企业的长治久安靠的是制度,企业的发展却要靠人
bash 之 信号处理
缘起:
docker stop 时往往会比较慢,起原因多半是docker 容器的init进程没有正确处理信号所致;docker stop的行为为: 先发送一个SIGTERM(15) 信号给init进程,如果一段时间(默认10s)后,依然没有退出,就直接发送 -9 信号,常常我们会登上10s,最终,进程的退出依然是仓促的;所以,实现一个好的init进程非常重要。
想用bash写一个docker 的init进程,当收到SIGTERM信号时,通知容器中的其他进程退出,其他进程退出后自己再退出,这样的话,其他进程可以有时间优雅退出,而且stop操作还可能很快完成。
版本1:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#!/bin/bash trap stop 15 PATH=$PATH:/usr/sbin/:/usr/bin function stop() { while :; do local pid=$(pidof cmd) [[ "$pid" == "" ]] && break kill $pid 2>/dev/null sleep 1 done exit 0 } cmd |
实际并不凑效; 原因: bash 在执行外部命令的时候,是不处理信号的
改进:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#!/bin/bash trap stop 15 PATH=$PATH:/usr/sbin/:/usr/bin function stop() { while :; do local pid=$(pidof cmd) [[ "$pid" == "" ]] && break kill $pid 2>/dev/null sleep 1 done } nohup cmd & while :; do sleep 10 done |
不足:当有信号到时,依然要等sleep 睡足才能处理信号,如果每次sleep 时间足够短,则总是启动sleep进程也非常不优雅,本身总是看到一个sleep进程已经够闹心的了
改进:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#!/bin/bash trap stop 15 PATH=$PATH:/usr/sbin/:/usr/bin function stop() { while :; do local pid=$(pidof cmd) [[ "$pid" == "" ]] && break kill $pid 2>/dev/null sleep 1 done } nohup cmd & while :; do read line done |
优点:
- 看不到sleep函数了
- read line 并不消耗多少资源
- 虽然 read 函数是阻塞的,但是却不影响bash实时处理信号
缺点:
- 创建容器时需要 -it 选项,因为bash标准输入需要是正常的,才能是的read不会失败而正常阻塞,否则,read会一直失败,导致死循环占用100% CPU ; 安全一些的做法是,发现read失败直接退出
测试脚本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#!/bin/bash trap signal 15 function signal() { echo handle signal } while :; do read line echo $line sleep 10 done |
执行该脚本,然后发送信号15给bash进程,发现:
- 当执行到sleep 10 的时候,不能实时处理信号
- 当阻塞在read时,可以实时处理信号
下面这种写法也比较简单,可以实时处理信号,但是,这个bash进程会fork一个子进程,从top中看起来不够干净。
|
1 |
CMD [ "/bin/sh", "-c" , "trap 'exit' TERM; { while :; do sleep 100 ;done } & wait" ] |
Dell服务器监控之 OMSA
Dell OpenManage Server Administrator (OMSA)是一款全面的一对一系统管理解决方案。
OMSA可分为两种:
- 集成式界面 – 基于Web浏览器的图形用户界面(GUI)
- 命令行界面(CLI) – 通过操作系统访问
