情景: 拿容器当虚拟机用,容器有内存也有swap
问题:
有些程序(Java)只用内存,swap闲着也不用,当内存用完时,由于有大量空闲的swap,所以不会oom,但是进程申请内存被阻塞,该进程的cmdline读取不了,就影响宿主机ps,top
DevOps
情景: 拿容器当虚拟机用,容器有内存也有swap
问题:
有些程序(Java)只用内存,swap闲着也不用,当内存用完时,由于有大量空闲的swap,所以不会oom,但是进程申请内存被阻塞,该进程的cmdline读取不了,就影响宿主机ps,top
场景: 有个同学不知道因为啥,将容器内部的 /sys/fs/cgroup 挂载到了外面的某个目录; 但是这个目录是很有用的,不想随便被挂载,如何从image中去掉呢?
docker没有给出一个方便的方法, https://github.com/gdraheim/docker-copyedit 给了一个办法,原理如下:
每个image都是有一个manifest.json 文件的,相关配置信息都在这里了,但是你看不到image文件,更无从去谈修改manifest.json 文件了,所以:
|
1 |
docker save docker-registry.i.bbtfax.com/bee_centos7 -o /data1/centos7.tar |
|
1 |
tar xf /data1/centos7.tar -C /data1/centos7/ |

|
1 |
cd/data1/centos7/ ; tar cf ../centos7.modify.tar . |
|
1 2 3 |
# docker load -i centos7.modify.tar The image phpor.net/bee_centos7:latest already exists, renaming the old one with ID sha256:b14fe97b3bc959677c252e74e0ae318fa26028ac78d236a0973c3e235bf7a68b to empty string Loaded image: phpor.net/bee_centos7:latest |
我这里因为已经存在了同名的image,所以,旧的image的名字就被抢走了,但是ID没有变,新导入的image有自己新的ID
每次查找关心的进程都去ps 再 grep显得好麻烦,而且这是一个非常常用的操作,所以,熟练使用pgrep将有效提高工作效率。
