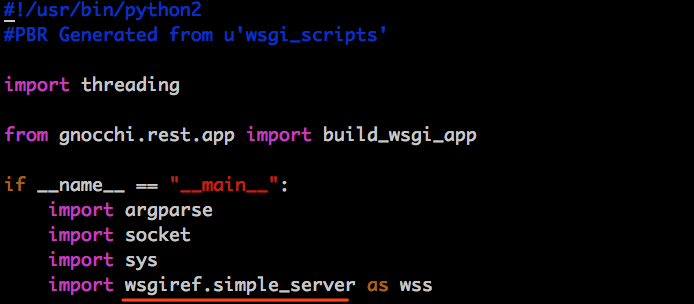
#!/usr/bin/python2
#PBR Generated from u'wsgi_scripts'
import threading
from gnocchi.rest.app import build_wsgi_app
from wsgiref.simple_server import WSGIRequestHandler
class GnocchiWSGIRequestHandler(WSGIRequestHandler):
def address_string(self):
return self.client_address[0]
if __name__ == "__main__":
import argparse
import socket
import sys
import wsgiref.simple_server as wss
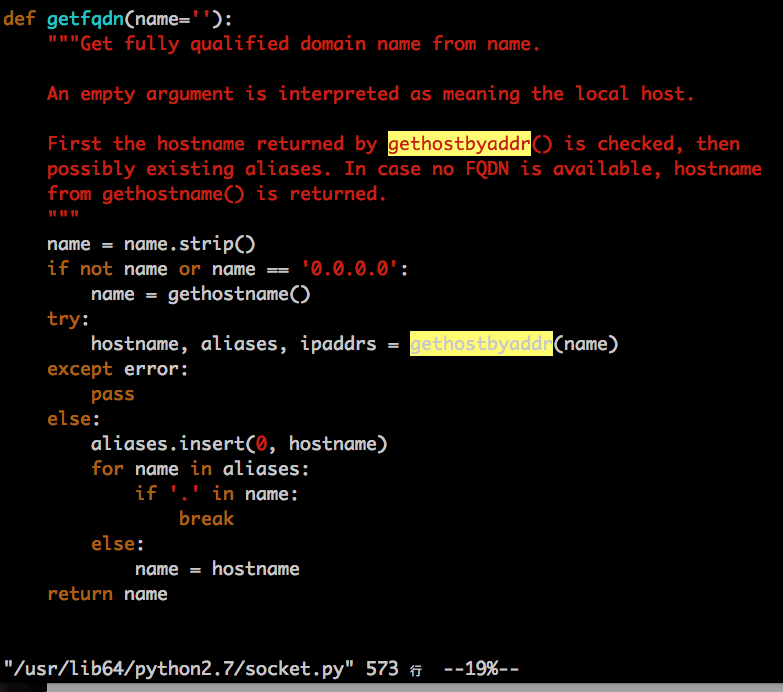
my_ip = socket.gethostbyname(socket.gethostname())
parser = argparse.ArgumentParser(
description=build_wsgi_app.__doc__,
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
usage='%(prog)s [-h] [--port PORT] [--host IP] -- [passed options]')
parser.add_argument('--port', '-p', type=int, default=8041,
help='TCP port to listen on')
parser.add_argument('--host', '-b', default='',
help='IP to bind the server to')
parser.add_argument('args',
nargs=argparse.REMAINDER,
metavar='-- [passed options]',
help="'--' is the separator of the arguments used "
"to start the WSGI server and the arguments passed "
"to the WSGI application.")
args = parser.parse_args()
if args.args:
if args.args[0] == '--':
args.args.pop(0)
else:
parser.error("unrecognized arguments: %s" % ' '.join(args.args))
sys.argv[1:] = args.args
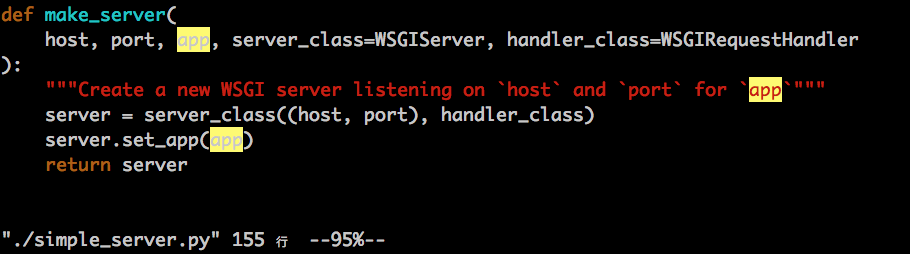
server = wss.make_server(args.host, args.port, build_wsgi_app(), handler_class = GnocchiWSGIRequestHandler)
print("*" * 80)
print("STARTING test server gnocchi.rest.app.build_wsgi_app")
url = "http://%s:%d/" % (server.server_name, server.server_port)
print("Available at %s" % url)
print("DANGER! For testing only, do not use in production")
print("*" * 80)
sys.stdout.flush()
server.serve_forever()
else:
application = None
app_lock = threading.Lock()
with app_lock:
if application is None:
application = build_wsgi_app()