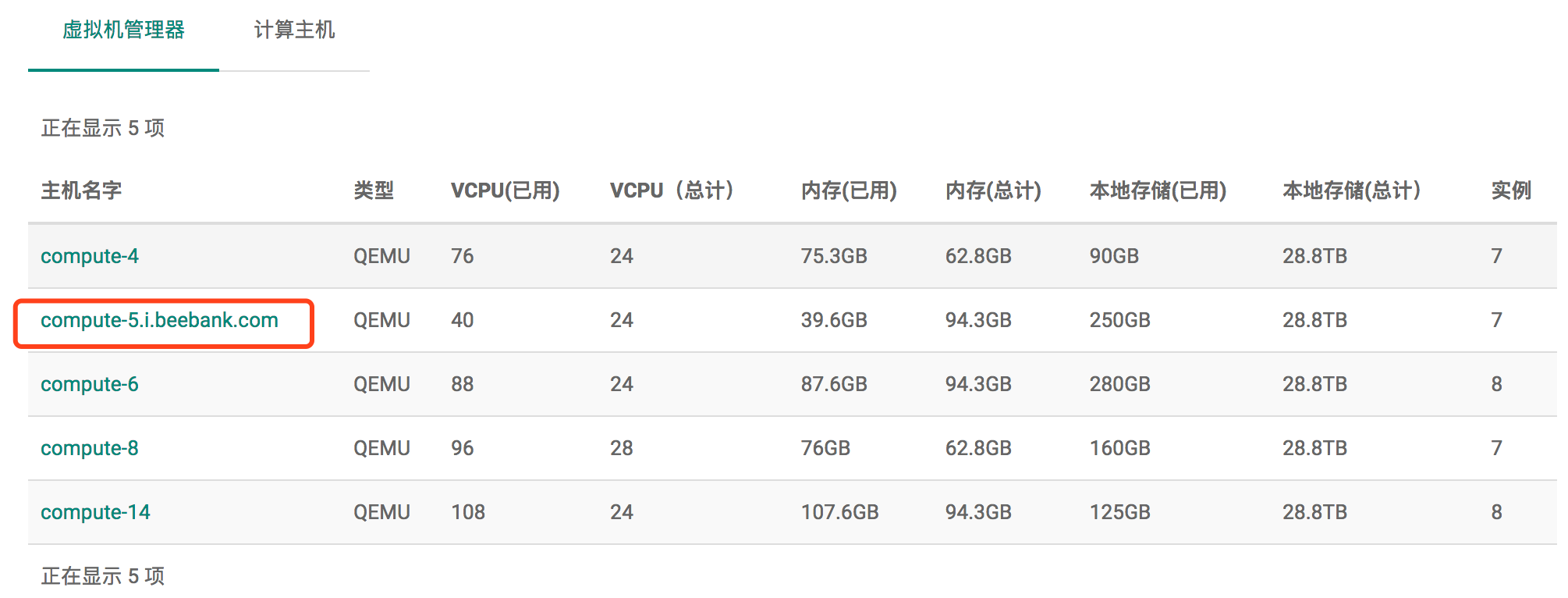
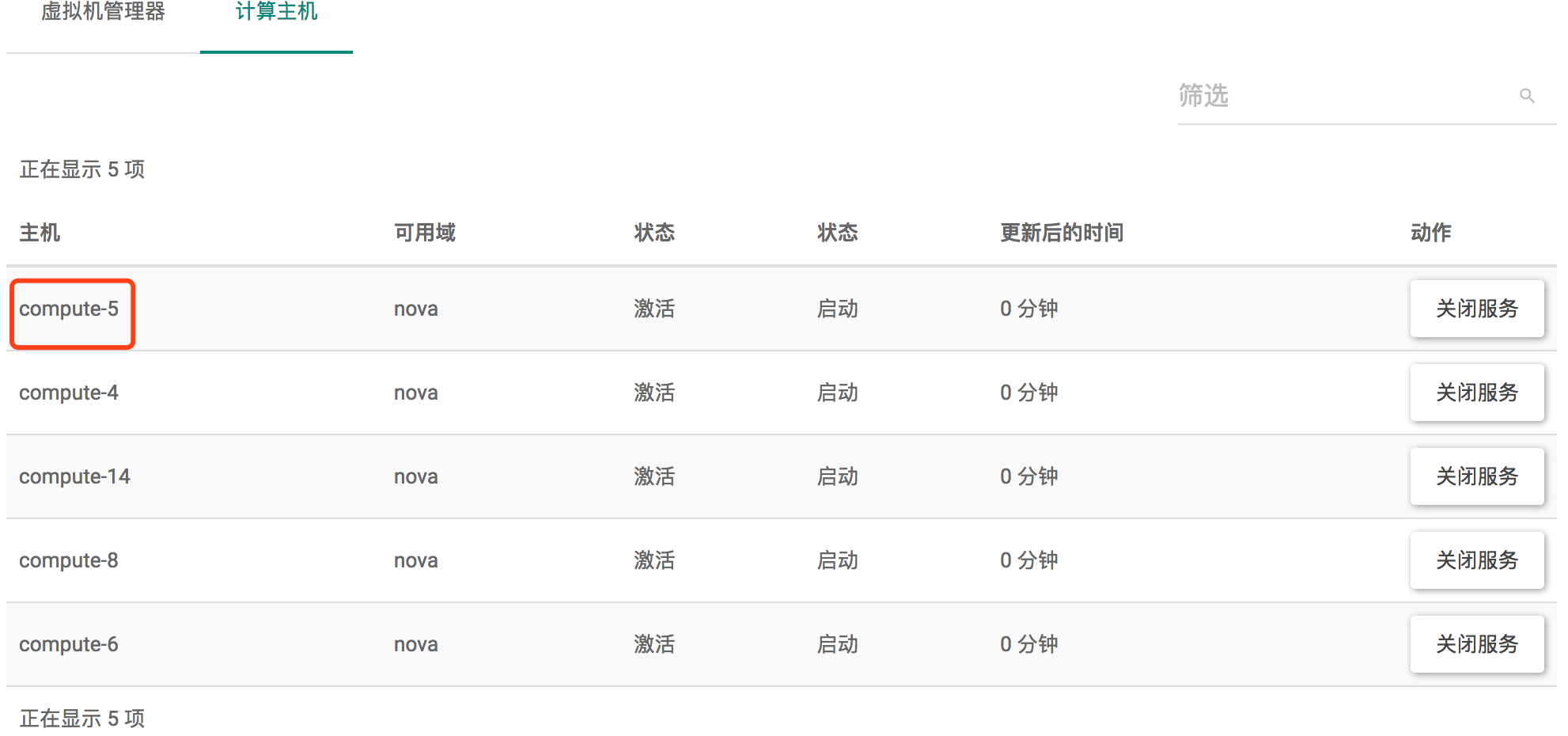
如下图: 虚拟机管理器和计算主机中显示的主机的名字不同,为什么呢?
说明:
虚拟机管理器说的是hypervisor,具体来讲就是libvirtd
主机说的是虚拟机管理器所在的宿主机,就是我们所谓的计算节点
二者的信息都是记录在nova.compute_nodes 表中的,二者都没有唯一约束;
当然,host是不会重复的;特殊情况下hypervisor_hostname 重复是有可能的; 从dashboard来看,节点资源是hypervisor的,而不是host的。
而且也可以存在一个host上有多个虚拟机管理器的情况,一个nova-compute接到任务后,可以通过不同的虚拟机管理器来创建虚拟机
分析:
不同计算节点上使用相同hypervisor_hostname时,hypervisor将拥有了多个机器的资源,那么虚拟机调度时参考hypervisor_hostname的资源的话,虚拟机分配的任务最终会被分配到哪个host上呢?毕竟不同host上都有nova-compute进程的; 另,上报资源时使用的是node的uuid还是host还是hypervisor_hostname?
node的uuid又是如何生成的呢?
hypervisor_hostname 是如何获取到的呢?hypervisor_hostname是不是第一次注册的时候写入后来就不再修改了呢?