https://blog.csdn.net/wh211212/article/details/70014141
关于云上负载均衡的使用
对于http负载均衡,往往有超时限制;对于tcp负载均衡,往往不做源地址转换(无法通过配置的方式设置为需要源地址转换),对于如下部署方式:
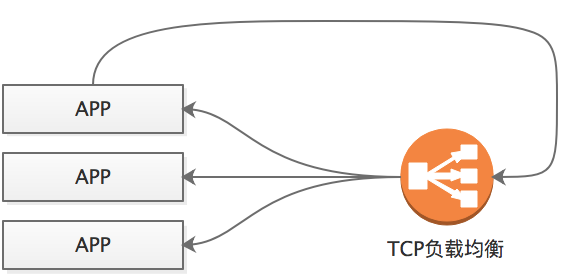
APP如果调用自己的话,可能服务器A发起请求,经过负载均衡后,又落到了服务器A自身,这是,由于负载均衡没有做源地址转换,所以,A的回包是发现目的地址就是自己,就不需要离开本机了,然而这种没有经过源地址转换的回包是不会被认可的,所以,这种部署方式存在较大弊端,尤其是一个服务器上部署多个应用时,应用之间的频繁调用就必然会遇到这个问题。
改进方案:

如果请求发起总是在APP上,则上述模式工作的会比较好;
但是,还有情况需要考虑,nginx做内部重定向的情况也是非常常见的,当访问a.i.phpor.net 时,很可能需要nginx直接内部转发到b.i.phpor.net ,这是,请求发起者是nginx,为了节省资源,b.i.phpor.net 也是使用的同样的负载均衡和nginx,于是,又出现了前面所讨论的问题。
再次改进,确保nginx不会重定向请求到负载均衡,毕竟还是要回来,索性在nginx上稍微麻烦一些,直接转发到自己,或者nginx上将所有自己能提供的服务的域名都解析到127.0.0.1
network of docker on mac
mac 上的docker本质上不是直接跑在mac上的,而是跑在mac上的虚拟机上的,所以,从mac上访问容器的IP就比较麻烦,默认是不行的
参考: https://www.cnblogs.com/yuyutianxia/p/8073411.html
后记:
想在macos上通过ssh-vpn的方式方便访问另外一个网络
ssh 之远程端口转发与本地端口转发
如图:

Local B想访问Remote B的80端口,但是由于网络限制,访问不到,但是,Local A可以访问Remote A的22端口,于是:
|
1 |
ssh -f -N -L 80:RemoteB:80 RemoteA |
这样就可以在Local A上listen一个80端口,将接收到的数据包转发给Remote B的80端口
由于listen的端口在本地,所以叫做本地端口转发。
-f 选项: 后台执行
-N 选项: 不执行任何命令,仅仅是用于端口转发
同样是Local A可以主动访问Remote A,但是Remote A不能ssh访问Local A,我们想让Remote B能访问Local B的80端口,如何做呢?(注意: 这里并不是上述逻辑的一个翻版)
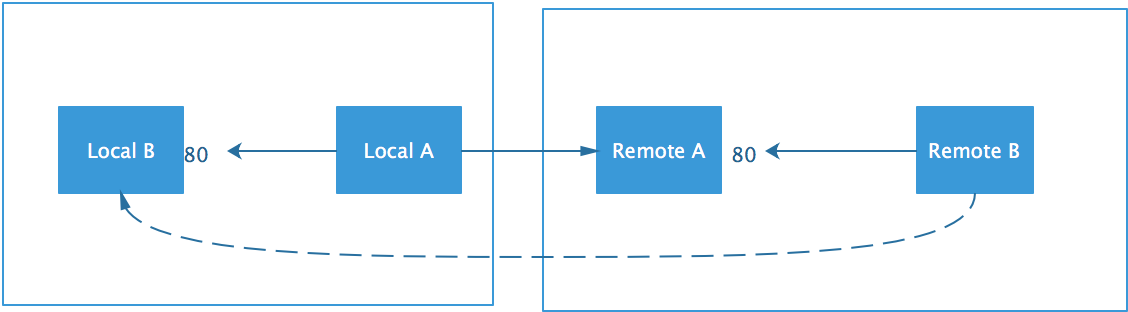
命令:
|
1 |
ssh -f -N -R 80:LocalB:80 RemoteA |
这样就可以在Remote A上listen一个80端口,将接收到的数据转发到Local B的80端口;
由于listen的80在远端,所以叫远程端口转发
相关原理:
当通过端口转发创建虚线中的连接时,local A和remote A 之间并不会创建一个新的tcp连接,而是在原有tcp连接上创建了新的channel,这个可以在ssh 时 -vvvv看到相关信息
如果想要以daemon的形式只做端口转发,不想交互式的登录的远程机器,可以使用-f -N选项,如下:
|
1 |
ssh -f -N -R 80:LocalB:80 RemoteA |
如果想30分钟后失效,则可以:
|
1 |
ssh -f -R 80:LocalB:80 RemoteA sleep 1800 |
WordPress 之 json api
WordPress的json api插件有两个:
一个是官方的: (官方的在插件管理里面搜不到,没法自动安装,需要自己手动下载后安装)
https://it.wordpress.org/plugins/json-api/
一个是用户开发的:
H3C 之 nat
首先进入接口上下文:
interface g0/1
对于nat出去的话,使用nat outbound 如:
nat outbound #所有的地址都可以通过默认的ip地址出去
或
nat outbound [ $acl-number ] [ address-group $address-group-number ] #指定的acl 通过指定的地址组中的ip地址出去
