署一个新版本;
对于后者,发现问题可以及时修正,成本很小。
以前开发软件,更关心能用,可用。至于可维护性并不重要,毕竟复杂的维护还能收更多的维护费用呢。
区块儿是干啥的
真的有些不太适应新版的编辑器
https://blog.csdn.net/xmcy001122/article/details/61623128
freeswitch也叫软电话交换机
freeswitch有docker版本,Windows版本,都非常方便安装
软电话有x-lite,
新装了个 openstack-dashboar 12.0.3 ,切换主题到material总是不成功,直接设置cookie:
theme=material
就可以了
openstack-dashboar 12.0.3似乎没有汉化包