主机资源是记录在 nova_api.resource_providers 表中的:
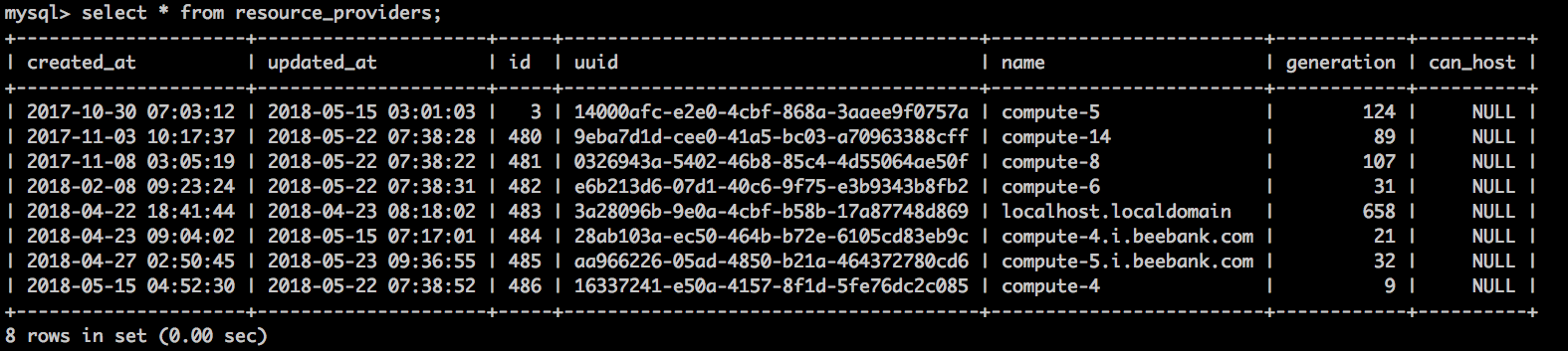
当然,只有nova.compute_nodes 表中记录的uuid才是有效的resource_providers,才会被dashboard显示
为什么node节点的hostname已经修改了,虚拟机管理器中显示的还是以前的名字?
nova-compute.log 中会有错误信息:
|
|
2018-05-07 14:53:44.561 3257 ERROR nova.virt.libvirt.host [req-4cf04c1b-8b6f-4ce9-8832-185720825fbc - - - - -] Hostname has changed from compute-5.i.beebank.com to compute-5. A restart is required to take effect. |
问题: 谁和谁不一致?重启谁?
解决办法:
比较: hostname 和virsh hostname的结果:

二者是不同的,前者的信息是从libvirtd中获取到的,也就是说,libvirtd中显示的主机名和当前的主机名不一致,需要重启libvirtd, 相关逻辑:
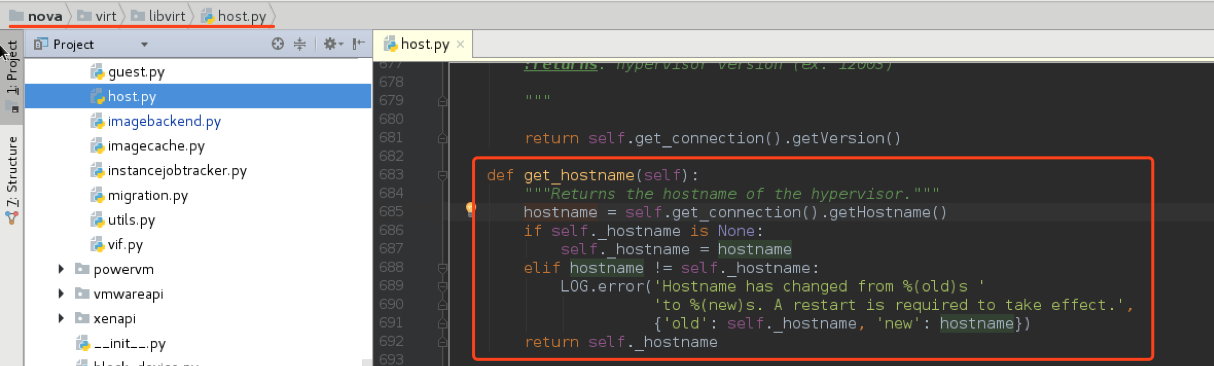
问题:
- 重启libvirtd需要先关闭所有虚拟机吗?
答案: 不需要的,直接重启就行
- 虽然我重启了libvirtd,但是virsh hostname 还是 和 hostname不一样,为什么?
答案: 因为我在/etc/resolv.conf 中配置了search i.beebank.com, libvirtd会自动suffix上search domain的
- 虽然现在virsh hostname 和hostname一致了,但是dashboard中看到的还是原来的,为什么?
答案: 重启一下openstack-nova-compute
总结:
- 确认一下 /etc/resolv.conf 的配置
- systemctl restart libvirtd && systemctl restart openstack-nova-compute
注意:
- 修改了libvirtd的hostname之后,需要去数据库中手动修改相关虚拟机(nova.instances表中)的hypervisor_hostname,否则,就找不到这些机器的hypervisor了,而新的hypervisor下也是没有虚拟机的