对于nat进来的话,使用nat server 如:
nat server protocol tcp global $ip $port inside $in_ip $in_port
其中 :
$ip 可以是该接口上的任意某个IP
$port 可以是任意希望暴露的端口
$in_ip 转发到内部的IP
$in_port 转发到的内部的端口
H3C 路由器之Qos
http://www.h3c.com/cn/d_201308/794662_30005_0.htm#_Toc364928020
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
3.4 配置步骤 # 配置时间段time_1。 <Switch> system-view [Switch] time-range time_1 12:00 to 18:00 working-day # 配置二层ACL 4000规则匹配源MAC和目的MAC并引用时间段time_1。 [Switch] acl number 4000 [Switch-acl-ethernetframe-4000] rule permit source-mac 0000-0000-0002 ffff-ffff-ffff dest-mac 0000-0000-0001 ffff-ffff-ffff type 0800 ffff time-range time_1 [Switch-acl-ethernetframe-4000] quit # 配置流分类c_deny引用ACL 4000。 [Switch] traffic classifier c_deny [Switch-classifier-c_deny] if-match acl 4000 [Switch-classifier-c_deny] quit # 配置流行为b_deny的动作为丢弃数据包。 [Switch] traffic behavior b_deny [Switch-behavior-b_deny] filter deny [Switch-behavior-b_deny] quit # 配置QoS策略Q_deny,将相应的流分类和流行为关联。 [Switch] qos policy Q_deny [Switch-qospolicy-Q_deny] classifier c_deny behavior b_deny [Switch-qospolicy-Q_deny] quit # 在与Router相连的端口GE2/0/1的入方向上应用QoS策略Q_deny。 [Switch] interface GigabitEthernet 2/0/1 [Switch-GigabitEthernet2/0/1] undo shutdown [Switch-GigabitEthernet2/0/1] qos apply policy Q_deny inbound [Switch-GigabitEthernet2/0/1] quit |
acl 是符合一定规则的集合
流分类是符合一系列acl的集合
流行为是允许或不允许
Qos 是一组规则,说的是什么样的流分类执行什么样的流行为
最后可以在接口的上下文中应用预先定义好的Qos
Java webserver 内存爆炸Debug
现象:
只要访问指定的某个url,webserver就会很快死掉,直接原因是,内存消耗太多被oom
分析:
其实,这种问题多半是从数据库中一次查询太多数据所致,更直白说就是sql select查询时没有添加limit限制,基本没必要继续查,开发人员闭眼思考3秒就应该知道是哪条sql导致的了,多余的debug都是浪费时间。
但是,有些开发人员就觉得自己遇到了什么高深的bug似的,不见棺材不掉泪,不到黄河不死心,毕竟就算刻意让他写一个消耗内存的程序,都不见得能写出来,所以,下面就简述一下How to debug。
办法1:
通过sql-sniffer工具(或者mysqldump)抓包,看看请求都触发了哪些sql语句,一般也能看出来了。
办法2:
不断地jstack 该java进程,然后触发url请求,分析最后一次堆栈,通过进程死前的堆栈也能分析出来进程是死在哪里的
|
1 |
pid=123;i=1;while $(jstack $pid >/tmp/$i.stack);do ((i++)); sleep 1;done |
eg:

办法3:
通过ulimit -c 设置,让进程死时留下一个core文件,然后分析core文件