cfdisk is a curses-based program for partitioning any hard disk drive.
DevOps
cfdisk is a curses-based program for partitioning any hard disk drive.
阿里云OSS比云硬盘要便宜很多,而且阿里云提供一个叫做ossfs的工具,可以将OSS挂载成本地文件系统,如果使用docker的话,也可以很容易实现一个docker volume的插件,岂不快哉!
ossfs挂载成本地文件系统后:
head -c 100 会不会很快?
测试发现,不会很快,ossfs会在/tmp目录生成一个临时文件,下载的数据远不止100字节; 所以,对于特别到的文件来讲,是受制于本地磁盘的容量的。
写入是如何实现的?写大文件时,会不会占用大量内存或本地磁盘?
写入大文件时,会在 /tmp 下创建一个临时文件(该文件打开后立即删除的,只能通过ossfs进程来看),写完后再上传到oss上; 所以,写入的文件大小同样受制于本地磁盘的容量。
ls 命令会不会快?
当目录下文件很多时,ls会非常慢。原因:ls不仅仅是一个http请求拉取文件列表,而是在拉取文件列表之后,还要通过head请求获取每个文件的元数据,假如一个目录下有几万个文件,就需要几万次请求
ossfs 将oss挂载成本地文件系统后:
https://www.cnblogs.com/zhengah/p/5889340.html
socat做Unix socket转发并抓包,不错
Hello world:

解说:
表索引情况如下:
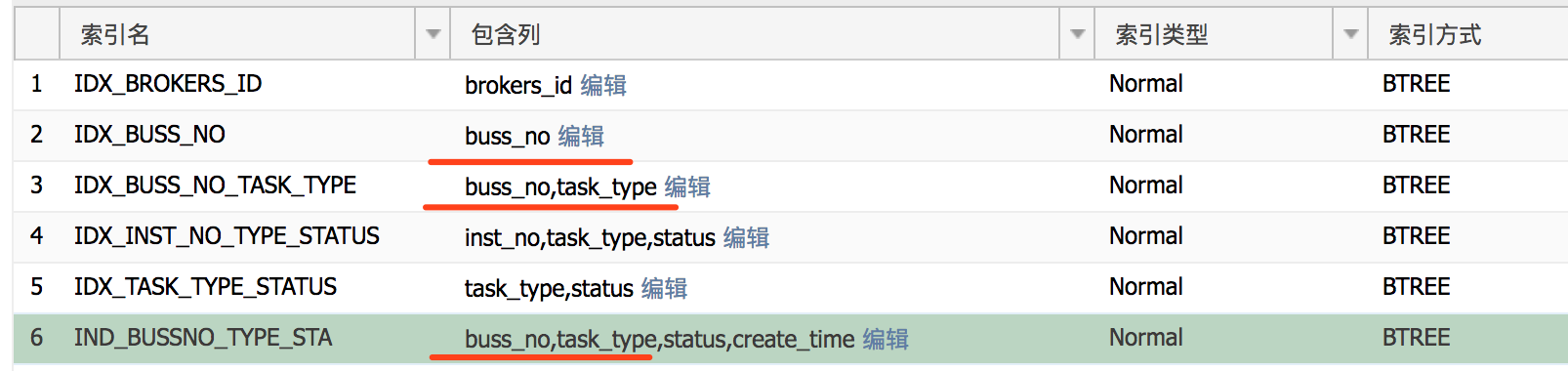
我们发现,buss_no 开头的索引就有三个,从名字上来看,是个类似于唯一号的字段,从buss_no 的索引类型来看,不是唯一索引,很可能就是不唯一的;但是,直觉判断,不能看像类型、状态之类的字段有超大的重复度。实际分析发现,每个buss_no 不会超过10条记录;对于这种情况,下面的两个buss_no开头的联合索引就是非常多余的,因为后面的两个联合索引总是先定位buss_no,在定位其他字段的;由于buss_no已经把结果集缩小到10条记录一下了,对于10条记录集的数据量完全可以自己在程序中进行排序、查找等处理,大可不必再创建联合索引,这样会导致索引很大,现在这个表的索引数据情况为:

不难发现,索引空间比表数据空间都大很多了
注意: 有些情况下,使用的覆盖索引和这种情况有些许类似,但不可等而视之
如: 类型、状态字段,值往往只有很少的几个,创建索引的意义不大
面对已经存在了大量索引,如何验证使用索引和不使用索引的执行效率差别的大小呢?
直接删掉不想用的索引自然是个办法,但是我们的操作可能是线上的,随意删除和创建索引太不专业了;幸好mysql早就帮我们想好了,我们可以在sql语句中指定是否启用和禁用指定的索引:https://www.cnblogs.com/lcngu/p/6023179.html
参考:
stat一个目录时卡死:

(这个错误和十年前遇到的执行du就卡死的问题,如出一辙)
dmesg 错误信息:

这个机器早被下线了,看来是下线时清理的不够好,现在还有一个机器挂载这死去的机器的nfs呢:(3年了)
https://www.makeuseof.com/tag/upscaling-how-does-it-work-and-is-it-worth-it/
关于4k电视看2k视频的问题,有些电视可以将2k视频转成4k视频来播放的(这样会更耗电的吧?)
抽帧命令:
|
1 |
ffmpeg -i HPIM0002IMP.MP4 -r 15 HP2.mp4 |
原因:
MP4有3种编码,mpg4(xdiv),,mpg4(xvid),avc(h264);
原本是h264编码,抽帧后变成了mpeg4了
抽帧前:

抽帧后:

解决办法:
转码为 h264格式; 问题,转码后,文件体积增大到原始文件的3倍(这个好不地道)
参考:
错误信息:
查看卷列表时,dashboard提示: 无法获取连接信息 ; 英文提示应该是: Unable to retrieve attachment information.
查看日志:
发现一个卷是挂在某个实例上的,但是实例早被删掉了,所以“无法获取连接信息”;
实例ID: a95f316f-aeb7-40ce-8887-9145499518fc
卷ID: 7f75f270-17a9-4694-aff3-70c950f9c9b5
解决办法:
直接从cinder数据库中修改该卷的相关信息,然后删掉,相关表:
volume_attachment
volumes
sql 语句:
|
1 |
update volume_attachment set attach_status='detached' where instance_uuid='a95f316f-aeb7-40ce-8887-9145499518fc'\G |
|
1 |
update volumes set status='available', attach_status='detached' where id='7f75f270-17a9-4694-aff3-70c950f9c9b5'\G |
相关代码:
/usr/share/openstack-dashboard/openstack_dashboard/dashboards/project/volumes/tables.py 598 行