如果不看文档直接去pgrep 你关心的东西,可能得不到想要的效果,因为你关心的是进程的参数,而不是进程名,而且只输出pid,似乎也用处不大,所以,你可能非常关心两个选项:
-f: 模拟情况下,只匹配进程名(/proc/$pid/comm),使用-f选项可以匹配整个命令行(/proc/$pid/cmdline);
-a: 默认只输出pid, 使用-a选项可以输出pid 和整个命令行
所以,pgrep的正确姿势为:
|
1 |
pgrep -af $pattern |
高级用法:
当我们想在 a.sh 中判断a.sh脚本是否已经在执行时,我们可以通过 -o 选项来实现:
|
1 |
pgrep -of a.sh |
如果得到的pid就是自己,则说明没有已经在运行的a.sh;
按照ppid来查找:
|
1 |
pgrep -P $pid |
往常,我使用docker的network=none ,然后使用pipework给容器添加一个外部可访问的IP,然后,容器就能访问外网了;
后来,我在openstack上创建的centos7虚拟机上安装docker,同样的方式启动的容器却无法访问外网,首先,centos7虚拟机的网卡去掉任何安全组,并设置为非管理状态; 检查centos7的ip_forward 是打开的,最终,发现差别就在于,原来的iptables规则中 FORWARD 的策略是ACCEPT ,而现在是FORWARD 策略是 DROP的;
问题: iptables的 FORWARD 的DROP策略是在哪个环节设置的呢?
参考docker 源码发现如下逻辑:
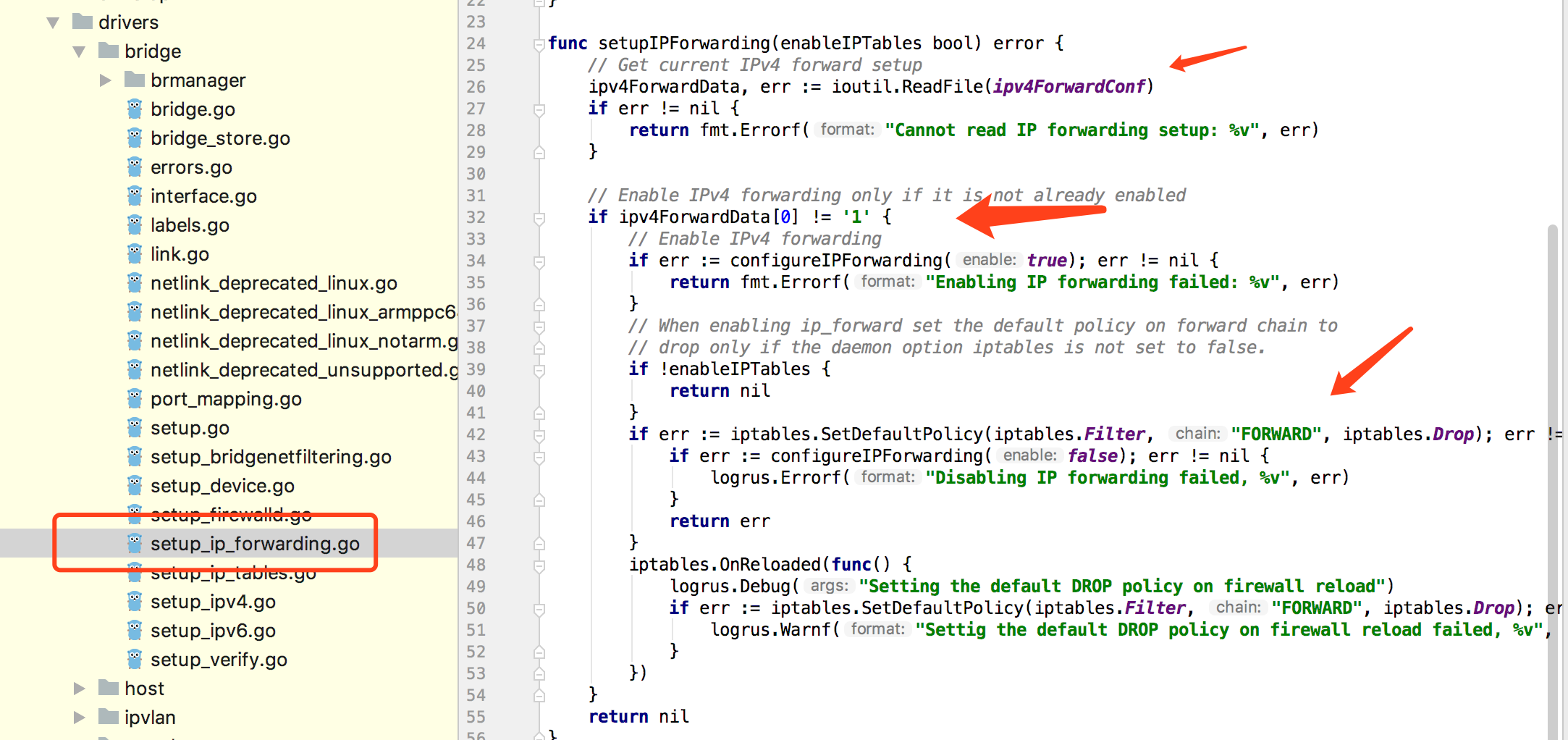
基本逻辑为:
如果本来是开启着ip转发的,就不会去设置iptables 的forward链的默认策略了;
如果本来没有开启ip转发的,就会去设置iptables 的forward链的默认策略。
显然,曾经的机器在docker启动前就已经设置了ip转发了, 而后来的机器在docker启动前还设置ip转发,虽然最终是都设置了IP转发,但是结果却不同;如果直接让docker来管理容器的网络,则docker会按照要求自动添加forward规则,然而,现在我们用的是pipework,就需要自己添加forward规则了,势必会麻烦一些;流氓一些的做法就是直接修改FORWORD 的默认策略。
bash中有个export,可以导出变量给子进程使用; 但是函数没法导出给子进程使用,如下:

我想通过nc+bash创建一个tcp server, nc负责收发数据,bash负责处理数据,如何将nc和bash结合起来呢?
思路1: 通过nc的-c选项实现
思路2: 只要能想办法将nc的标准输入和标准输入重定向给bash脚本就行了; 我们常见的管道、进程替换都只能同时做重定向标准输入或标准输出的其中一件事情; 如:
|
1 |
nc -l -k -U /tmp/a.sock | while :; do read cmd echo $cmd done |
或:
|
1 |
while :; do read cmd echo $cmd done < <(nc -l -k -U /tmp/a.sock) |
这两个都是单向的
思路3: 我们通常使用exec来做重定向,似乎也比较麻烦
思路4: bash中提供了一个coproc关键字,似乎用在这里再合适不过了
方法1:
handler.sh
|
1 2 3 4 |
while :; do read cmd echo $cmd done |
server.sh
|
1 |
nc -l -k -U /tmp/a.sock -c handler.sh |
这里利用了nc 的-c选项;
注意:
|
1 |
nc -l -k -U /tmp/a.sock -c 'bash handler.sh' |
这里是通过两个文件来实现的,对于脚本程序来讲,如果一个文件能实现会方便很多;那么 nc 的 -c 选项能否接受一个bash 的function呢?直接写function显然是不行的,我们知道,环境变量是可以继承的,但是function 是不行的(参考: https://phpor.net/blog/post/9188),而且我们也不能把function赋值给一个变量; 或者可以这么实现:
|
1 2 3 4 5 6 7 8 9 |
if [[ $1 == "serve" ]]; then while :; do read cmd echo $cmd done exit fi nc -l -k -U /tmp/a.sock -c "$0 serve" |
但是,显得好不优雅; 而且,最大的问题就是,一不小心就可能成为fork炸弹💣
方法2:server.sh
|
1 2 3 4 5 6 7 8 9 10 |
#!/bin/bash coproc handler { while :; do read cmd echo $cmd done } [ -e /tmp/a.sock ] && rm -fr /tmp/a.sock nc -l -k -U /tmp/a.sock <&${handler[0]} >&${handler[1]} |
注意:
问题:
参考:
总结:
场景:
|
1 |
printf "%s\n" $(</proc/$pid/cmline) |
对于多个部分的命令行会打印到多行,如下:

其实,printf就是这个表现的,如下:

也就是说,最后一个 %s 是不能吃掉多余的参数的,相反, printf 是如下方式消费参数的:

|
1 |
for d in /proc/*;do [[ $d =~ /proc/[0-9]+ ]] && echo ${d#/proc/};done |
ls 可以list /proc 目录下所有的pid,但是线程id是list不到的,如:
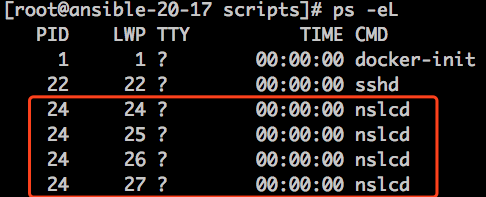
我们 ls /proc 的时候,只能看到 24 这个目录,看不到25 26 27 这些目录,那么线程的信息如何访问到呢?
实际上,虽然我们不能ls /proc 看到线程,但是,如果有了线程id,还是可以通过 /proc/$thread_id 来访问的,如:


如何计算字符串中单词的数量,但是不使用wc? eg:
|
1 2 3 |
str="apple orange pear" arr=( $str ) echo ${#arr[@]} |
如果字符串的内容在文件中,则可以直接 read -a arr 来读入到指定数组中,然后再获取数组的长度即可
参考:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#!/bin/bash CGROUP_DIR=/sys/fs/cgroup/memory UNLIMITTED=9223372036854771712 read mem_total <$CGROUP_DIR/memory.limit_in_bytes read mem_used <$CGROUP_DIR/memory.usage_in_bytes mem_free=$((mem_total - mem_used)) read mem_swap_total <$CGROUP_DIR/memory.memsw.limit_in_bytes read mem_swap_used <$CGROUP_DIR/memory.memsw.usage_in_bytes swap_total=$((mem_swap_total - mem_total)) swap_used=$((mem_swap_used - mem_used)) swap_free=$((swap_total - swap_used)) if [[ $mem_total = "9223372036854771712" ]];then /usr/bin/free -h && exit fi printf "%20s%20s%20s\n" total used free printf "Mem:%16s%20s%20s\n" $((mem_total/1024/1024))M $((mem_used/1024/1024))M $((mem_free/1024/1024))M printf "Swap:%15s%20s%20s\n" $((swap_total/1024/1024))M $((swap_used/1024/1024))M $((swap_free/1024/1024))M |
